КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Двоичные данные
|
|
|
|
Символьные данные
Символьные данные наиболее распространённые. Для них существует несколько методов контроля. Перечислим некоторые из них.
Многократный ввод. Данные вводятся два или большее число раз независимо, разными операторами, а затем сравниваются между собой. При несовпадении сообщается об ошибке. Этот способ очень надёжен. Пропустить ошибку маловероятно, но он требует большого объёма работы для своей реализации.
По списку возможных значений. Вводимые значения, например, названия фирм партнёров, сравниваются с имеющемся их списком. При несовпадении отмечается ошибка. Такой метод эффективен и прост в реализации, но не всегда возможен.
По допустимым пределам. Некоторые данные принимают значения из ограниченного диапазона. Например, номер месяца не может быть больше 12, возраст сотрудника меняется от 17 до 60 лет и т.д. Если введённое значение вне установленных пределов, то фиксируется ошибка ввода. Этот метод прост в реализации, но малоэффективен; используется, поскольку не требует дополнительных затрат при вводе.
По типу. Данные делятся по типам: целые, вещественные, логические и т.п. Если тип вводимых данных заранее известен, можно проверять вводимые данные на соответствие указанному типу.
По шаблону. Этот метод близок к контролю по типам, только типы здесь определяет пользователь с помощью шаблона. Шаблон - это последовательность символов, где каждый символ определяет некоторый класс символов или только самого себя, т.е. класс, состоящий из единственного символа. Трудность задания в том, что нужно отличать задание класса от задания символа. Эту трудность обходят, вводя дополнительно целочисленный вектор-маску. В маске компонента 0 означает непосредственное задание символа, а 1 означает, что символ на соответствующем месте обозначает не себя, а класс символов. Например, если символом Z обозначать цифры, то шаблон ZZZZZ.ZZ и маска 11111011 будут обозначать целое число с 6 целыми и 2 десятичными разрядами.
|
|
|
По каналам связи данные передаются, как правило, в двоичном виде. Поэтому потрачены значительные интеллектуальные усилия для разработки эффективных методов контроля двоичных данных.
При вводе данных в ЭВМ и передаче их по линиям связи возможны ошибки, приводящие к потере информации. Для предотвращения подобных потерь вводится специальное кодирование, основанное на добавлении некоторой избыточной информации во вводимые или передаваемые данные. Объем данных увеличивается, что позволяет контролировать правильность этих данных. Таким образом, данные, генерируемые некоторым источником, подвергаются сжатию, а затем вводится дополнительная контролируемая информация. Данные, полученные в результате двукратного кодирования, вводятся или передаются, причем возможно обнаружение или даже исправление наиболее частых ошибок.
Будем рассматривать в качестве данных двоичные последовательности. Основная идея кодирования проста. Разобьем исходную последовательность на блоки длиной k, символы которых назовем информационными, и припишем к ним r проверочных символов, получив расширенный блок из n = k + r символов, готовый для ввода или передачи. Указанный код называется блоковый и имеет тип [ n, k ].
Если будет искажена часть символов блока, то проверочные символы могут дать достаточную информацию, чтобы обнаружить или даже исправить ошибку. Если проверочные символы определены как линейные комбинации информационных символов, кодирование называется линейным.
Способ построения расширенных блоков может быть различным. Можно выбрать тот или иной способ такого построения, т.е. кодирования, исходя из поставленных целей.
|
|
|
Существует 2 n различных блоков длиной n, но только 2 k из них являются кодословами и совокупность их образует код.
В результате передачи данных по каналу связи или другой операции над кодословом может быть получена любая последовательность из n знаков. По полученным n символам необходимо определить, какое из 2 k возможных кодослов на самом деле было передано. Это задача декодирования. В результате декодирования можно:
обнаружить и исправить ошибку, если она есть, или правомерно определить её отсутствие;
обнаружить ошибку, но не иметь достаточной информации, чтобы её исправить;
не обнаружить сделанную ошибку или неправильно декодировать принятое слово.
Вероятность появления не обнаруживаемой ошибки одна их количественных характеристик кода. Другая характеристика - скорость передачи данных, которая для блоковых кодов равна k/n.
Перечислим некоторые популярные в практике методы кодирования.
Коды с повторением. Если нам необходимо передать символ 0 или 1, мы передаём его несколько раз подряд (n раз). При декодировании принятые данные разбиваются на блоки длиной n и, если в данном блоке единиц больше, чем нулей, то блок заменяется 1, а, если единиц меньше, то блок заменяется 0. В том случае, если число единиц и нулей в принятом блоке совпадают, декодирование невозможно (отказ от декодирования).
Для кодов с повторением k = 1, а n произвольно. Значение каждого проверочного символа совпадает со значением информационного символа. Если n достаточно велико, вероятность ошибки декодирования мала. Однако трудоёмкость метода слишком велика, она возрастает в n раз.
Коды с проверкой на чётность. Другим примером простых кодов являются коды с проверкой на четность, содержащие только один проверочный символ. Число единиц в кодослове (x1,...,xn, xn+1) всегда четно, поскольку проверочный символ определяется формулой хn+1 = (x1 +... + xn) mod 2.
При использовании этого метода ошибки обнаруживаются, если их чётное число и, в частности, обнаруживаются одиночные ошибки. Трудоёмкость этого метода невелика, и он используется для контроля правильности преобразования данных в компьютере. Обнаруживаемая при использовании этого метода ошибка называется «ошибка чётности».
|
|
|
Конечные поля. Для изложения теории линейных кодов и далее при изучении методов шифрации нам понадобятся элементы теории конечных полей.
Рассмотрим конечное множество М = { e0,e1,...,em-1 }. Определим на M операции сложения и умножения его элементов, полагая
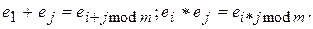
Эти операции удовлетворяют условиям коммутативности, ассоциативности и дистрибутивности, точно также как это имеет место для сложения и умножения обычных действительных чисел.
Имеется нулевой элемент, а именно e0, для которого e0 + ei = е0, и единичный элемент e1, для которого e1*ei = еi, для любых i =0,..., m - 1.
Для сложения имеется обратная операция - вычитание: еi - ej = еi + (- ej), где - -ej элемент обратный к ej, т.е. такой, что ej + (-еj) = е0. Легко проверить, что обратные элементы можно вычислить по формуле –е0 = е0, -еi = еm-i при i > 0.
Деление существует не всегда. В частности, деление существует, если порядок m множествам простое число: 2,3,5,7,11 и т.д. В этом случае множество М называется полем характеристики m
Пример. Пусть М = {0,1}. В соответствии с определением
0+0=0; 0+1=1; 1+0=1; 1+1=0;
0*0=0;0*1=0;1*0=0; 1*1 =1.
Кроме того, -0 = 0, -1 = 1. Поэтому при операциях с двоичными данными минус перед константой или переменной можно отбросить.
Линейные коды. Коды Хэмминга. В кодах, содержащих несколько информационных и несколько контрольных символов, каждый контрольный символ функция от информационных символов. В простейшем случае эти функции линейные, т.е. в двоичном случае это суммы некоторого подмножества информационных символов, взятые по модулю два. Поэтому можно считать, что линейные коды - это обобщение кода контроля по чётности.
Построим код с блоковой длиной n = 6, имеющий k = 3 информационных символов, т.е. код типа [6,3], определив его уравнениями:
X1=Z1;
X2=Z2;
Х3 = Z3;
Х4 = Z1 + Z2;
X5 = Z1 + Z3;
X6= Z2+Z3,
где Z1, Z2, Z3 - передаваемые разряды, X1, X2, Х3 - информационные разряды, Х4, Х5, Х6 - контрольные разряды. Все операции здесь и далее производятся над двоичными Данными как элементами поля характеристики 2.
Пример. Пусть необходимо передать блок z = (1,1,1). Тогда получим блок для передачи по каналу связи: (1,1,1,0,0,0).
|
|
|
Кодослово (х1,...,x6) удовлетворяет проверочным уравнениям
x1 + x2 + x4 = 0;
x1 + x3 + x5 = 0;
x2 + x3 + x6 = 0
или в матричной записи
HxT = 0,
где хT - вектор-столбец;
0 = (0,0,0);
Н - проверочная матрица,
Н = 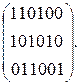
Любое кодослово, т.е. слово, передаваемое по каналу связи, удовлетворяет этому условию. Следовательно, решая указанную систему линейных уравнений, найдём все кодослова, т.е. построим код. В нашем случае число решений будет равно 23=8, тогда как общее число слов длины 6 составляет 26=64. Перечислим все 8 кодослов: 000000, 001011, 010101, 011110, 100110, 101101, 110011, 111000. Именно с этими словами совершают операции ввода или пересылки. Если принятое слово не совпадает ни с одним из перечисленных кодослов, то имеет место ошибка.
Введём вектор ошибок (еi = 1,...,6), где ei = 1, если при передаче i -гo символа возникла ошибка, в противном случае положим еi = 0. Обозначим принятое слово (y1,...,y6). Тогда уi = (хi + ei), i = 1,...,6.
Вектор-столбец s, определенный уравнением s = НуT, называется синдромом.
Поскольку НуT = НxT + НеT = НеT, синдром ошибки е и синдром переданного слова у одинаковы и равны s.
В классе всех решений уравнения НеT = s, где s синдром полученного слова выбираем вектор е с минимальным число единиц и считаем, что это - вектор ошибок.
Рассмотрим условия, при которых вектор е, следовательно, и передаваемый вектор, восстанавливаются однозначно.
Допустим, что ошибки единичные, т.е. в векторе е только одна компонента 1, а остальные 0, и обозначим (h1,...,h6) столбцы матрицы Н6.
|
|
|
|
Дата добавления: 2014-01-13; Просмотров: 664; Нарушение авторских прав?; Мы поможем в написании вашей работы!