КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Распределенная обработка
|
|
|
|
Утилиты
Утилиты – программы, разработанные для АБД и используемые им при решении различных административных задач.
Некоторые утилиты выполняются на внешнем уровне системы и потому представляют собой не что иное, как приложения специального назначения (инструментальные средства). Они могут быть созданы не только поставщиком СУБД, но и сторонними разработчиками программного обеспечения. Однако другие утилиты выполняются на внутреннем уровне (т.е. являются частью сервера) и потому должны предоставляться поставщиком СУБД. Приведем некоторые из утилит различных типов, часто применяемых на практике:
§ Инструменты загрузки. Применяет для создания исходной версии базы данных из одного или более файлов операционной системы.
§ Инструменты выгрузки-перезагрузки. Служат для создания резервных копий хранимых данных и восстановления базы данных из этих копий.
§ Инструменты реорганизации. Применяются для перераспределения данных в хранимой базе данных, которое выполняется по различным причинам (обычно для повышения производительности).
§ Статистические инструменты. Применяются для вычисления различных статистических показателей и показателей производительности, например, сведений о размерах файлов или значениях данных, счетчики операций ввода-вывода и т.п.
§ Инструменты анализа. Используются для анализа данных, собранных статистическими инструментами.
Помимо приведенных классов утилит существует множество других, облегчающих АБД выполнение своих функций.
Ранее уже упоминалось о возможности организации «распределенной обработки», используя коммуникационную сеть. Взаимодействие между различными машинами осуществляется с помощью специального программного обеспечения, предназначенного для управления сетью. Оно может быть некоторым расширением менеджера передачи данных, но чаще всего является отдельным программным компонентом.
|
|
|
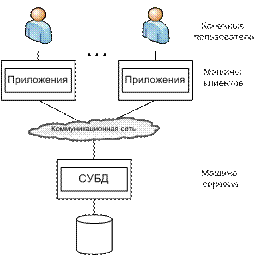
Распределенная обработка может быть самой разнообразной и осуществляться на разных уровнях. В самом простейшем случае сервер СУБД запускается на одной машине, а клиент – на другой (см. рис. 1.5а). Существует множество аргументов в пользу данной архитектуры:
§ Возможность организации параллельной обработки. Поскольку сервер и клиент запускаются на разных машинах, то они работают параллельно, тем самым снижая нагрузку на сервер. В результате время реакции системы на запрос и ее производительности должны улучшиться.
§ Специализация машин. Машина сервера может быть изготовлена по специальному заказу и специально приспособлена для работы с СУБД. Такое решение позволяет дополнительно повысить производительность СУБД. Машина клиента также может представлять рабочую станцию, приспособленную к потребностям конечного пользователя, что позволяет предоставить ему наиболее удобный интерфейс и гарантировать высокий уровень готовности, быструю реакцию системы и другие дополнительные удобства при использовании.
§ Возможность разделения БД. Данная модель может быть использована и для многопользовательских СУБД, когда к машине сервера могут иметь доступ несколько разных клиентов одновременно (см. рис. 1.5б).
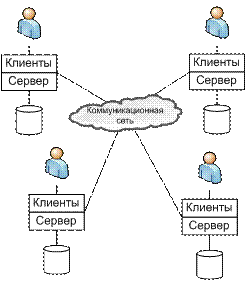
Дальнейшим развитием данной модели является вариант, когда машины могут выступать и как клиенты, и как серверы (см. рис. 1.5в). Данная модель хорошо соответствует принципам работы крупных организаций. В различных частях организации используются в основном свои данные, которые хранятся на выделенном сервере. Но иногда приходится обращаться к данным, которыми располагает другая часть организации. Хотя эти запросы выполняются намного реже, чем к данным своей части организации, эта возможность позволяет поддерживать полную систему баз данных. Таким образом, узлы могут выступать при такой организации предприятия как клиенты и серверы в различные моменты времени.
|
|
|

| 
|
| (а) | (б) |
| |
| (в) |
Рис. 1.5 Варианты распределенной обработки: (а) клиент и сервер запускаются на разных машинах; (б) один сервер и несколько клиентов; (в) каждая машина является и клиентом, и сервером.
Описанная ситуация относится к случаю, когда данные распределены между различными серверами и ни один из них не обладает полным набором данных. При этом доступ клиентов к серверам может осуществляться двумя способами:
§ Клиент может получать доступ к любому количеству серверов, но лишь к одному из них в каждый момент времени. В данной системе невозможно за один запрос получить комбинированные данные от нескольких серверов. Кроме того, пользователь в такой системе должен знать, на какой именно системе содержится конкретная часть БД.
§ Клиент может получать доступ к любому количеству серверов одновременно (т.е. за один запрос получать комбинированные данные от двух и более серверов). В данном случае все серверы рассматриваются клиентами как единый сервер (с логической точки зрения), и пользователь может не знать где расположена та или иная часть БД.
Второй случай – пример системы, которую называют обычно распределенной системой баз данных. Приложение может «прозрачно» обрабатывать данные, распределенные между множеством различных баз данных, управление которыми осуществляют разные СУБД, работающие на соединенных коммуникационной сетью машинах разных типов с различными операционными системами. Здесь понятие «прозрачно» означает, что приложение выполняет обработку данных с логической точки зрения так, как будто управление данными полностью осуществляется одной СУБД, работающей на единственной машине. Производители современных СУБД напряженно работаю, чтобы сделать столь привлекательные с практической точки зрения системы реальностью.
|
|
|
|
Дата добавления: 2014-01-13; Просмотров: 411; Нарушение авторских прав?; Мы поможем в написании вашей работы!