КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Структурно-функциональная организация типовой поисковой машины Интернет
|
|
|
|
Сравнительный анализ информационно-поисковых систем.
Проведем сравнительный анализ документальных, фактографических и гипертекстовых ИПС по ряду показателей. Результаты представим в табл. 9.1.
Таблица 9.1
Сравнительный анализ ИПС
| Характеристика ИПС | Виды ИПС | ||
| Документальные | Фактографические | Гипертекстовые | |
| Полнота и шум | kn max =0,5 kш max = 1 | kn max =1 kш max = 0 | kn max =0,9÷1,0 kш max = 0,1÷0,2 |
| Систематизирующая информация | Поисковые образы документов, мета-данные | Значения атрибутов объектов предметной области | Гипертекстовое представление документов, мета-данные |
| Тип поискового аппарата | Информационно-поисковые языки с развитой грам-матикой | Языки реляционного типа | Гипертекстовый тезаурус |
| Трудоемкость подготовки инфор-мационного массива | Требуется специ-альная лингвис-тическая подготовка сотрудника | Требуется высокая квалификация сотрудника | Относительно не-сложная подготовка по типам семан-тических связей |
| Структуры данных | Прямые и инверс-ные списки | Иерархические или реляционные струк-туры | Семантическая сеть: вершины – понятия, ребра – отношения |
| Математический характер критериев поиска | Логические и алгеб-раические выраже-ния | Логические и алгеб-раические выраже-ния | Семантические признаки |
| Тип собственного языка системы | Специальные информационные языки (например, Сетка-5) | Специальные языки (SQL, QBE) | ОЕЯ предметной области |
Обеспечение высокой точности и полноты поискового процесса не являются единственным критерием эффективности информационно-поисковых систем. Не менее важным является и показатель быстродействия, то есть среднее время поиска одной структурной единицы, например, документа в БЗ. Эта проблема особенно актуальна для многомодульных иерархических баз знаний, содержащих значительное количество документов.
|
|
|
Таким образом, эффективность информационного поиска необходимо рассматривать в контексте обеспечения высоких характеристик точности, полноты и быстродействия.
Информационно-поисковые системы (поисковые машины) позволяют находить ресурсы Internet непосредственно по их текстовому содержимому. Функционирование поисковой машины включает два базовых процесса:
1) индексирование ресурсов Internet (автоматическое построение и обновление индекса);
2) поиск по индексу в соответствии с запросом пользователя.
Упрощенная структура типовой поисковой машины показана на рис.
Ее главными компонентами являются:
- программный агент, «перемещающийся» по сети и индексирующий ресурсы (web-страницы);
- база данных (БД) (индекс), содержащая информацию, собираемую агентом;
- программа поиска, применяемая пользователями для поиска информации в БД.
На этапе индексирования поисковые машины реализуют следующий примерный алгоритм работы.
1. Адреса web-узлов, включаемые в обрабатываемую область, определяются по гиперссылкам, ведущим из страниц данного web-узла. При этом используются различные модификации волнового алгоритма (например, с вычислением профилей узлов).
2. Агент либо переходит к индексированию очередного web-узла из сформированного списка, либо выполняет так называемое зеркалирование (дублирование) его содержимого на свой web-узел.
3. Производится собственно индексирование. Оно может быть полнотекстовым (обрабатывается весь текст) и неполнотекстовым (обрабатываются наиболее значимые части текста: заголовки, названия, ключевые поля, начальные слова разделов и т. д.).
4. Полученные данные о ключевых словах добавляются в БД.
5. Если был сделан зеркальный дубль, он стирается.
|
|
|
6. Пункты 2-5 повторяются для каждого адреса, полученного в п. 1.
Изложенный алгоритм соответствует некоторой канонической структуре поисковой машины. Конкретные их реализации различаются по многим параметрам: поддержке простого и сложного поиска; учету различий строчных и прописных символов; возможности поиска по частям слов и словосочетаниям; поддержке обработки запросов, содержащих логические операторы И, ИЛИ, НЕ; использованию специальных языков поиска информации, значительно сокращающих его время (к сожалению, такие языки не стандартизованы, поэтому в разных поисковых машинах реализуются различные поисковые языки).
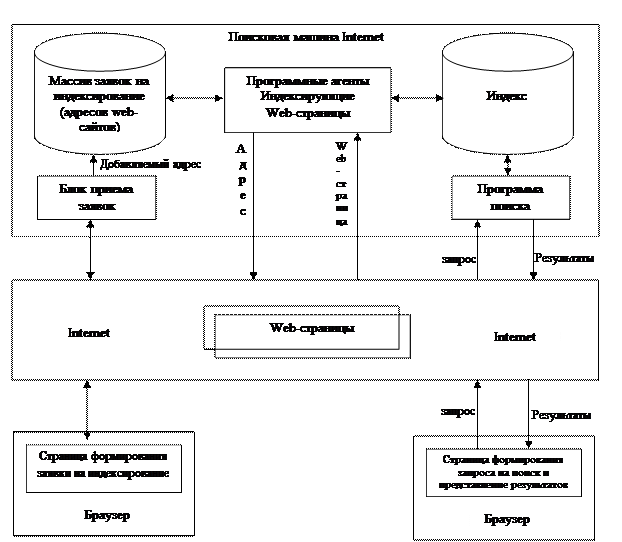
Рис. 4.3. Упрощенная структура типовой поисковой машины
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 663; Нарушение авторских прав?; Мы поможем в написании вашей работы!