КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Модели архитектур совместно используемой памяти
|
|
|
|
Модели архитектуры памяти вычислительных систем
В рамках как совместно используемой, так и распределенной памяти реализуется несколько моделей архитектур системы памяти.

Рис. 2.2. Классификация моделей архитектур памяти вычислительных систем
На рис. 2.2 приведена классификация таких моделей, применяемых в вы-числительных системах класса SIMD или MIMD.
В системах с общей памятью все процессоры имеют равные возможности по доступу к единому адресному пространству. Единая память может быть построена как одноблочная или по модульному принципу.
Вычислительные системы с общей памятью, где доступ любого процессора к памяти производится единообразно и занимает одинаковое время, называются системами с однородным доступом к памяти и обозначаются аббревиатурой UMA (Uniform Memory Access). Это наиболее распространенная архитектура памяти параллельных ВС с общей памятью.
Технически UMA-системы предполагают наличие узла, соединяющего каждый из n процессоров с каждым из m модулей памяти. Простейший путь построения таких ВС – объединение нескольких процессоров (Pi) с единой памятью (Mp) посредством общей шины (рис. 2.3, а). В этом случае в каждый
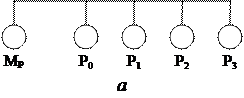
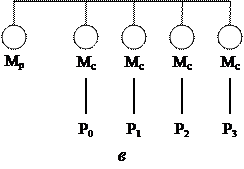 |
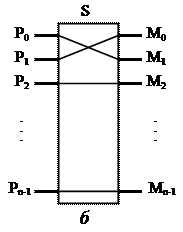
Рис. 2.3. Общая память: а – объединение процессоров с помощью шины; б – многопроцессорная ВС с общей памятью, состоящей из отдельных модулей;
в – система с локальными кэшами.
момент времени обмен по шине может вести только один из процессоров, то есть процессоры должны соперничать за доступ к шине. Когда процессор Pi выбирает из памяти команду, остальные процессоры Pj (i≠ j) должны ожидать, пока шина освободится. Если в систему входят только два процессора, они в состоянии работать с производительностью, близкой к максимальной, поскольку их доступ к шине можно чередовать: пока один процессор декодирует и выполняет команду, другой вправе использовать шину для выборки из памяти следующей команды. Однако когда добавляется третий процессор, производительность начинает па-дать. При наличии на шине десяти процессоров кривая быстродействия шины (рис. 2.4) становится горизонтальной, так что добавление 11-го процессора уже не дает повышения производительности. Нижняя кривая на этом рисунке иллю-стрирует тот факт, что память и шина обладают фиксированной пропускной способностью, определяемой комбинацией длительности цикла памяти и про-токолом шины, и в многопроцессорной системе с общей шиной эта пропускная способность распределена между несколькими процессорами. Если длительность цикла процессора больше по сравнению с циклом памяти, то к шине можно подключать много процессоров. Однако фактически процессор обычно намного быстрее памяти, поэтому данная схема широкого применения не находит.
|
|
|
 |
Рис. 2.4. Производительность системы как функция от числа процессоров на шине.
Альтернативный способ построения многопроцессорной ВС с общей па-мятью на основе UMA показан на рис. 2.3, б. Здесь шина заменена коммутатором, маршрутизирующим запросы процессора к одному из нескольких модулей памя-ти. Несмотря на то что имеется несколько модулей памяти, все они входят в единое виртуальное адресное пространство. Преимущество такого подхода в том, что коммутатор в состоянии параллельно обслуживать несколько запросов. Каж-дый процессор может быть соединен со своим модулем памяти и иметь доступ к нему на максимально допустимой скорости. Соперничество между процессорами может возникнуть при попытке одновременного доступа к одному и тому же модулю памяти. В этом случае доступ получает только один процессор, а прочие – блокируются.
|
|
|
Однако архитектура UMA не очень хорошо масштабируется. Наиболее рас-пространенные системы содержат 4 – 8 процессоров, значительно реже 32 – 64 процессора. Кроме того, подобные системы не являются отказоустойчивыми, по-скольку отказ одного процессора или модуля памяти влечет отказ всей ВС.
Другим подходом к построению ВС с общей памятью является неодно-родный доступ к памяти, обозначаемый как NUMA (Non-Uniform Memory Access). Здесь по-прежнему фигурирует единое адресное пространство, но каждый процессор имеет локальную память. Доступ процессора к собственной локальной памяти производится напрямую, что намного быстрее, чем доступ к удаленной памяти через коммутатор или сеть. Такая система может быть дополнена глобальной памятью, тогда локальные запоминающие устройства играют роль быстрой кэш-памяти для глобальной памяти. Подобная схема улучшает производительность ВС, но не в состоянии неограниченно отсрочить выравнивание кривой производительности. При наличии у каждого процессора локальной кэш-памяти (рис. 2.3, в) существует высокая вероятность (р > 0,9) того, что нужные команда или данные уже находятся в локальной памяти. Разумная вероятность попадания в локальную память существенно уменьшает число обра-щений процессора к глобальной памяти, что ведет к повышению эффективности. Место излома кривой производительности (верхняя кривая на рис. 2.4), соот-ветствующее точке, в которой добавление процессоров еще остается эффективным, теперь перемещается в область 20 процессоров, а точка, где кривая становится горизонтальной, – в область 30 процессоров.
В рамках концепции NUMA реализуется несколько различных подходов, обозначаемых аббревиатурами COMA, CC-NUMA и NCC-NUMA.
В архитектуре только с кэш-памятью (COMA, Cache Only Memory Architecture) локальная память каждого процессора построена как большая кэш-память для быстрого доступа со стороны «своего» процессора. Кэши всех процессоров в совокупности рассматриваются как глобальная память системы. Собственно глобальная память отсутствует. Принципиальная особенность кон-цепции COMA выражается в динамике. Здесь данные не привязаны статически к определенному модулю памяти и не имеют уникального адреса, остающегося неизменным в течение всего времени существования переменной. В архитектуре COMA данные переносятся в кэш-память того процессора, который последним их запросил; при этом переменная не фиксирована уникальным адресом и в каждый момент времени может размещаться в любой физической ячейке. Перенос данных из одного локального кэша в другой не требует участия в этом процессе операционной системы, но подразумевает сложную и дорогостоящую аппаратуру управления памятью. Для организации такого режима используются каталоги кэшей. Последняя копия элемента данных никогда из кэш-памяти не удаляется.
|
|
|
Поскольку в архитектуре COMA данные перемещаются в локальную кэш-память процессора-владельца, такие ВС в плане производительности обладают существенным преимуществом над другими архитектурами NUMA. С другой стороны, если единственная переменная или две различные переменные, храня-щиеся в одной строке одного и того же кэша, требуются двум процессорам, эта строка кэша должна перемещаться между процессорами туда и обратно при каждом доступе к данным. Такие эффекты могут зависеть от деталей распре-деления памяти и приводить к непредсказуемым ситуациям.
Модель кэш-когерентного доступа к неоднородной памяти (СС-NUMA, Cache Coherent Non-Uniform Memory Architecture) принципиально отличается от модели COMA. В системе CC-NUMA используется не кэш-память, а обычная физически распределенная память. Не происходит никакого копирования страниц или данных между ячейками памяти. Нет никакой программно реализованной передачи сообщений. Существует просто одна карта памяти с частями, физи-чески связанными медным кабелем, и «умные» аппаратные средства. Аппаратно реализованная кэш-когерентность означает, что не требуется какого-либо прог-раммного обеспечения для сохранения множества копий обновленных данных или их передачи. Со всем этим справляется аппаратный уровень. Доступ к локальным модулям памяти в разных узлах системы может производиться одновременно и происходит быстрее, чем к удаленным модулям памяти.
|
|
|
Отличие модели с кэш-некогерентным доступом к неоднородной памяти (NСС-NUMA, Non-Cache Coherent Non-Uniform Memory Architecture) от CC-NUMA очевидно из названия. Архитектура памяти предполагает единое адресное пространство, но не обеспечивает согласованности глобальных данных на аппа-ратном уровне. Управление использованием таких данных полностью возлагается на программное обеспечение (приложения или компиляторы).
ВС с общей памятью, построенные по схеме NUMA, называются архи-тектурами с виртуальной общей памятью (virtual shared memory architectures).
|
|
|
|
|
Дата добавления: 2014-01-20; Просмотров: 1040; Нарушение авторских прав?; Мы поможем в написании вашей работы!