КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Независимость данных
Возможность введения стандартизации
Возможность балансировки противоречивых требований
Зная общие требования всего предприятия (а не требования каждого отдельного пользователя), АБД (опять же, в соответствии с указаниями администратора данных) может структурировать базу данных таким образом, чтобы обслуживание было наилучшим для всего предприятия. Например, он может выбрать такое физическое представление данных во вторичной памяти, которое обеспечит быстрый доступ к информации для наиболее важных приложений (возможно, с потерей производительности для некоторых других приложений).
Благодаря централизованному управлению базой данных АБД (по указаниям администратора данных) может обеспечить соблюдение всех подходящих стандартов, регламентирующих представление данных в системе. Стандарты бывают частными, корпоративными, ведомственными, промышленными, национальными и интернациональными. Стандартизация представления данных очень важна с точки зрения обмена и пересылки данных между системами. Стандарты именования и документирования данных важны в отношении их совместного использования и в отношении их углубленного понимания.
Большинство перечисленных преимуществ достаточно очевидно. Однако есть дно преимущество, которое необходимо добавить к этому списку и которое не очевидно (хотя косвенно и охватывает несколько преимуществ). Речь идет об обеспечении независимости данных. (Строго говоря, это, скорее, цель создания систем баз данных, а не обязательное их преимущество).
Независимость данных может быть реализована на двух уровнях: физическом и логическом. Однако сейчас нас интересует только физическая независимость. Поэтому неуточненный термин "независимость данных" мы пока будем понимать лишь как физическую независимость данных.
Замечание. Необходимо отметить, что термин "независимость данных" несовсем подходящий (он не отражает достаточно точно сущность происходящего). Но поскольку именно этот термин традиционно используется, мы последуем общему правилу.
Проще всего разобраться в понятии независимости данных на примере его противоположности. Приложения, реализованные в старых системах ("дореляционные" или созданные даже до появления систем баз данных), в той или иной мере зависимы от данных. Это означает, что способ организации данных во вторичной памяти и способ доступа к ним диктуются требованиями приложения. Более того, сведения об организации данных и способе доступа к ним встроены в саму логику и программный код приложения.
Пример. Предположим, у нас есть приложение, обрабатывающее файл EMPLOYEE. Исходя из соображений эффективности примем, что этот файл проиндексирован по полю имени работника (NAME). В старых системах в этом приложении учитывалось бы, что такой индекс существует, и что последовательность записей в файле определена данным индексом. На основе этих сведений была бы построена вся внутренняя структура приложения. В частности, избранный способ реализации процедур доступа и обработки исключительных ситуаций в значительной степени зависел бы от особенностей интерфейса, предоставляемого программами управления данными.
Приложения, подобные описанному в этом примере, мы называем зависимыми от данных, так как невозможно изменить физическое представление (т.е. способ физического размещения данных во вторичной памяти) или метод доступа (т.е. конкретный способ доступа к данным), не изменив самого приложения (возможно, радикально). Например, невозможно заменить индексированный файл в нашем примере хешированным файлом, не внеся в приложение значительных изменений. Более того, изменению в подобных случаях подлежат те части приложения, которые взаимодействуют с программами управления данными. Трудности, возникающие при этом, не имеют никакого отношения к проблеме, для решения которой было написано данное приложение; это трудности, внесенные используемой структурой интерфейса управления данными.
Однако для системы баз данных крайне нежелательно, чтобы приложение зависело от данных, и на то есть, по меньшей мере, две причины.
1. Для разных приложений требуются разные представления одних и тех же данных. Например, предположим, что до перехода к интегрированной базе данных предприятие имело два приложения, А и В. Каждое из них работало с собственным файлом, содержащим поле "баланс заказчика". Предположим также, что приложение А записывает значение этого поля в десятичном формате, а приложение В — в двоичном. Эти два файла все еще можно интегрировать, а существующую избыточность устранить, если в СУБД есть возможность выполнить все необходимые преобразования между форматом представления данных, (формат представления может быть десятичным, двоичным или любым другим) и форматом, необходимым для приложения. Например, если принято решение сохранять значения поля в десятичном формате, каждое обращение к приложению В потребует преобразования значений в двоичный формат или из двоичного формата.
Это довольно простой пример различий, которые могут существовать в системе баз данных между формой представления данных в приложении и формой их физического хранения.
2. Администратор базы данных должен иметь неограниченные возможности изменять физическое представление или метод доступа к данным в случае изменения требований, причем без необходимости модифицировать существующие приложения. Например, к базе данных могут быть добавлены новые виды данных, на предприятии могут быть приняты новые стандарты, могут быть изменены приоритеты приложений (а, следовательно, и связанные с ними требования к производительности), могут появиться новые типы запоминающих устройств и т.д. Если приложения зависят от данных, то перечисленные изменения потребуют внесения изменений в программы, а значит, дополнительных усилий программистов, которые можно было бы направить на создание новых приложений. До сих пор подобные проблемы не являются исключением.
Таким образом, обеспечение независимости данных — важнейшая цель создания систем баз данных. Независимость данных можно определить как иммунитет приложений к изменениям в физическом представлении данных и в методах доступа к ним, а это означает, что рассматриваемые приложения не зависят от любых конкретных способов физического представления информации или выбранных методов доступа к ним.
ГЛАВА 3. ИНФОЛОГИЧЕСКАЯ МОДЕЛЬ ДАННЫХ «СУЩНОСТЬ-СВЯЗЬ»
Объединяя частные представления о содержимом базы данных, полученные в результате опроса пользователей, и свои представления о данных, которые могут потребоваться в будущих приложениях, АБД сначала создает обобщенное неформальное описание создаваемой базы данных. Это описание, выполненное с использованием естественного языка, математических формул, таблиц, графиков и других средств, понятных всем людям, работающих над проектированием базы данных, называют инфологической моделью данных (Рис. 2.).
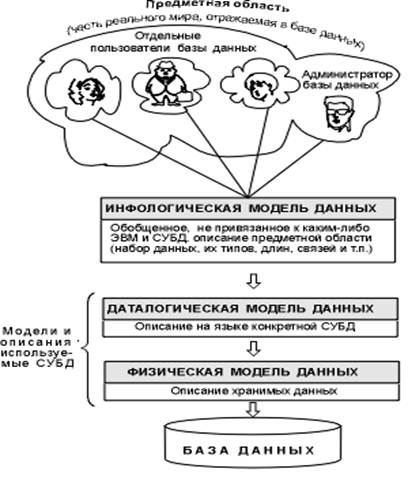
Рис. 2. Уровни моделей данных
Такая человеко-ориентированная модель полностью независима от физических параметров среды хранения данных. В конце концов, этой средой может быть память человека, а не ЭВМ. Поэтому инфологическая модель не должна изменяться до тех пор, пока какие-то изменения в реальном мире не потребуют изменения в ней некоторого определения, чтобы эта модель продолжала отражать предметную область.
Остальные модели, показанные на рис. 2.1, являются компьютеро-ориентированными. С их помощью СУБД дает возможность программам и пользователям осуществлять доступ к хранимым данным лишь по их именам, не заботясь о физическом расположении этих данных. Нужные данные отыскиваются СУБД на внешних запоминающих устройствах по физической модели данных.
Так как указанный доступ осуществляется с помощью конкретной СУБД, то модели должны быть описаны на языке описания данных этой СУБД. Такое описание, создаваемое АБД по инфологической модели данных, называют даталогической моделью данных.
Трехуровневая архитектура (инфологический, даталогический и физический уровни) позволяет обеспечить независимость хранимых данных от использующих их программ. АБД может при необходимости переписать хранимые данные на другие носители информации и (или) реорганизовать их физическую структуру, изменив лишь физическую модель данных. АБД может подключить к системе любое число новых пользователей (новых приложений), дополнив, если надо, даталогическую модель. Указанные изменения физической и даталогической моделей не будут замечены существующими пользователями системы (окажутся "прозрачными" для них), так же как не будут замечены и новые пользователи. Следовательно, независимость данных обеспечивает возможность развития системы баз данных без разрушения существующих приложений.
Инфологическая модель отображает реальный мир в некоторые понятные человеку концепции, полностью независимые от параметров среды хранения данных. Существует множество подходов к построению таких моделей: графовые модели, семантические сети, модель "сущность-связь" и т.д. Наиболее популярной из них оказалась модель "сущность-связь".
В реальном проектировании структуры базы данных применяется другой метод – так называемое, семантическое моделирование. Семантическое моделирование представляет собой моделирование структуры данных, опираясь на смысл этих данных. В качестве инструмента семантического моделирования используются различные варианты диаграмм сущность-связь (ER – Entity-Relationship).
Первый вариант модели сущность-связь был предложен в 1976 году Питером Пин Шэн Ченом. В дальнейшем многими автора ми были разработаны свои варианты подобных моделей (нотация Мартина, нотация Баркера и т.д.). Кроме того, различные программные средства, реализующие одну и ту же нотацию, могут отличаться своими возможностями. По сути, все варианты диаграмм сущность-связь исходят из одной идеи – рисунок всегда нагляднее текстового описания. Все такие диаграммы используют графическое изображение сущностей предметной области, их свойств (атрибутов), и взаимосвязей между сущностями.
|
Дата добавления: 2014-01-11; Просмотров: 2137; Нарушение авторских прав?; Мы поможем в написании вашей работы!