КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция: Оценивание тестирования
|
|
|
|
Любое тестирование должно заканчиваться не только выставлением оценок (баллов), но и анализом результатов тестирования, выявлением уровня обучения и качества тестов.
Оценку результатов тестирования нужно производить баллами в определенной шкале баллов.
Например, 1–2 балла – "цена вопроса" в группе 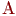 , 2–3 балла – в группе
, 2–3 балла – в группе 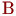 , 3–5 баллов – в группе
, 3–5 баллов – в группе  . Такая оценка может быть переведена в классическую пятибалльную оценку или в другую желаемую шкалу оценок. Это одно из качеств тестирования, повышающих объективность оценки успехов.
. Такая оценка может быть переведена в классическую пятибалльную оценку или в другую желаемую шкалу оценок. Это одно из качеств тестирования, повышающих объективность оценки успехов.
Простейший критерий объективности: ответивших правильно на все вопросы в группе и большую часть в группе – большинство.
Для анализа полезны отборочные тесты с высокой мерой сложности и отсеивающие тесты с низкой мерой сложности.
Если тестирование все же проводится в системе оценок с двумя вариантами ответов ("да", "нет"), то и результат тестирования должен быть оценен в биполярной шкале: "аттестован – не аттестован".
Если при оценке результатов тестирования используются баллы, то их число должно быть нечетным (1–5, 0–10, 1–101 и т. д.). Обычно используют итоговую 100-балльную шкалу.
Хотя первичные баллы могут иметь любое значение, итоговые тестовые баллы должны быть расчитаны по 100-бальной системе.
Величина тестового балла равна проценту успешно выполненного объема теста с учетом всех его особенностей и уровня сложности заданий, входящих в него. Она может рассматриваться как количественная оценка степени усвоения знаний и умений в соответствии с требованиями ГОС, программы, предметной области.
Например, система (шкала) перевода первичных баллов в оценки при приеме в вузы по математике ЕГЭ-2007 имеет следующий вид:
|
|
|
| Первичные баллы | Баллы при приеме в вуз | Оценка |
| 0-6 | 0-35 | |
| 7-12 | 36-54 | |
| 13-18 | 55-73 | |
| 19-30 | 74-100 |
Распределение баллов зависит от процента правильных ответов и может лежать в различных границах, например: "отлично" – более 95% правильных ответов, "хорошо" – 80–94%, "удовлетворительно" – 60–79%, "неудовлетворительно" – менее 60%. К каждой системе такого распределения баллов могут быть предъявлены замечания.
Для измерения "уровня образованности" ("уровня знаний") лучше использовать логарифмическую шкалу, так называемые "логиты". Поясним эту шкалу.
Очень трудные задания снижают учебную мотивацию многих учащихся, как и очень легкие. Поэтому используется шкала, которую ввел датский математик Г. Раш (Г. Раск, G. Rasch), шкала "логитов". По Рашу определены два логита:
1. "логит уровня знаний" – натуральный логарифм отношения доли правильных ответов испытуемого на все задания теста, к доле неправильных ответов;
2. "логит уровня трудности задания" – натуральный логарифм отношения доли неправильных ответов на задание теста к доле правильных ответов на это задание по множеству испытуемых.
Необходимо на всех этапах тестирования учитывать, что первичные баллы – необъективны (в математико-статистическом смысле).
Результаты тестирования могут свидетельствовать иногда и о том, что есть интеллектуально развитые обучаемые, показывающие плохие результаты тестирования, как и слабые обучаемые с так называемым критическим складом ума и хорошей моторной памятью, показывающие неплохие результаты.
Необходимо учитывать дидактическую ограниченность проверки на совпадение с эталоном ответа, особенно, при компьютерной проверке знаний и умений.
Тестирование обычно завершается математико-статистической обработкой данных тестирования.
|
|
|
Рассмотрим вначале некоторые необходимые понятия математической статистики и теории вероятностей.
Пусть задан некоторый статистический ряд из элементов 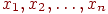 . Если эти элементы могут принимать все мыслимые допустимые значения, а объект с этими характеристиками рассматривается как единый (как система), то такую совокупность называют генеральной совокупностью; часто при этом предполагается, что она является конечной и упорядоченной по возрастанию:
. Если эти элементы могут принимать все мыслимые допустимые значения, а объект с этими характеристиками рассматривается как единый (как система), то такую совокупность называют генеральной совокупностью; часто при этом предполагается, что она является конечной и упорядоченной по возрастанию:  .
.
Любое непустое подмножество генеральной совокупности называется выборкой. Если выборка осуществлена случайным образом, то она называется случайной выборкой.
Средняя величина генеральной совокупности в целом называется общей средней. Она отражает общие черты всей совокупности. Средняя величина для отдельной выборки называется средней по выборке или выборочной средней. Она отражает общие черты группы.
Существуют различные меры средних величин. Чаще используется средняя арифметическая характеристика:

Она называется также выборочной средней или эмпирической средней.
Средняя гармоническая величина, как и средняя арифметическая, может быть простой и взвешенной. Если все веса равны между собой, то можно использовать среднюю гармоническую в виде:
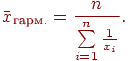
Средняя квадратичная взвешенная величина вычисляется по формуле:

Если веса 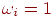 , для всех
, для всех 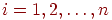 , то получаем просто среднее квадратичное. Эти величины характеризуют "концентрацию" данных выборки около среднего (или другой характерной тенденции).
, то получаем просто среднее квадратичное. Эти величины характеризуют "концентрацию" данных выборки около среднего (или другой характерной тенденции).
К средним величинам, которые характеризуют структурные изменения, относятся мода и медиана. Они определяются лишь структурой распределения.
Мода – наиболее часто встречающееся значение признака у элементов данной совокупности. Она соответствует определенному значению признака.
Медиана - значение признака, которое делит элементы ранжированной выборки на две равные части. Это середина ранжированного ряда.
Исход – одно из возможных заключений о рассматриваемом процессе.
Выборочное пространство – множество всех исходов.
Событие – любое подмножество выборочного пространства. Пустое событие обозначают, как и в теории множеств, символом 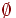 . Событием можно считать и всё выборочное пространство (универсальное событие).
. Событием можно считать и всё выборочное пространство (универсальное событие).
|
|
|
Испытание – проверка всевозможных исходов события.
Два испытания независимы, если любое событие, определённое на основе только одного из них, не зависит от любого события, определённого на основе другого.
Так как событие – это множество, то для них должны быть выполнимы основные операции с множествами: объединение, пересечение и дополнение.
Два события 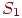 и
и 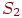 несовместимы, если
несовместимы, если 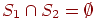 .
.
События и образуют полную группу, если 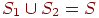 (всему выборочному пространству).
(всему выборочному пространству).
События и – противоположны, если они несовместимы и образуют полную группу.
Пусть 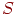 – событие,
– событие, 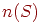 – число случаев (исходов), в которых произошло событие из проведенной серии
– число случаев (исходов), в которых произошло событие из проведенной серии 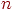 испытаний (в выборочном пространстве). Тогда
испытаний (в выборочном пространстве). Тогда 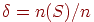 – относительная частота события .
– относительная частота события .
При больших 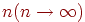 ,
,  . Эта предельная частота называется вероятностью события и обозначается как
. Эта предельная частота называется вероятностью события и обозначается как 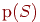 или просто
или просто 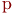 . Всегда
. Всегда 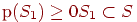 , а
, а 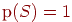 .
.
Важно заметить, что указанный предел не может быть вычислен как предел функции (последовательности), так как её просто нет.
Задача 1.
Пусть теперь даны результаты тестирования группы, состоящей из испытуемых для заданного теста из 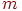 различных знаний. Обычно эти данные представляются в виде некоторой матрицы
различных знаний. Обычно эти данные представляются в виде некоторой матрицы 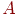 баллов (типа "тестируемый – задание") размерности на :
баллов (типа "тестируемый – задание") размерности на :
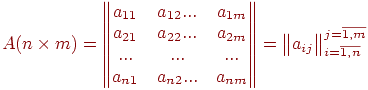
Элемент 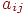 матрицы представляет собой результат выполнения
матрицы представляет собой результат выполнения 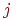 -го задания для
-го задания для 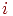 -го тестируемого.
-го тестируемого.
Необходимо на основе имеющихся результатов тестирования для каждого из тестированных, вычислить основные статистические показатели тестирования (оценить "сырые" результаты) для выбранной случайным образом группы тестированных.
Алгоритм решения этой задачи состоит из следующих этапов.
1. Упорядочиваем ряд по возрастанию (находим генеральную совокупность): .
2. Выбираем интересующее нас подмножество тестированных (выборку).
3. Находим среднее арифметическое по выборке
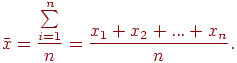
4. Находим среднюю гармоническую величину выборки:
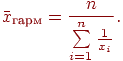
5. Находим величины, характеризующие структурные изменения, например, моду и медиану. Для данных, имеющих "хорошее поведение", медиана всегда лежит в промежутке между средним арифметическим и модой. Эти величины выстраиваются по возрастанию следующим образом (напомним про упорядоченность по возрастанию выборки, предполагаемую нами далее для любого статистического ряда): среднее, медиана, мода, или же в обратном порядке. Прямой или обратный порядок их расположения можно определить, вычислив так называемый коэффициент асимметрии:
|
|
|
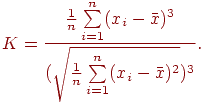
Этот коэффициент отражает относительную изменчивость данных.
6. Находим меры рассеяния, разброса или вариации, показывающие, как остальные элементы совокупности (выборки) группируются около средних величин. Например,
1. размах
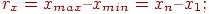
2. среднее абсолютное отклонение
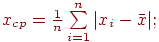
3. среднеквадратичное отклонение

4. дисперсия
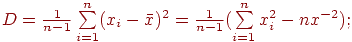
5. стандартное отклонение:
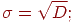
6. коэффициент вариации:
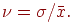
7. Конец алгоритма.
Задача 2.
Даны результаты тестирования для каждого из n тестированных и теста длины в виде матрицы , а также вектор эталонных ответов 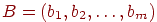 , где
, где 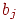 – эталонный ответ на задание номер . Необходимо определить "вес" (меру сложности) конкретного задания теста.
– эталонный ответ на задание номер . Необходимо определить "вес" (меру сложности) конкретного задания теста.
Простейший алгоритм решения этой задачи состоит из следующих этапов.
1. Определяем для очередного задания теста по матрице количество тестированных, давших правильный ответ на данное задание.
2. В качестве "веса" задания берется дробь 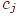 : знаменатель – количество тестированных, числитель – количество тестированных, давших правильные ответы на все задания.
: знаменатель – количество тестированных, числитель – количество тестированных, давших правильные ответы на все задания.
3. Вычисляем смежные веса 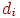 : знаменатель – количество всех тестированных, давших неправильный ответ на данное задание номер , числитель – количество тестированных, давших неправильные ответы на все задания. Иногда в знаменателе берется количество всех тестированных.
: знаменатель – количество всех тестированных, давших неправильный ответ на данное задание номер , числитель – количество тестированных, давших неправильные ответы на все задания. Иногда в знаменателе берется количество всех тестированных.
4. Находится вектор весов выполнения 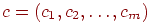 для заданного вектора
для заданного вектора  эталонных ответов.
эталонных ответов.
5. Находим вектор весов невыполнения 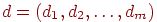 для заданного вектора эталонных ответов.
для заданного вектора эталонных ответов.
6. Оцениваем дисперсию каждого -го задания 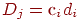 и стандартное отклонение
и стандартное отклонение 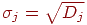 .
.
7. Конец алгоритма.
Задача 3.
Даны результаты тестирования для каждого из тестированных и теста длины в виде матрицы , а также вектор эталонных ответов , где – эталонный ответ на задание номер . Необходимо оценить валидность каждого задания теста.
Простейший алгоритм решения этой задачи состоит из следующих этапов.
1. Определяем для очередного задания теста по матрице количество тестированных, давших правильный ответ на -ое задание и находим их средний балл 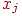 .
.
2. Находим аналогично количество тестированных, давших неправильный ответ на j-ое задание и их средний балл 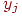 .
.
3. Находим дробь : знаменатель – количество тестированных, давших правильный ответ на данное задание номер , числитель – количество тестированных.
4. Находим дробь : знаменатель – количество тестированных, давших неправильный ответ на данное задание номер , числитель – количество тестированных.
5. Оцениваем дисперсию каждого -го задания и стандартное отклонение .
6. Находим стандартное отклонение 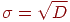 по всему тесту.
по всему тесту.
7. Находим коэффициент корреляции (меру валидности задания):

8. Если 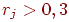 , то задание считаем валидным, иначе – не валидным (отметим, что с точки зрения критериальной валидности, задания, выполненные всеми или невыполненные никем, не являются валидными).
, то задание считаем валидным, иначе – не валидным (отметим, что с точки зрения критериальной валидности, задания, выполненные всеми или невыполненные никем, не являются валидными).
9. Конец алгоритма.
Задача 4.
Даны результаты нормативно-ориентированного тестирования для каждого из тестированных и теста длины в виде матрицы , а также вектор эталонных ответов , где – эталонный ответ на задание номер . Необходимо оценить надежность теста (степень устойчивости результатов тестирования каждого испытуемого, если тестирование было проведено в совершенно одинаковых условиях).
Для вычисления надежности нормативно-ориентированного теста используем коэффициент корреляции между результатами двух параллельных тестов. Сравнивая коэффициенты корреляции, делаем заключение о надежности (внутренней) теста. Если две половины теста коррелированны, то и тест надёжен; в противном случае – не надёжен (или необходимо применить другой, более тонкий математический аппарат исследования надежности).
Простейший алгоритм решения этой задачи состоит из следующих этапов.
1. Делим тест на две равные части 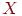 и
и 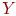 , например, по четным и нечетным номерам заданий. Этот метод называется методом расщепления теста. Таким образом, мы имеем данные по двум параллельным тестам и – индивидуальные баллы
, например, по четным и нечетным номерам заданий. Этот метод называется методом расщепления теста. Таким образом, мы имеем данные по двум параллельным тестам и – индивидуальные баллы 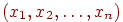 ,
, 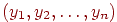 , где – количество тестированных.
, где – количество тестированных.
2. Для каждого задания группы выполняем предыдущий алгоритм.
3. Для каждого задания группы выполняем предыдущий алгоритм.
4. Находим коэффициент корреляции и по формуле:
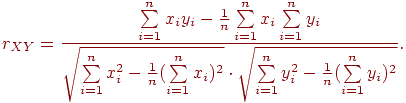
5. Находим надежность 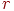 всего теста по формуле (Спирмена-Брауна):
всего теста по формуле (Спирмена-Брауна):

6. Конец алгоритма.
Задача 5.
Необходимо на основе имеющихся результатов тестирования (матрица ) получить для каждого из тестированных интегральный (обобщенный) показатель выполнения теста длины , а затем по вычисленным значениям этого интегрального показателя разбить всех тестированных на заданное количество 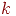 групп (задача классификации).
групп (задача классификации).
Алгоритм решения этой задачи состоит из следующих этапов.
1. Если для -го задания увеличение значений результатов измерения свидетельствует об улучшении соответствующего свойства, то с ним свяжем признак 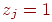 , а если свидетельствует об ухудшении – признак
, а если свидетельствует об ухудшении – признак 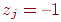 .
.
2. Выполняем нормирование элементов исходной матрицы так, чтобы в каждом столбце они изменялись в "одном направлении": для каждого задания (при фиксированном 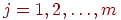 ) и для каждого испытуемого вычислим новое значение
) и для каждого испытуемого вычислим новое значение
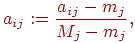
где 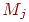 ,
, 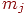 – наибольшее и наименьшее значения элементов -го столбца и применяем преобразование вида
– наибольшее и наименьшее значения элементов -го столбца и применяем преобразование вида
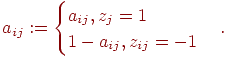
3. Для каждого столбца полученной новой матрицы (нормированной) вычисляется среднее квадратичное отклонение по формуле
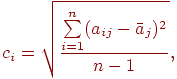
где 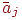 – среднее арифметическое элементов -го столбца.
– среднее арифметическое элементов -го столбца.
4. Вычисляется классификационный интегральный показатель
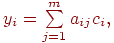
где 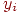 – значение интегрального показателя для -го обучаемого
– значение интегрального показателя для -го обучаемого 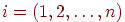 , – весовой коэффициент -го задания в тесте или в банке всех заданий, – элемент матрицы или его преобразованное (нормированное, например, по отношению к максимальному элементу или к норме матрицы).
, – весовой коэффициент -го задания в тесте или в банке всех заданий, – элемент матрицы или его преобразованное (нормированное, например, по отношению к максимальному элементу или к норме матрицы).
5. Находим наименьшее 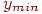 и наибольшее
и наибольшее  значения интегрального показателя (по всем тестированным). Отрезок
значения интегрального показателя (по всем тестированным). Отрезок 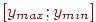 делим на заданное число интервалов. Часто берут (при построении, например, гистограммы)
делим на заданное число интервалов. Часто берут (при построении, например, гистограммы) 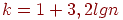 . Всех тестированных, для которых вычисленные значения интегрального показателя попадают в один и тот же интервал, отождествляем и относим к одному классу.
. Всех тестированных, для которых вычисленные значения интегрального показателя попадают в один и тот же интервал, отождествляем и относим к одному классу.
6. Выдаем результаты: значения интегрального показателя для каждого тестированного, а также его класс (или классификацию тестированных по интегральному показателю).
7. Конец алгоритма.
Задача 6.
Дана интегральная норма 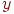 тестовых результатов. Необходимо разбить группу тестированных на несколько групп по их интегральным показателям (по отношению их к норме).
тестовых результатов. Необходимо разбить группу тестированных на несколько групп по их интегральным показателям (по отношению их к норме).
Приведем простейший алгоритм решения этой задачи.
Первый алгоритм решения этой задачи состоит из следующих этапов.
1. Ввод входных данных: 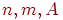 .
.
2. Для каждого тестированного определяем суммарный балл:
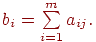
3. Разбиваем всю выборку тестированных на три группы: группа 1 с высокими баллами (нижняя граница суммарного балла для попадающих в эту группу равна 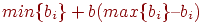 , группа 2 со средними баллами и группа 3 с низкими баллами (верхняя граница суммарного балла для попадающих в эту группу равна
, группа 2 со средними баллами и группа 3 с низкими баллами (верхняя граница суммарного балла для попадающих в эту группу равна 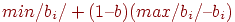 , где – масштабирующий коэффициент,
, где – масштабирующий коэффициент, 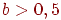 .
.
4. Конец алгоритма.
Задача 7.
Необходимо отсеять первичные ("сырые") результаты в группах, т.е. по данным (процент выполнения, валидность и т.д.) выяснить задания (тесты, результаты), которые не согласуются с общей картиной тестирования.
Алгоритм решения задачи состоит из следующих этапов.
1. Вычисляется средняя величина
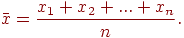
2. Вычисляются наибольшее 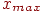 и наименьшее
и наименьшее  в группе.
в группе.
3. Вычисляются наибольшее отклонение в группе:
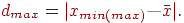
4. Вычисляется относительное отклонение:
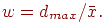
5. Находим по таблице распределения Стьюдента процентные точки для 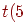 и
и 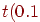 . Таблица Стьюдента имеется практически во всех справочниках по математической статистике.
. Таблица Стьюдента имеется практически во всех справочниках по математической статистике.
6. Вычисляем соответствующие точки 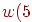 ,
, 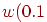 .
.
7. Если , то отсеиваем рассматриваемое данное и пересчитываем все заново (повторяем заново пункты 1-6).
8. Конец алгоритма.
|
|
|
|
|
Дата добавления: 2014-01-13; Просмотров: 495; Нарушение авторских прав?; Мы поможем в написании вашей работы!