КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Поисковым аппаратом называется совокупность методов и средств реализации поиска информации в автоматизированных информационно-поисковых системах
|
|
|
|
Тема 6: ПОИСКОВЫЙ АППАРАТ
Поисковый аппарат: технология обработки данных, критерии оценки документальных систем.
.
Поисковый аппарат АИПС включает следующие компоненты (рис. 6.1):
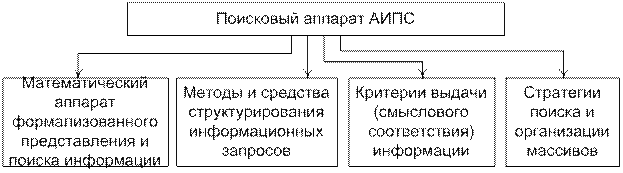
Рис. 6.1. Компоненты поискового аппарата АИПС
I. Математический аппарат формализованного представления и поиска информации представляют собой средства описания как сообщений и запросов, а также самого процесса информационного поиска [2]. Существующие в настоящее время средства представления и обработки информации базируются на принципах координатного индексирования и поиска в сочетании с использованием аппарата теории нечетких множеств. Тем самым предполагается, что:
а) основное смысловое содержание документов и запросов может быть выражено «взвешенным» набором лексических единиц (дискрипторов, ключевых слов, словосочетаний, рубрик, атомарных понятий и т.д.) ИПЯ, т.е. нечетким множеством;
б) операции поиска информации, так же как любые иные операции преобразования потоков, массивов, баз данных и т.д., могут быть представлены в терминах нечетких множеств.
Пусть T – совокупность элементов (объектов, признаков, точек). Нечеткое множество а – совокупность элементов из Т, для каждого из которых задана степень принадлежности данному множеству а. Нечеткое множество а есть совокупность упорядоченных пар 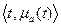 т.е.
т.е. 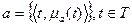 , где
, где 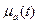 – мера принадлежности t к a.
– мера принадлежности t к a.
Обычно полагают, что лежит в интервале [0,1].
Причем, если =0, то t принадлежит а, если =1, то t полностью принадлежит a. Если принимает только два значения –0 или 1, то а – обычное (четкое) множество 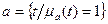 . С этой точки зрения понятие «множество» является частным случаем понятия «нечеткое множество». Рассмотрим основные операции над нечеткими множествами.
. С этой точки зрения понятие «множество» является частным случаем понятия «нечеткое множество». Рассмотрим основные операции над нечеткими множествами.
|
|
|
Если 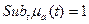 , то нечеткое множество a – нормально, в противном случае a субнормально.Любое субнормальное множество a можно нормализовать делением всех на
, то нечеткое множество a – нормально, в противном случае a субнормально.Любое субнормальное множество a можно нормализовать делением всех на 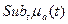 .
.
Дополнением к a является нечеткое множество 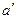 , для которого
, для которого 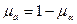 .
.
Пересечение нечетких множеств a и b ( 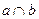 ) определяется как нечеткое множество с, состоящее из элементов, содержащихся как в a, так и в b одновременно с функцией принадлежности:
) определяется как нечеткое множество с, состоящее из элементов, содержащихся как в a, так и в b одновременно с функцией принадлежности:
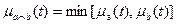 ,
, 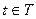 ,
,
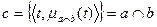 .
.
Объединение нечетких множеств a и b ( 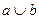 ) определяется как нечеткое множество, состоящее из элементов, содержащихся в b или в а или в b и в а одновременно с функцией принадлежности:
) определяется как нечеткое множество, состоящее из элементов, содержащихся в b или в а или в b и в а одновременно с функцией принадлежности:
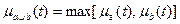 , ,
, ,
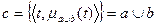 .
.
Очевидно, что если 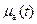 и
и 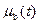 принимают только два значения (0 или 1), то рассмотренные операции являются операциями обычных (четких) множеств.
принимают только два значения (0 или 1), то рассмотренные операции являются операциями обычных (четких) множеств.
Алгебраическое произведение нечетких множеств a и b (ab) есть нечеткое множество с функцией принадлежности:
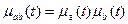 , ,
, ,
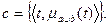
Алгебраическая сумма a и b (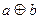 ) есть нечеткое множество с функцией принадлежности:
) есть нечеткое множество с функцией принадлежности:
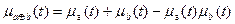 , .
, .
Приведенные операции объединения и пересечения ассоциативны и дистрибутивны по отношению друг к другу. Операция алгебраического произведения и суммы ассоциативны, но не дистрибутивны друг к другу.
Два нечетких множества a и b равны между собой (a = b), если 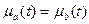 для всех . Если для всех
для всех . Если для всех 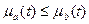 , то a содержится в
, то a содержится в 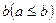 .
.
В частном случае, если 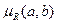 принимает только два значения (0 или 1) для всех пар
принимает только два значения (0 или 1) для всех пар 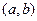 , то R – отношение с упорядоченными парами
, то R – отношение с упорядоченными парами 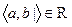
Системами нечетких множеств A по аналогии с системами четких множеств будем называть такие нечеткие множества, элементами которых сами являются нечеткие множества:
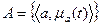 ,
, 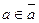 ,
, 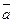 =(
=(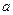 ), i=1,…,M.
), i=1,…,M.
Декартовым (прямым) произведением систем нечетких множеств A и B , 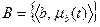 будем называть множество пар исходных множеств
будем называть множество пар исходных множеств 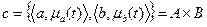 .
.
Нечеткое множество R на прямом произведении множеств  есть нечеткое множество R с функцией принадлежности , являющейся характеристикой меры принадлежности пары к R, т.е.:
есть нечеткое множество R с функцией принадлежности , являющейся характеристикой меры принадлежности пары к R, т.е.:
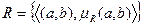 .
.
Приведенный аппарат нечетких множеств является основой формализованного представления документов, запросов, баз данных и процессов информационного поиска [2].
|
|
|
Словарем информационной среды назовем множество лексических единиц 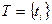 , t=1,…,N, достаточное для описания всех информационных объектов (документов, сообщений, запросов, баз данных и т.д.) и процессов (поиска, распределения БД и т.д.) информационной среды.
, t=1,…,N, достаточное для описания всех информационных объектов (документов, сообщений, запросов, баз данных и т.д.) и процессов (поиска, распределения БД и т.д.) информационной среды.
Словарь T, так же как и тезаурус, является моделью коллективных знаний и может быть использован для описания различных информационных объектов.
Используя аппарат нечетких множеств любое информационное сообщение (документ, запрос) можно представить нечетким множеством, т.е. множеством лексических единиц с мерами принадлежности данному сообщению: сообщение 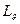 – нечеткое множество:
– нечеткое множество:
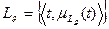 , ,
, , 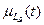 – мера принадлежности t к .
– мера принадлежности t к .
Элементарным информационным профилем будем называть некоторое нечеткое множество 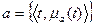 , ,
, , 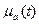 – мера принадлежности t к А. Профилю а могут быть поставлены в соответствие такие объекты, как профиль издательства, библиотеки, поисковый образ документа или запроса, тематическая рубрика некоторого рубрикатора, профиль информационной потребности и т.д.
– мера принадлежности t к А. Профилю а могут быть поставлены в соответствие такие объекты, как профиль издательства, библиотеки, поисковый образ документа или запроса, тематическая рубрика некоторого рубрикатора, профиль информационной потребности и т.д.
Будем говорить, что сообщение релевантно профилю а, и обозначать этот факт 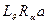 , если выполняется условие
, если выполняется условие 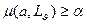 , где
, где 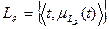 , , ,
, , , 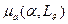 –мера релевантности (семантической близости) к a,
–мера релевантности (семантической близости) к a, 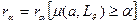 – критерий релевантности сообщения информационному профилю а,
– критерий релевантности сообщения информационному профилю а, 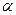 – пороговое значение критерия релевантности.
– пороговое значение критерия релевантности.
Будем считать, что на прямом произведении систем нечетких множеств
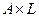 ,
,  ,
, 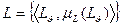 установлено отношение нечеткой релевантности, если оно порождает систему нечетких множеств R с элементами
установлено отношение нечеткой релевантности, если оно порождает систему нечетких множеств R с элементами 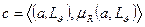 т.е.
т.е.
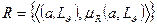 ,
,
где 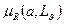 – мера релевантности A и . В общем случае отношение нечеткой релевантности, определенное даже на двух четких системах множеств, является нечетким.
– мера релевантности A и . В общем случае отношение нечеткой релевантности, определенное даже на двух четких системах множеств, является нечетким.
Отношение 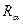 , заданное на прямом произведении систем нечетких множеств
, заданное на прямом произведении систем нечетких множеств 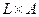 мерой релевантности и пороговым значением
мерой релевантности и пороговым значением 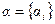 , i =1,… M, назовем отношением релевантности:
, i =1,… M, назовем отношением релевантности:
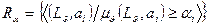 .
.
Выражение 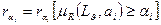 , i =1,… M представляет собой критерий релевантности сообщений информационному профилю
, i =1,… M представляет собой критерий релевантности сообщений информационному профилю 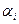 и разбивает совокупность сообщений L по отношению к на подмножество релевантных
и разбивает совокупность сообщений L по отношению к на подмножество релевантных 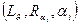 и нерелевантных сообщений, переводя тем самым отношение нечеткой релевантности R в отношение релевантности
и нерелевантных сообщений, переводя тем самым отношение нечеткой релевантности R в отношение релевантности 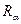 (отношение можно рассматривать как –уровень отношения R).
(отношение можно рассматривать как –уровень отношения R).
|
|
|
Отношения релевантности и нечеткой релевантности лежат в основе поискового аппарата АИПС. Именно на них базируются все процессы индексирования и поиска информации. Однако АИПС, построенные только на основе введенных формальных отношений релевантности, не могут обладать высокой эффективностью, в силу того, что их ИПЯ не учитывает парагматических и синтагматических отношений.
В связи с этим в реальных АИПС существует многообразие средств и методов формализованного представления (в общем случае структурирования) информационных запросов, критериев релевантности, методов и стратегий поиска информации.
II. Методы и средства структурирования информационных запросов.
В основе формирования поисковых образов документов и запросов, предписаний на поиск информации лежат базисные (паагматические) отношения между понятиями, отображая действительно существующие и независимые от контекста взаимоотношения между предметами и явлениями, позволяют на основе содержательного анализа сообщений и запросов дополнять их поисковые образы терминами, отсутствующими в индексируемых текстах и более точно отображающими смысловое содержание индексируемых текстов.
Информация о базисных отношениях понятий содержится в информационно-поисковом тезаурусе (ИПТ) автоматизированной ИПС, который и является основой формирования поисковых образов запросов.
Процесс формирования ПОЗа включает следующие этапы:
– выявление информационной потребности и формулировку информационного запроса на естественном языке;
– выявление значимых терминов запроса;
– перевод значимых терминов на ИПЯ;
– формирование поискового образа запроса (ПОЗ).
При выявлении значимых терминов запроса могут использоваться как основная, так и внешняя информация, которую можно извлечь из аналогичных запросов, релевантных документов, тезаурусов, специальной литературы.
Перевод значимых терминов на ИПЯ заключается в замене ключевых слов и словосочетаний (значимых терминов) дескрипторами информационно-поискового тезауруса. При этом могут использоваться любые парагматические отношения ИПТ.
|
|
|
Использование базисных отношений позволяет уточнить или, наоборот, расширить запрос. Для расширения запросов применяются дескрипторы более высоких уровней иерархии отношений «род–вид» и «целое-часть» (иерархических отношений). Для уточнения запоса, наоборот, используют дескрипторы низших иерархических уровней тезауруса.
АИПС без словарей (с некотролируемой лексикой) не требуют перевода значимых терминов в дескрипторы ИПЯ. Здесь лексическими единицами ПОЗа являются сами значащие термины, т.е. ключевые слова и словосочетания.
Формирование ПОЗа. Задача состоит в том, чтобы сформировать ПОЗ в такой логико-семантической записи, смысловое содержание которой как можно лучше соответствует смысловому содержанию запроса.
Простейшая форма такой записи, в соответствии с рассмотренным ранее аппаратом нечетких множеств, – представление ПОЗа четким или нечетким множеством, выявленным на предыдущем этапе лексических единиц (дескрипторов, ключевых слов или сочетаний):
ПОЗ=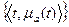 или ПОЗ =
или ПОЗ =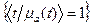 , ,
, ,
Где 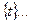 – упорядоченные по алфавиту дескрипторы, ключевые слова/словосочетаний, выражающие смысловое содержание запроса. Парадигматические отношения в такой записи ПОЗа в явном виде отсутствуют. Синтагматические отношения выражаются лишь наличием или отсутствием в ПОЗе тех или иных лексических единиц.
– упорядоченные по алфавиту дескрипторы, ключевые слова/словосочетаний, выражающие смысловое содержание запроса. Парадигматические отношения в такой записи ПОЗа в явном виде отсутствуют. Синтагматические отношения выражаются лишь наличием или отсутствием в ПОЗе тех или иных лексических единиц.
Для более полного учета парадигматики и синтагматики информационного запроса при формировании ПОЗа используют аппарат булевой логики. В этом случае ПОЗ представляется некоторым логическим выражением, например:
ПОЗ=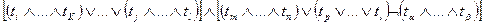 .
.
Здесь 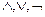 – операторы булево логики И (AND), ИЛИ (OR), НЕ (NOT).
– операторы булево логики И (AND), ИЛИ (OR), НЕ (NOT).
Такая форма записи ПОЗа повышает степень адекватности смыслового содержания ПОЗа информационному запросу, но существенно усложняет как формирование ПОЗа, так и диалоговый поиск. Для упрощения этих процессов информационный запрос разделяется на подзапросы, а ПОЗ соответственно на поисковые образы подзапросов (ПОПЗ). При этом подзапросы формулируются таким образом, чтобы соответствовующие им поисковые образы имели простую логическую структуру и могли быть сформированы с использованием только одного или двух логических операторов И, ИЛИ, НЕ. Например, Если в предыдущем примере разделить запрос на такие подзапросы, каждому из которых соответствует одно из логических выражений, представленных в круглых скобках приведенного ранее ПОЗа, то поисковый образ запроса будет представлен выражением:
ПОЗ=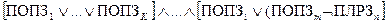 .
.
Поиск по сложным булевым выражениям требует много времени. Для ускорения поиска сложное логическое выражение можно существенно упростить путем разбивки на подзапросы. Более того, можно показать, что поиск по определенным группам логических выражений можно свести к поиску по простому множеству лексических единиц, если каждой из ЛЕ присвоить определенный вес и проводить поиск с учетом весов ЛЕ, т.е. проводить поиск в соответствии с моделью нечетких множеств. Такой поиск носит название весового, или поиска по весовой логике. Существуют таблицы перехода от булевых форм ПОЗов к простым ПОЗам, выраженным в терминах нечетких множеств, когда ПОЗ представляется набором лексических единиц с их весовыми коэффициентами (весами), указывающими вес данной ЛЕ в данном позе.
В качестве ЛЕ ПОЗа могут выступать и поисковые образы подзапросов. Это позволяет любое сложное логическое выражение свести к совокупности ПОЗов, выраженных в терминах нечетких множеств: сложное выражение ПОЗа разбивается на поисковые образы подзапросов, каждый из подзапросов переводится в нечеткое множество с элементами – поисковыми образами подзапросов. Сформированное нечеткое множество является поисковым образом запроса в целом.
Мощным средством повышения семантической силы ИПЯ в результате учета синтагматики информационного запроса является использование отношения непосредственного следования лексической единицы А за лексической единицей В. Указание в ПОЗе порядка следования ЛЕ в искомых текстах позволяет повысить точность поиска путем усиления прекоординации ИПЯ. Отношение непосредственного следования отражается в ПОЗах соответствующим оператором. В англоязычных ИПС обычно используют оператор ADJ или adj. Запись ПОЗа в виде BadjA означает, что в ответ на запрос будут выданы только документы, тексты или ПОДы которых содержат термин А, непосредственно следующий за термином В.
Не менее важным средством повышения качества поиска является усечение лексических единиц ПОЗа, т.е. отбрасывание заданного числа первых и/или последних символов (знаков) лексической единицы ПОЗа. Такое усечение позволяет игнорировать при поиске многообразие приставок и/или окончаний слов и тем самым повышать эффективность поиска искомых текстов, точность поиска путем усиления прекоординации ИПЯ.
III. Критерий релевантности
Формированием поискового образа запроса и перевода его в машиночитаемую форму заканчивается один из важнейших этапов поиска информации – этап предмашинной обработки запроса. Следующий этап – непосредственно процесс автоматизированного поиска информации, состоящий в сравнении ПОДов сообщений (документов) базы данных АИПС с заданным поисковым образом запроса (или их совокупности) для выборки документов (сообщений), релевантных информационному запросу. Критерий, позволяющий принять решение о релевантности сообщения информационному запросу, носит название критерия релевантности (КР), или критерия смыслового соответствия (КСС), или критерия выдачи (КВ).
Различают два понятия релевантности – релевантность и формальную релевантность.
Понятие релевантности связано со смысловым соответствием сообщения (документа) тексту информационного запроса на естественном языке. Релевантность сообщения запросу в таком понимании может оценить только человек. Критерий, которым он пользуется при принятии решения о релевантности, сформулировать невозможно.
Формальная релевантность – соответствие ПОДа ПОЗу. Поскольку ПОД и ПОЗ представляют собой формализованные структуры, оценку такой релевантности может дать компьютер. Для этого необходимо задать ему формальное выражение критерия релевантности.
Ясно, что при переводе информационной потребности в информационный запрос, а запрос в ПОЗ, так же как и при переводе сообщения в ПОД, возникают определенные семантические искажения. В связи с этим формальная релевантность весьма существенно отличается от действительной релевантности. Документ, признанный системой формально релевантным, может не оказаться таковым с точки зрения потребителя. Однако, альтернативы нет, АИПС может пользоваться только понятием формальной релевантности. Задача только в том, чтобы сформулировать такой критерий формальной релевантности, который бы как можно лучше отличал релевантные сообщения от нерелевантных. В дальнейшем под терминами критерия релевантности, критерия выдачи и критерия смыслового соответствия мы будем понимать критерий формальной релевантности.
Критерий релевантности – совокупность процедур (правил) определения смыслового соответствия ПОДа ПОЗу.
Для задания критерия релевантности простейшем случае достаточно задать процедуру вычисления меры семантической близости ПОДа ПОЗу и некоторое пороговое значение этой меры, такое, что эта мера, вычисленная для конкретных ПОДа и ПОЗа, превышает заданное пороговое значение, то документ признается релевантным запросу (и наоборот).
Исходя из того, что в большинстве реальных АИПС поисковые образы запросов (подзапросов) и документов представляются четкими или нечеткими множествами лексических единиц, мера релевантности может быть задана как мера близости нечетких множеств.
Мерой релевантности 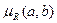 (соответствия или нечеткого равенства) двух нечетких множеств a и b будем считать неотрицательную вещественную функцию, такую что:
(соответствия или нечеткого равенства) двух нечетких множеств a и b будем считать неотрицательную вещественную функцию, такую что:
1)  , если a и b не пересекаются;
, если a и b не пересекаются;
2) 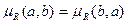 ;
;
3) зависит от нормы семантических векторов множеств a и b и нормы семантического вектора их пересечения или произведения (могут использоваться любые нормы векторов, удовлетворяющие предъявленным к нормам требованиям). Под семантическим вектором 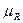 нечеткого множества
нечеткого множества 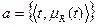 здесь понимается вектор:
здесь понимается вектор:
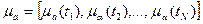 .
.
Следовательно, есть функция от 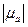 ,
, 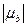 ,
, 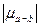 ,
, 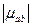 , т.е. =
, т.е. =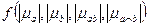 . Под множеством a и b и далее можно понимать ПОД, под множеством b – ПОЗ или наоборот. Мера симметрична.
. Под множеством a и b и далее можно понимать ПОД, под множеством b – ПОЗ или наоборот. Мера симметрична.
Сформулируем некоторые меры релевантности нечетких множеств, используя различные виды норм и функциональных зависимостей.
1. В качестве скалярной свертки вектора используем октаэдрическую норму, а функциональную зависимость зададим в виде 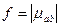 . Тогда имеет меру:
. Тогда имеет меру:
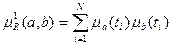 .
.
Если a и b – четкие множества, то 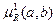 – векторное произведение векторов a и b.
– векторное произведение векторов a и b.
Пример: а= (1,1,1,0,1,0,1,1),
b= (1,1,1,1,0,1,0,0), =3.
а= (0,3; 0,4; 1,0; 0,8),
b= (0,8; 0,0; 0,3; 0,4), =0,86.
Неудобство данной меры в том, что она ненормирована.
2. В качестве скалярной свертки векторов 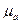 и
и 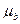 использует евклидову норму, в качестве скалярной свертки векторов
использует евклидову норму, в качестве скалярной свертки векторов 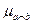 и
и 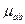 – октаэдрическую норму, а функциональную зависимость зададим в виде:
– октаэдрическую норму, а функциональную зависимость зададим в виде:
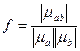 ,
, 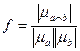 .
.
Тогда имеем две меры:
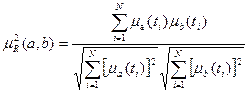 .
.
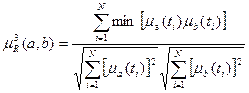 .
.
В предыдущем примере имеем:
для четких a и b 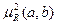 =0,54,
=0,54,
для нечетких a и b =0,66,
где – нормированная мера, 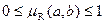 . В теории ИПС эта мера релевантности получила название косинусной меры.
. В теории ИПС эта мера релевантности получила название косинусной меры.
3. В качестве скалярной свертки всех векторов используем октаэдрическую норму, а функцию зададим в виде:
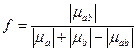 .
.
В этом случае
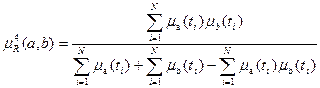 .
.
Для четких a и b предыдущего примера 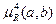 =0,37.
=0,37.
Для нечетких a и b =0,27. Для четких множеств является нормированной мерой 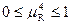 и носит название меры Танимото. Для нечетких a и b указать диапазон изменения данной меры затруднительно.
и носит название меры Танимото. Для нечетких a и b указать диапазон изменения данной меры затруднительно.
В соответствии с данным определением меры релевантности можно построить достаточно много различных мер. Все они определены в многомерном пространстве при любых координатах векторов нечетких множеств и обладают свойствами непрерывности, однозначности и ограниченности. Минимум, равный нулю, соответствует отсутствию пересечения множеств (четких или нечетких), максимум – из совпадению (идентичности). Максимум некоторых из рассматриваемых мер равен единице, что является весьма важным. Такие меры называют нормированными в отличие от ненормированных, максимум которых не равен единице.
Критерием смыслового соответствия назовем пару:
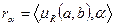 ,
,
где 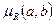 – функция вычисления меры релевантности или просто мера релевантности, –пороговое значение релевантности, такое что
– функция вычисления меры релевантности или просто мера релевантности, –пороговое значение релевантности, такое что
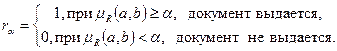
Изменяя пороговое значение , можно организовать эшелонированную выдачу. Каждый эшелон такой выдачи соответствует определенной мере семантической близости сообщения запросу. Чем выше пороговое значение , тем более жесткие условия налагаются на смысловую близость документа запросу. Нормированных мерах при =1 для выдачи документа требуется полное совпадение его ПОДа соответствующему ПОЗу.
В практике информационного поиска используются и другие критерии. В частности:
1. На полное вхождение ПОЗа в ПОД, т.е. если множество =ПОЗ, b =ПОД, то документ считается релевантным, если 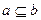 .
.
2. На полное вхождение ПОДа в ПОЗ. Документ выдается, если 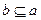 .
.
3. На полное вхождение ПОДа в ПОЗ (или наоборот) с учетом базисных отношений. Документ выдается, если каждому термину ПОЗа (ПОДа) соответствует либо тот жнее термин ПОДа (ПОЗа), либо термин, связанный с ним парадигматическими отношениями.
4. На полное вхождение с учетом текстуальных и базисных отношений. ТО же что и ранее, но сравнение проводится с точностью о совпадения текстуальных отношений терминов в ПОЗе и ПОДе.
IV. Оценка эффективности поиска
Оценка эффективности АИС связана с анализом как затрат АИС на информационное обеспечение основной деятельности и эффекта, получаемого в основной деятельности в результате использования предоставляемой АИС информации. Однако «полезность» результатов основной деятельности в большинстве случаев не может быть выражена количественно, в особенности, если такие результаты носят социально-политический, юридический, моральный, психологический характер. Еще большие сложности возникают при оценке того эффекта от основной деятельности, который получен в результате использования информации.
В силу практической невозможности оценки экономической эффективности АИС при анализе АИС приходится ограничиваться оценкой лишь функциональной эффективности. Под функциональной эффективностью системы понимают меру соответствия системы своему целевому назначению. Цель функционирования АИПС состоит в информационном обеспечении ее пользователей, т.е. в оперативном поиске необходимой им информации.
В связи с этим основными показателями функциональной эффективности АИПС являются: полнота поиска; точность поиска; оперативность поиска; специфичность поиска; коэффициент корреляции; интегральный энтропийный показатель.
Оценка любого показателя функциональной эффективности связана с определением неформальной релевантности выданной информации информационному запросу. Релевантность выданных документов (сообщений) запросу может оценить либо потребитель информации, либо группа экспертов. Будем считать, что такая оценка проведена и базе данных АИПС известны все сообщения, релевантные БД по отношению к заданному запросу разделено на:
– подмножество релевантных документов 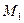 ;
;
– подмножество нерелевантных документов 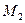 (рис. 6.2).
(рис. 6.2).
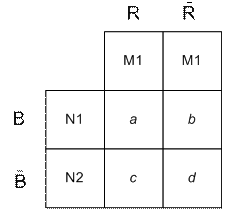
Рис. 6.2. Таблица сопряженности поиска
Суть работы АИПС состоит в разбиении множества документов БД на:
– подмножество формально релевантных запросу документов (выдаваемых документов) №1;
– подмножество формально нерелевантных запросу документов (невыдаваемых документов) №2;
Полнота поиска определяется отношением числа выданных релевантных документов (a) к общему числу релевантных документов массива (a 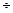 с):
с):
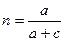 ,
, 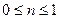 ,
,
где с – число невыданных релевантных документов.
Точность поиска – отношение числа выданных релевантных документов (а) к общему числу выданных документов (a с):
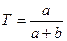 ,
, 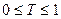 .
.
Специфичность поиска – отношение числа невыданных не релевантных документов (d) к общему числу нерелевантных документов (d b):
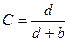 ,
, 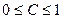 .
.
Коэффициент корреляции поиска определяется выражением:
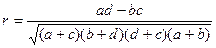 .
.
В идеальной АИПС 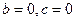 и
и 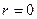 .
.
Для интегральной оценки эффективности функционирования АИПС используют интегральный энтропийный показатель.
В этом случае АИПС можно рассматривать как инструмент, способный изменять энтропию поискового массива. Если допоисковую энтропию БД обозначить 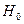 , а послепоисковую
, а послепоисковую 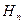 , то величина
, то величина
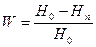
Будет характеризовать меру упорядоченности состояния БД являющуюся результатом процесса поиска по заданному запросу.
Обозначим:
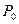 – концентрация релевантных документов в исходном массиве документов
– концентрация релевантных документов в исходном массиве документов 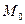 ;
;
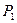 – концентрация релевантных документов в массиве выданных документов;
– концентрация релевантных документов в массиве выданных документов;
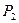 – концентрация релевантных документов в массиве невыданных документов.
– концентрация релевантных документов в массиве невыданных документов.
Очевидно: 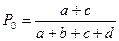 ,
,
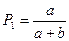 ;
; 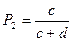 .
.
Согласно определению энтропии неопределенность исходного массива (до поиска) характеризуется величиной:
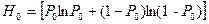 .
.
Неопределенность массива выданных документов:
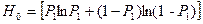 .
.
Неопределенность массива невыданных документов:
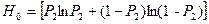 .
.
Мощность массива выданных документов равна 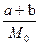 .
.
Мощность массива невыданных документов равна 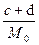 .
.
Послепоисковая неопределенность базы данных:
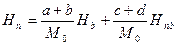 .
.
Подставив полученные значения и в формулу для W, получим:
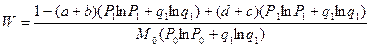 ,
,
где 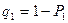 .
.
Энтропийый показатель изменяется в диапазоне от 0 до 1. Приведенные формальные выражения позволяют определить те или иные показатели технической эффективности АИПС по отношению к конкретному запросу. Чтобы получить аналогичные показатели как характеристики АИПС в целом, необходимо провести серию экспериментов по массиву запросов и усреднить полученные результаты.
При этом могут использоваться следующие формулы:
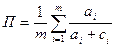 –средняя макрополнота;
–средняя макрополнота;
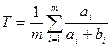 –средняя макроточность;
–средняя макроточность;
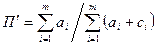 –средняя микрополнота;
–средняя микрополнота;
 –средняя микроточность.
–средняя микроточность.
Теоретически и экспериментально показано, что показатели полноты и точности поиска находятся в обратно пропорциональной зависимости, т.е. повышение полноты поиска в рамках данной ИПС всегда сопровождается снижением (по крайней мере неповышением) точности поиска. И наоборот.
Для определения релевантности документов в исходной базе данных используются различные методы, позволяющие определить число релевантных документов в БД, не прибегая к анализу всей БД. К таким методам относятся:
1. Случайная выборка некоторой части документов. Определение доли релевантных документов в выборке и аппроксимация полученных данных на всю БД.
2. Использование запросов, ориентированных на поиск заранее заданных документов и определение в выдаче доли заданных документов. Этим методом можно непосредственно оценить полноту поиска.
3. Проведение серии поисков по последовательно модифицируемому запросу и определение накапливаемых в процессе модификации запроса релевантных документов выдачи.
Литература
1. Голицина О.Л., Максимов Н.В., Попов И.И. Информационные системы: уч. пособие/ О.Л. Голицина, Н.В. Максимов, И.И. Попов.– М.ФОРУМ, 2009.– 496с. (рекомендовано УМО вузов РФ по образованию в области прикладной информатики).
2. Максимович Г.Ю., Романенко А.Г., Самойлюк О.Ф. Информационные системы: Учеб.пособие.– М.: Российск. гос. гуманит. ун-т, 2007. – 289с.
[1] МЕЖГОСУДАРСТВЕННЫЙ СТАНДАРТ ГОСТ 7.0–9.9. Система стандартов по информации, библиотечному и издательскому делу. ИНФОРМАЦИОНН0-БИБЛИОТЕЧНАЯ ДЕЯТЕЛЬНОСТЬ, Библиография. Термины и определения. Минск, 2000.
[2] Полнозначные слова – существительные, прилагательные, глаголы, наречия, числительные, местоимения. Неполнозначные слова – предлоги, союзы, связки, частицы.
[3] Парадигматические отношения обусловлены наличием логических связей между предметами и явлениями, обозначенными данными словами. Например, наиболее важные парадигматические отношения: «соподчинение», «вид–род» («шкаф–мебель»), «род–вид», «часть–целое» («лезвие–нож»), «целое – часть», «причина–следствие» («лампа–свет»), «следствие–причина», «функциональное сходство» («телега–автомобиль»).
[4] Синонимия знака состоит в том, что один и тот же предмет, объект может быть назван по разному. Синонимия – одинаковость слов по значению при различии с звуковой стороны (лингв.).
[5] Омонимия слова состоит в том, что при одинаковом написании они имеют различный смысл: например, «соль» – это может быть вещество, нота, главная часть, суть чего-то. Омонимия представляет собой графическое и (или) фонетическое совпадение слов (и вообще знаков, знакосочетаний и словосочетаний), имеющих различный смысл и (или) значение. Например, "лук" (растение) и "лук" (оружие).
[6] Полисемия состоит в том, что один и том же знак (лексическая единица) выражает пучок родственных свойств, значений. Например, знак «Ключ» обозначает дверной ключ, нотный ключ, ключ к шифру. Все три понятия близки между собой по смыслу
[7] Фасет – жесткая структура, которая отображает определенный аспект отношений между словами ИПЯ. Фасетная классификация – это набор нескольких иерархических классификаций, каждая из которых относится к одному аспекту рассмотрения объекта. Вся лексика ИПЯ разбивается на поаспектные множества (фасеты). Например, подмножество терминов, обозначающих процессы, образует фасет «Процессы». На этих подмножествах и строятся в дальнейшем иерархические классификации. Наиболее часто рассматривают фасеты «Вещества», «Материалы», «Процессы», «Состояния», «Свойства», «Реакции», «Действия».
[8] Прекоординированные ИПЯ – это ИПЯ, словарный состав которого жестко связан грамматическими средствами в единую структуру. Лексика и грамматика такого языка, а также синтаксис, морфология, все парадигматические и синтаксические отношения самостоятельно не существуют. Они образуют единую жесткую связанную структуру. Индексирование текстов (перевод текстов на ИПЯ) выполняется только с использованием элементов такой жесткой структуры. Каждый ИПЯ этого типа представляет собой некоторую систему классификации.
|
|
|
|
Дата добавления: 2014-01-13; Просмотров: 1433; Нарушение авторских прав?; Мы поможем в написании вашей работы!