КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Конвейерная организация процессоров
|
|
|
|
Двухуровневая схема управления – является основой для перехода к конвейерной организации. Наличие автономных устройств управления (Управляющих Автоматов) в различных ОУ: в АЛУ, контроллерах ПУ позволяет ЦУУ передавать им управление и переключаться на выполнение другой работы.
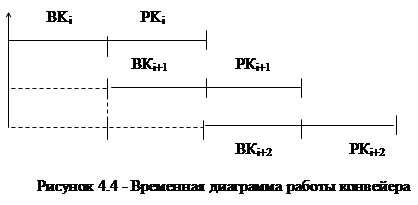 |
Впервые в ВТ конвейерную организацию предложил использовать Лебедев А.С. в 1956 году для сокращения длительности цикла выполнения команды – за счет совмещения во времени отдельных этапов выполнения команды - и реализовал этот принцип в ЭВМ типа М-20. В этой машине, точнее в ЦП, Лебедев С.А. цикл выполнения команд разделил на два этапа: 1) выборка команды и ее операндов; 2) выполнение операции в АЛУ (временная диаграмма – рисунок 4.4). Здесь:ВК- выборка команды, РК- реализация команды.
Как видно из ГСА цикла выполнения команд (рисунок 4.1) процесс выполнения АЛО (команды) состоит из следующих основных этапов (рисунок 4.5):
1. Выборка команды и дешифрация КО по группам операций (t1).
2. Формирование исполнительных адресов операндов (t2).
3. Выборка операндов (t3).
4. Реализация операции (t4).
5.
 |
Засылка результата (t5).
Сумма tц = t1+t2+…+t5 определяет время выполнения команды при последовательном (простейшем) способе организации работы ЦП.
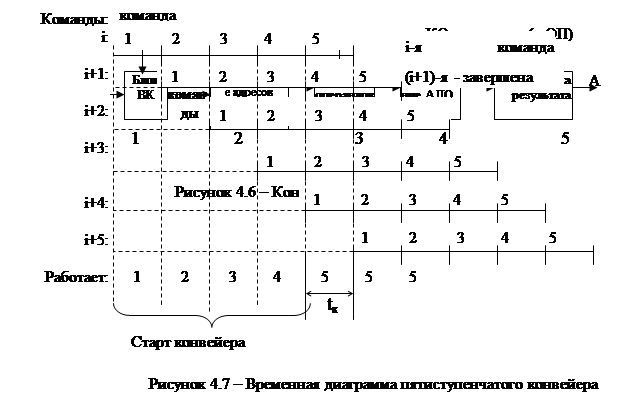
При конвейерной организации каждому из пяти этапов ставится в соответствие блок, реализующий этап, и блоки соединяются в конвейерную цепочку (рисунок 4.6). Как только блок 1 освобождается, он может начать выборку следующей команды и т.д. Ясно, что каждый блок конвейера должен работать автономно, под управлением собственного УА (временная диаграмма на рисунке 4.7).
При конвейерной организации время выполнения команды определяется выражением: tк=max(t1,t2,…,tN). Если все этапы равны t1=t2=…=tк, то время выполнения команды при конвейерной организации в пределе сокращается в N раз, где N - количество блоков конвейера, если не равны, то выигрыш меньше, чем в N раз. Начиная с пятого такта, с конвейера начинает сходить по одной команде в каждом такте (для N=5).
|
|
|
Как видно из временной диаграммы, в первом такте работает только один блок конвейера – первый, во втором такте - два блока и т. д. Начиная с пятого такта работы, с выхода конвейера начинает сходить по одной команде в каждом такте (для N=5). Старт конвейера занимает N-1 тактов (в нашем примере – 4 такта).
Конвейер позволяет как бы сократить количество тактов на выполнение команды: tком = nT, n - количество тактов, T - продолжительность такта.
Если конвейер работает в принудительном темпе с постоянным тактом Tк=tк, то такой конвейер называется синхронным: Tк=max{ti}.
Номинальная производительность синхронного конвейера Vк(ном)=1/Tк. Например, для N=5 она в 5 раз выше, чем для последовательной обработки.
Реальная производительность конвейера ниже номинальной (теоретической) из-за простоев отдельных блоков конвейера. Дело в том, что конвейер после старта работает с полной загрузкой всех N блоков только на линейных участках программы, т.е. до появления ближайшей команды перехода, по которой нарушается естественный порядок выполнения команд и конвейер фактически стартует заново. А на старте часть блоков простаивает – отсюда снижение реальной производительности конвейера.
Асинхронная организация конвейера. Очевидно, что если отрезки времени ti сильно отличаются друг от друга, то использование синхронного принципа организации работы конвейера становится неэффективным. В этом случае целесообразно использовать асинхронный принцип управления, при котором потери времени минимизируются. При асинхронной работе конвейера отсутствует единый для всех блоков такт работы. Вместо него используются сигналы занятости блоков и готовность данных для обработки в блоках. Запуск блока осуществляется при выполнении условий: 1) блок свободен от выполнения предыдущей работы, т.е. он ее выполнил и результат отправил в следующий блок; 2) на входе блока есть данные для обработки (от предыдущего блока).
|
|
|
Для равномерной работы асинхронного конвейера между блоками ставятся очереди данных-результатов (чтобы не ждать освобождения блока). Ясно, что такой конвейер фактически управляется не только потоком команд программы, но и потоком данных.
Расширение, обобщение асинхронного принципа до более общего случая приводит к формулировке идеи управления вычислительным процессом не потоком команд, а потоком данных, поступающих на вход машины. На основе этой идеи строятся т.н. процессно-потоковые ВМ. В них конвейер, на вход которого поступает не поток команд, а поток данных, имеет более сложную, разветвленную структуру. Поток команд не требуется, т.к. узлы конвейера специализированы на выполнение конкретных операций и для старта им необходимы только данные на входе. Связь узлов в структуре осуществляется путем программирования под конкретную задачу.
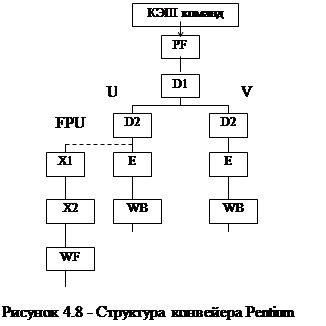 В качестве примера ЦП с конвейерной организацией рассмотрим процессор типа Pentium (рисунок 4.8). Этот суперскалярный процессор имеет два конвейера: U и V - для выполнения операций с фиксированной запятой - и один конвейер для выполнения операций с плавающей запятой - FPU. Конвейер U является главным с полным набором команд, конвейер V имеет некоторые ограничения по составу команд.
В качестве примера ЦП с конвейерной организацией рассмотрим процессор типа Pentium (рисунок 4.8). Этот суперскалярный процессор имеет два конвейера: U и V - для выполнения операций с фиксированной запятой - и один конвейер для выполнения операций с плавающей запятой - FPU. Конвейер U является главным с полным набором команд, конвейер V имеет некоторые ограничения по составу команд.
Здесь PF (Pre Fetch) – блок предварительной выборки команд, D1 (Decode stage 1) ‑ первая стадия декодировая, D2 (Decode stage 2) ‑ вторая стадия декодирования, Е (Execute) – исполнение, WB (Write Buffer) ‑ буфер записи. На стадии исполнения (Е) следующие две команды анализируются на возможность их совместного (параллельного) выполнения: если возможно, то они запускаются в конвейеры U, V на исполнение (D2, Е, WB), если не возможно, то первая из двух команд запускается в конвейер U, а конвейер V простаивает.
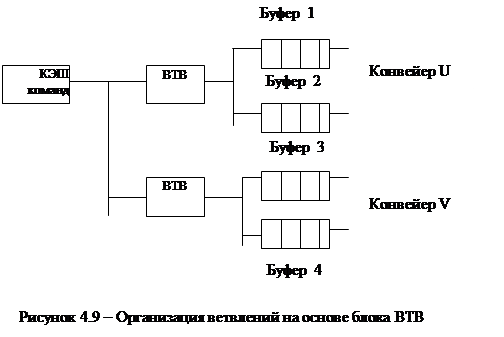 |
Блок предварительной выборки команд PF обеспечивает выборку последовательности команд в буфер длиной 32В до появления команды ветвления, т.е. команды условного перехода. В этот момент запускается блок ВТВ (Branch Target Buffer ‑ целевой буфер ветвления), который предсказывает, будет ветвление или нет. Если переход не предсказывается, то продолжается линейная предвыборка команд. Если переход предсказывается, то с точки ветвления запускается предвыборка команд в другой буфер (рисунок 4.9).
|
|
|
Если предсказанный ВТВ переход не состоялся, то буфер 2 (или 4) очищается и предварительная выборка команд начинается заново, с другого адреса. Аналогичная схема предвыборки работает на конвейер V.
Блок WF – буфер записи результата – разрядность 64 бита, используется как буфер между АЛУ и ОП. Результаты из WF–буфера записываются в ОП, если произошел «промах» при записи в КЭШ‑данных.
Команды с плавающей запятой проходят по общему конвейеру до ступени Е, после чего отправляются в конвейер FPU, состоящий из блоков Х1, Х2, WF. Блок Х1 обеспечивает преобразование данных во внутренний формат, Х2 – выполнение операции с плавающей запятой, WF – округление результата и запись его в буферный регистр.
Особенности процессора Pentium (запущен в серию в марте 1993 г.).
Первую особенность мы уже рассмотрели – это двухконвейерная (суперскалярная) структура: U, V плюс FPU.
Вторая особенность – наличие блоков предсказания переходов, что повышает производительность конвейеров, т.к. процент промахов не высок ‑ порядка 20%.
Третья особенность – разделение КЭШ‑памяти на два автономных блока – КЭШ‑команд и КЭШ‑данных.
Четвертая особенность – внутренняя шина данных процессора – 64 разряда – обеспечивает одновременное обслуживание двух 32-разрядных конвейеров U, V.
Пятая особенность – внутренняя архитектура RISC. Совместимость с младшими моделями обеспечивается путем эмуляции системы команд CISC процессоров типа i8086 и др.
|
|
|
|
|
Дата добавления: 2014-01-11; Просмотров: 1796; Нарушение авторских прав?; Мы поможем в написании вашей работы!