КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Мониторы и их характеристики. Назначение, состав и принцип работы
|
|
|
|
A 6 в
Шины
Шина — это группа проводников, соединяющих различные устройства. Шины можно разделить на группы в соответствии с выполняемыми функциями. Они могут быть внутренними по отношению к процессору и служить для передачи данных в АЛУ и из АЛУ, а могут быть внешними по отношению к процессору и связывать процессор с памятью или устройствами ввода-вывода. Каждый тип шины обладает определенными свойствами, и к каждому из них предъявляются определенные требования. В этом и следующих разделах мы сосредоточимся на шинах, которые связывают центральный процессор с памятью и устройствами ввода-вывода. В следующей главе мы подробно рассмотрим внутренние шины процессора.
Первые персональные компьютеры имели одну внешнюю шину, которая называлась системной шиной. Она состояла из нескольких медных проводов (от 50 до 100), которые встраивались в материнскую плату. На материнской плате находились разъемы на одинаковых расстояниях друг от друга для микросхем памяти и устройств ввода-вывода. Современные персональные компьютеры обычно содержат специальную шину между центральным процессором и памятью и по крайней мере еще одну шину для устройств ввода-вывода. На рис. 3.32 изображена система с одной шиной памяти и одной шиной ввода-вывода.
В литературе шины обычно изображаются в виде жирных стрелок, как показано на этом рисунке. Разница между жирной и нежирной стрелкой небольшая. Когда все биты одного типа, например адресные или информационные, рисуется обычная стрелка. Когда включаются адресные линии, линии данных и управления, используется жирная стрелка.
Хотя разработчики процессоров могут использовать любой тип шины для микросхемы, должны быть введены четкие правила о том, как работает шина, и все
|
|
|
Глава 3. Цифровой логический уровень
 устройства, связанные с шиной, должны подчиняться этим правилам, чтобы платы, которые выпускаются третьими лицами, подходили к системной шине. Эти правила называются протоколом шины. Кроме того, должны существовать определенные технические требования, чтобы платы от третьих производителей подходили к каркасу для печатных плат и имели разъемы, соответствующие материнской плате механически и с точки зрения мощностей, синхронизации и т. д.
устройства, связанные с шиной, должны подчиняться этим правилам, чтобы платы, которые выпускаются третьими лицами, подходили к системной шине. Эти правила называются протоколом шины. Кроме того, должны существовать определенные технические требования, чтобы платы от третьих производителей подходили к каркасу для печатных плат и имели разъемы, соответствующие материнской плате механически и с точки зрения мощностей, синхронизации и т. д.
Микросхема процессора
Рис. 3.32. Компьютерная система с несколькими шинами
Существует ряд широко используемых в компьютерном мире шин. Приведем несколько примеров: Omnibus (PDP-8), Unibus (PDP-1 1), IBM PC (PC/XT), ISA (PC/AT), EISA (80386), MicroChannel (PC/2), PCI (различные персональные компьютеры), SCSI (различные персональные компьютеры и рабочие станции), Nubus (Macintosh), Universal Serial Bus (современные персональные компьютеры), FireWire (бытовая электроника), VME (оборудование в кабинетах физики) и Сатас (физика высоких энергий). Может быть, все стало бы намного проще, если бы все шины, кроме одной, исчезли с поверхности Земли (или кроме двух). К сожалению, стандартизация в этой области кажется маловероятной, и уже вложено слишком много средств во все эти несовместимые системы.
Давайте начнем с того, как работают шины. Некоторые устройства, связанные с шиной, являются активными и могут инициировать передачу информации по шине, тогда как другие являются пассивными и ждут запросов. Активное устройство называется задающим устройством, пассивное — подчиненным устройством. Когда центральный процессор требует от контроллера диска считать или записать блок информации, центральный процессор действует как задающее устройство, а контроллер диска — как подчиненное устройство. Контроллер диска может действовать как задающее устройство, когда он командует памяти принять слова, которые считал с диска. Несколько типичных комбинаций задающего и подчиненного устройств указаны в табл. 3.3. Память ни при каких обстоятельствах не может быть задающим устройством.
|
|
|
Микросхемы процессоров и шины 181
 Таблица 3.3. Примеры задающих и подчиненных устройств Задающее устройство Подчиненное устройство Пример
Таблица 3.3. Примеры задающих и подчиненных устройств Задающее устройство Подчиненное устройство Пример
 Центральный процессор Память Вызов команд и данных
Центральный процессор Память Вызов команд и данных
Центральный процессор Устройство ввода-вывода Инициализация передачи данных
Центральный процессор Сопроцессор Передача команды от процессора
к сопроцессору
Устройство ввода-вывода Память ПДП (прямой доступ к памяти)
Сопроцессор Центральный процессор Вызов сопроцессором операндов из
центрального процессора
 Двоичные сигналы, которые выдают устройства компьютера, часто недостаточно интенсивны, чтобы активизировать шину, особенно если она достаточно длинная и если к ней подсоединено много устройств. По этой причине большинство задающих устройств шины обычно связаны с ней через микросхему, которая называется драйвером шины, по существу являющуюся двоичным усилителем. Сходным образом большинство подчиненных устройств связаны с шиной приемником шины. Для устройств, которые могут быть и задающим, и подчиненным устройством, используется приемопередатчик шины. Эти микросхемы взаимодействия с шиной часто являются устройствами с тремя состояниями, что дает им возможность отсоединяться, когда они не нужны. Иногда они подключаются через открытый коллектор, что дает сходный эффект. Когда одно или несколько устройств на открытом коллекторе требуют доступа к шине в одно и то же время, результатом является булева операция ИЛИ над всеми этими сигналами. Такое соглашение называется монтажным ИЛИ. В большинстве шин одни линии являются устройствами с гремя состояниями, а другие, которым требуется свойство монтажного ИЛИ, — открытым коллектором.
Двоичные сигналы, которые выдают устройства компьютера, часто недостаточно интенсивны, чтобы активизировать шину, особенно если она достаточно длинная и если к ней подсоединено много устройств. По этой причине большинство задающих устройств шины обычно связаны с ней через микросхему, которая называется драйвером шины, по существу являющуюся двоичным усилителем. Сходным образом большинство подчиненных устройств связаны с шиной приемником шины. Для устройств, которые могут быть и задающим, и подчиненным устройством, используется приемопередатчик шины. Эти микросхемы взаимодействия с шиной часто являются устройствами с тремя состояниями, что дает им возможность отсоединяться, когда они не нужны. Иногда они подключаются через открытый коллектор, что дает сходный эффект. Когда одно или несколько устройств на открытом коллекторе требуют доступа к шине в одно и то же время, результатом является булева операция ИЛИ над всеми этими сигналами. Такое соглашение называется монтажным ИЛИ. В большинстве шин одни линии являются устройствами с гремя состояниями, а другие, которым требуется свойство монтажного ИЛИ, — открытым коллектором.
Как и процессор, шина имеет адресные линии, информационные линии и линии управления. Тем не менее между выводами процессора и сигналами шины может и не быть взаимно однозначного соответствия. Например, некоторые процессоры содержат три вывода, которые выдают сигнал чтения из памяти или записи в память, или чтения устройства ввода-вывода, или записи на устройство ввода-вывода, или какой-либо другой операции. Обычная шина может содержать одну линию для чтения из памяти, вторую линию для записи в память, третью — для чтения устройства ввода-вывода, четвертую — для записи на устройство ввода-вывода и т. д. Микросхема-декодер должна тогда связывать данный процессор с такой шиной, чтобы преобразовывать 3-битный кодированный сигнал в отдельные сигналы, которые могут управлять линиями шины.
|
|
|
Разработка шин и принципы действия шин — это достаточно сложные вопросы, и по этому поводу написан ряд книг [128,135,136]. Принципиальными вопросами в разработке являются ширина шины, синхронизация шины, арбитраж шины и функционирование шины. Все эти параметры существенно влияют на скорость и пропускную способность шины. В следующих четырех разделах мы рассмотрим каждый из них.
Глава 3. Цифровой логический уровень

Ширина шины
Ширина шины — самый очевидный параметр при разработке. Чем больше адресных линий содержит шина, тем к большему объему памяти может обращаться процессор. Если шина содержит п адресных линий, тогда процессор может использовать ее для обращения к 2" различным ячейкам памяти. Для памяти большой емкости необходимо много адресных линий. Это звучит достаточно просто.
Проблема заключается в том, что для широких шин требуется больше проводов, чем для узких. Они занимают больше физического пространства (например, на материнской плате), и для них нужны разъемы большего размера. Все эти факторы делают шину дорогостоящей. Следовательно, необходим компромисс между максимальным размером памяти и стоимостью системы. Система с шиной, содержащей 64 адресные линии, и памятью в 232 байт будет стоить дороже, чем система с шиной, содержащей 32 адресные линии, и такой же памятью в 232байт. Дальнейшее расширение не бесплатное.
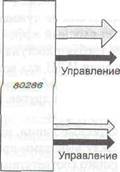
Многие разработчики систем недальновидны, что приводит к неприятным последствиям. Первая модель IBM PC содержала процессор 8088 и 20-битную адресную шину (рас. 3.33, а). Шина позволяла обращаться к 1 Мбайт памяти.
|
|
|

|
|

|
| 20-битный адрес |
| 4-битный адрес |

| Управление |
20-битный адрес
80366
20-битный адрес
Управление 4-битный адрес

 Управление 8-битный адрес
Управление 8-битный адрес
Управление
Рис. 3.33. Расширение адресной шины с течением времени
Когда появился следующий процессор (80286), Intel решил увеличить адресное пространство до 16 Мбайт, поэтому пришлось добавить еще 4 линии (не нарушая изначальные 20 по причинам совместимости с более старыми версиями), как показано на рис. 3.33, б. К сожалению, пришлось также добавить линии управления для новых адресных линий. Когда появился процессор 80386, было добавлено еще 8 адресных линий и, естественно, несколько линий управления, как показано на рис. 3.33, в. В результате получилась шина EISA. Однако было бы лучше, если бы с самого начала имелось 32 линии.
С течением времени увеличивается не только число адресных линий, но и число информационных линий. Хотя это происходит по несколько другой причине. Можно увеличить пропускную способность шины двумя способами: сократить время цикла шины (сделать большее количество передач в секунду) или увели-
Микросхемы процессоров и шины 183
 чить ширину шины данных (то есть увеличить количество битов за одну передачу). Можно повысить скорость работы шины, но сделать это довольно сложно, поскольку сигналы на разных линиях передаются с разной скоростью (это явление называется перекосом шины). Чем быстрее работает шина, тем больше перекос.
чить ширину шины данных (то есть увеличить количество битов за одну передачу). Можно повысить скорость работы шины, но сделать это довольно сложно, поскольку сигналы на разных линиях передаются с разной скоростью (это явление называется перекосом шины). Чем быстрее работает шина, тем больше перекос.
При увеличении скорости работы шины возникает еще одна проблема: в этом случае она не будет совместимой с более старыми версиями. Старые платы, разработанные для более медленной шины, не могут работать с новой. Такая ситуация невыгодна для владельцев и производителей старых плат. Поэтому обычно для увеличения производительности просто добавляются новые линии, как показано на рис. 3,33. Как вы понимаете, в этом тоже есть свои недостатки. IBM PC и его последователи, например, начали с 8 информационных линий, затем перешли к 16, а затем к 32, и все это в одной и той же шине.
Чтобы обойти эту проблему, разработчики иногда отдают предпочтение мультиплексной шине. В этой шине нет разделения на адресные и информационные линии. В ней может быть, например, 32 линии и для адресов, и для данных. Сначала эти линии используются для адресов. Затем они используются для данных. Чтобы записать информацию в память, нужно сначала передавать в память адрес, а затем данные. В случае с отдельными линиями адреса и данные могут передаваться вместе. Объединение линий сокращает ширину и стоимость шины, но система работает при этом медленнее. Поэтому разработчикам приходится взвешивать все за и против, прежде чем сделать выбор.
Синхронизация шины
Шины можно разделить на две категории в зависимости от их синхронизации. Синхронная шина содержит линию, которая запускается кварцевым генератором. Сигнал на этой линии представляет собой меандр с частотой обычно от 5 до 100 МГц. Любое действие шины занимает целое число так называемых циклов шины. Асинхронная шина не содержит задающего генератора. Циклы шины могут быть любой требуемой длины и необязательно одинаковы по отношению ко всем парам устройств. Ниже мы рассмотрим каждый тип шины отдельно.
Синхронные шины
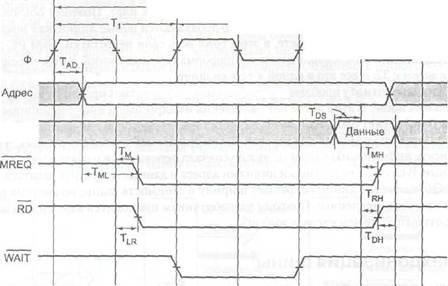
В качестве примера того, как работает асинхронная шина, рассмотрим временную диаграмму на рис. 3.34. В этом примере мы будем использовать задающий генератор на 40 МГц, который дает цикл шины в 25 не. Хотя может показаться, что шина работает медленно по сравнению с процессорами на 500 МГц и выше, не многие современные шины работают быстрее. Например, шина ISA (она встроена во все персональные компьютеры с процессором Intel) работает с частотой 8,33 МГц, и даже популярная шина PCI — с частотой 33 МГц или 66 МГц. Причины такой низкой скорости современных шин были даны выше: такие технические проблемы, как перекос шины и требование совместимости.
В нашем примере мы предполагаем, что считывание информации из памяти занимает 40 не с того момента, как адрес стал постоянным. Как мы скоро увидим, понадобится три цикла шины, чтобы считать одно слово. Первый цикл начинается
Глава 3. Цифровой логический уровень
на нарастающем фронте отрезка Ть а третий заканчивается на нарастающем фронте отрезка Т3, как показано на рис. 3.34. Отметим, что ни один из нарастающих и задних фронтов не нарисован вертикально, потому что ни один электрический сигнал не может изменять свое значение за нулевое время. В нашем примере мы предполагаем, что для изменения сигнала требуется 1 не. Генератор и линии ADDRESS, DATA, MREQ, RD, WAIT показаны в том же масштабе времени.
| Г |
| Адрес памяти для считывания |
| Данные |
 Цикл чтения с 1 периодом ожидания
Цикл чтения с 1 периодом ожидания
,Т2---------------------
Время —*-Рис. 3.34. Временная диаграмма процесса считывания на синхронной шине
Начало Ti определяется нарастающим фронтом генератора. За часть времени Т, центральный процессор помещает адрес нужного слово на адресные линии. Поскольку адрес представляет собой не одно значение (в отличие от генератора), мы не можем показать его в виде одной линии на схеме. Вместо этого мы показали его в виде двух линий с пересечениями там, где этот адрес меняется. Серый цвет на схеме показывает, что в этот момент не важно, какое значение принял сигнал. Используя то же соглашение, мы видим, что содержание линий данных не имеет значения до отрезка Т3.
После того как у адресных линий появляется возможность приобрести новое значение, устанавливаются сигналы MREQ и RD. Первый указывает, что осуществляется доступ к памяти, а не к устройству ввода-вывода, а второй — что осуществляется чтение, а не запись. Поскольку считывание информации из памяти занимает 40 не после того, как адрес стал постоянным (часть первого цикла), память не может передать требуемые данные за период Т2. Чтобы центральный процессор не ожидал поступления данных, память устанавливает линию WAIT в начале отрезка Т2. Это действие вводит периоды ожидания (дополнительные циклы шины), до тех пор пока память не сбросит сигнал WATT. В нашем примере вводится один период ожидания (Т2), поскольку память работает слишком медленно. В начале
 Микросхемы процессоров и шины 185
Микросхемы процессоров и шины 185
 Тз, когда есть уверенность в том, что намять получит данные в течение текущего цикла, сигнал WAI T сбрасывается.
Тз, когда есть уверенность в том, что намять получит данные в течение текущего цикла, сигнал WAI T сбрасывается.
■ Во время первой половины Т3 память помещает данные на информационные линии. На заднем фронте Т3 центральный процессор стробирует (то есть считывает) информационные линии, сохраняя их значения во внутреннем регистре. Считав данные, центральный процессор сбрасывает сигналы MREQ и RD. В случае необходимости на следующем нарастающем фронте может начаться еще один цикл памяти. Далее проясняется значение восьми символов на временной диаграмме (см. рис. 3.34 и табл. 3.4). TAD, например, — это временной интервал между нарастающим фронтом Tj и установкой адресных линий. В соответствии с требованиями синхронизации Tad ^ 11 не. Значит, производитель процессора гарантирует, что во время любого цикла считывания центральный процессор будет выдавать требуемый адрес в пределах 11 не от середины нарастающего фронта TV
Таблица 3.4. Некоторые временные характеристики процесса считывания на синхронной шине


 Символ Значение Минимум, не Максимум, не
Символ Значение Минимум, не Максимум, не
 Тдо Задержка выдачи адреса 11
Тдо Задержка выдачи адреса 11
TML Промежуток между стабилиз ацией 6
адреса и установкой сигнала MREQ
Тм Промежуток между задним фронтом 8
синхронизирующего сигнала в цикле Ti и установкой сигнала MREO
TrL Промежуток между задним фронтом 8
синхронизирующего сигнала в цикле Т(и установкой сигнала RD
TDS Период передачи данных до заднего 5
фронта синхронизирующего сигнала
Тш Промежуток между задним фронтом 8
синхронизирующего_сигнала в цикле Т3 и сбросом сигнала MREQ
Тин Промежуток между задним фронтом 8
синхронизирующего_сигнала в цикле Т3 и сбросом сигнала RD
Тон Период продолжения передачи данных О
с момента сброса сигнала RD
Условия синхронизации также требуют, чтобы данные поступали на информационные линии по крайней мере за 5 не (Tcs) до заднего фронта Тз, чтобы дать данным время установиться до того, как процессор стробирует их. Сочетание ограничений на Тл0 и TDs означает, что в худшем случае в распоряжении памяти будет только 62,5-И-5=46,5 не с момента появления адреса и до момента, когда нужно выдавать данные. Поскольку достаточно 40 не, память даже в самом худшем случае может всегда ответить за период Тэ. Если памяти для считывания требуется 50 не, то необходимо ввести второй период ожидания, и тогда память ответит в течение Т3.
186 Глава 3. Цифровой логический уровень
 Требования синхронизации гарантируют, что адрес будет установлен по крайней мере за б не до того, как появится сигнал MREQ. Это время может быть важно в том случае, если MREQ запускает выбор элемента памяти, поскольку некоторые типы памяти требуют некоторого времени на установку адреса до выбора элемента памяти. Ясно, что разработчику системы не следует выбирать микросхему памяти, на установку которой нужно 10 не.
Требования синхронизации гарантируют, что адрес будет установлен по крайней мере за б не до того, как появится сигнал MREQ. Это время может быть важно в том случае, если MREQ запускает выбор элемента памяти, поскольку некоторые типы памяти требуют некоторого времени на установку адреса до выбора элемента памяти. Ясно, что разработчику системы не следует выбирать микросхему памяти, на установку которой нужно 10 не.
 Ограничения на Тм и Ты. означают, что WREQ и RD будут установлены в пределах 8 не от заднего фронта TV В худшем случае у микросхемы памяти после установки MREQ и R~D останется всего 25+25-8-5=37 не на передачу данных по шине. Это ограничение дополнительно по отношению к интервалу в 40 не и не зависит от него.
Ограничения на Тм и Ты. означают, что WREQ и RD будут установлены в пределах 8 не от заднего фронта TV В худшем случае у микросхемы памяти после установки MREQ и R~D останется всего 25+25-8-5=37 не на передачу данных по шине. Это ограничение дополнительно по отношению к интервалу в 40 не и не зависит от него.
Тми и Trh определяют, сколько времени требуется на отмену сигналов MREQ и RD после того, как данные стробированы. Наконец, Тон определяет, сколько времени память должна держать данные на шине после снятия сигнала R0. В нашем примере при данном процессоре память может удалить данные с шины, как только сбрасывается сигнал RD; при других процессорах, однако, данные могут сохраняться еще некоторое время.
Необходимо подчеркнуть, что наш пример представляет собой сильно упрощенную версию реальных временных ограничений. В действительности должно определяться гораздо больше таких ограничений. Тем не менее этот пример наглядно демонстрирует, как работает синхронная шина.
Отметим, что сигналы управления могут задаваться или с помощью низкого, или с помощью высокого напряжения. Что является более удобным в каждом конкретном случае, должен решать разработчик, хотя, по существу, выбор произволен.
Введение
Из сведений о ПК известно, что монитор относится к устройству вывода. Персональный компьютер может без особых проблем работать и без принтера, то использование РС без монитора даже трудно себе представить. Поэтому устройства вывода за исключением монитора обозначают как вторичные.
|
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 428; Нарушение авторских прав?; Мы поможем в написании вашей работы!