КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Модели бинарного выбора
|
|
|
|
Для наглядности будем рассматривать модели бинарного выбора на примере покупки семьей автомобиля. Будем считать, что зависимая переменная у = 1, если в течение исследуемого периода времени семья купила автомобиль, и у = 0 в противном случае. Ясно, что на решение о покупке автомобиля влияют самые разные факторы: доход семьи, количество ее членов, их возраст, место проживания семьи и т.д. Набор этих характеристик можно представить вектором 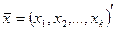 (независимые переменные). Будем полагать также, что на решение семьи влияют также неучтенные случайные факторы (ошибки). Выдвигая различные предположения о характере зависимости у от х, будем получать разные модели. Мы рассмотрим три модели: линейную модель вероятности и так называемые probit- и logit- модели.
(независимые переменные). Будем полагать также, что на решение семьи влияют также неучтенные случайные факторы (ошибки). Выдвигая различные предположения о характере зависимости у от х, будем получать разные модели. Мы рассмотрим три модели: линейную модель вероятности и так называемые probit- и logit- модели.
2.1. Линейная модель вероятности
Воспользуемся обычной линейной моделью регрессии:

где t – номер наблюдения (семьи),
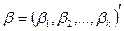 – набор неизвестных параметров (коэффициентов);
– набор неизвестных параметров (коэффициентов);
εt – случайная ошибка.
Так как yt принимает значения 0 или 1 и М(εt) = 0, то
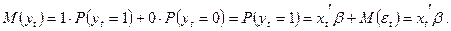
Таким образом, модель (1) может быть записана в виде
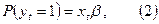
поэтому ее называют линейной моделью вероятности.
Отметим некоторые особенности этой модели, наличие которых не позволяет успешно применять МНК для оценивания коэффициентов b и прогнозирования.
Из (1) следует, что ошибка ε в каждом наблюдении может принимать только два значения: 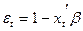 с вероятностью P(yt = 1) и
с вероятностью P(yt = 1) и 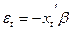 с вероятностью 1 – P(yt = 1). Это не позволяет считать ошибку нормально распределенной. Далее, непосредственным вычислением получаем, что дисперсия ошибки
с вероятностью 1 – P(yt = 1). Это не позволяет считать ошибку нормально распределенной. Далее, непосредственным вычислением получаем, что дисперсия ошибки
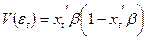
зависит от xt, т.е. модель (1) гетероскедастична. Как известно, оценки коэффициентов b, полученные обычным МНК, в этом случае не являются эффективными, и желательно пользоваться обобщенным МНК.
Самым серьезным недостатком линейной модели вероятности является тот факт, что прогнозные значения 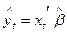 , которые по смыслу модели есть прогнозные значения вероятности P(yt = 1), могут лежать вне отрезка [0; 1], что не поддается разумной интерпретации. Это существенно ограничивает область применимости линейной модели вероятности. Ее целесообразно использовать при большом числе наблюдений и при достаточно точной спецификации модели, а также как инструмент первичной обработки данных для сравнения с результатами, получаемые более тонкими методами.
, которые по смыслу модели есть прогнозные значения вероятности P(yt = 1), могут лежать вне отрезка [0; 1], что не поддается разумной интерпретации. Это существенно ограничивает область применимости линейной модели вероятности. Ее целесообразно использовать при большом числе наблюдений и при достаточно точной спецификации модели, а также как инструмент первичной обработки данных для сравнения с результатами, получаемые более тонкими методами.
|
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 778; Нарушение авторских прав?; Мы поможем в написании вашей работы!