КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Организация когерентности многоуровневой иерархической памяти
|
|
|
|
Понятие когерентности кэшей описывает тот факт, что все центральные процессоры получают одинаковые значения одних и тех же переменных в любой момент времени. Действительно, поскольку кэш-память принадлежит отдельному компьютеру, а не всей многопроцессорной системе в целом, данные, попадающие в кэш одного компьютера, могут быть недоступны другому. Чтобы этого избежать, следует провести синхронизацию информации, хранящейся в кэш-памяти процессоров.
Для обеспечения когерентности кэшей существует несколько возможностей:
- использовать механизм отслеживания шинных запросов (snoopy bus protocol), в котором кэши отслеживают переменные, передаваемые к любому из центральных процессоров и при необходимости модифицируют собственные копии таких переменных;
- выделять специальную часть памяти, отвечающую за отслеживание достоверности всех используемых копий переменных.
Наиболее известными системами архитектуры cc-NUMA являются: HP 9000 V-class в SCA-конфигурациях, SGI Origin3000, Sun HPC 15000, IBM/Sequent NUMA-Q 2000. На сегодня максимальное число процессоров в cc-NUMA-системах может превышать 1000 (серия Origin3000). Обычно вся система работает под управлением единой ОС, как в SMP. Возможны также варианты динамического "подразделения" системы, когда отдельные "разделы" системы работают под управлением разных ОС. При работе с NUMA-системами, так же, как с SMP, используют так называемую парадигму программирования с общей памятью (shared memory paradigm).
4. PVP (Parallel Vector Process) – параллельная архитектура с векторными процессорами
Основным признаком PVP-систем является наличие специальных векторно-конвейерных процессоров, в которых предусмотрены команды однотипной обработки векторов независимых данных, эффективно выполняющиеся на конвейерных функциональных устройствах. Как правило, несколько таких процессоров (1-16) работают одновременно с общей памятью (аналогично SMP) в рамках многопроцессорных конфигураций. Несколько узлов могут быть объединены с помощью коммутатора (аналогично MPP). Поскольку передача данных в векторном формате осуществляется намного быстрее, чем в скалярном (максимальная скорость может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах), то проблема взаимодействия между потоками данных при распараллеливании становится несущественной. И то, что плохо распараллеливается на скалярных машинах, хорошо распараллеливается на векторных. Таким образом, системы PVP-архитектуры могут являться машинами общего назначения (general purpose systems). Однако, поскольку векторные процессоры весьма дорого стоят, эти машины не могут быть общедоступными.
Наиболее популярны три машины PVP-архитектуры:
1. CRAY X1, SMP-архитектура. Пиковая производительность системы в стандартной конфигурации может составлять десятки терафлопс.
 Рис. 4.4. CRAY SV-2
2. NEC SX-6, NUMA-архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
3. Fujitsu-VPP5000 (vector parallel processing), MPP-архитектура. Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт. Система масштабируется до 512 Рис. 4.4. CRAY SV-2
2. NEC SX-6, NUMA-архитектура. Пиковая производительность системы может достигать 8 Тфлопс, производительность одного процессора составляет 9,6 Гфлопс. Система масштабируется с единым образом операционной системы до 512 процессоров.
3. Fujitsu-VPP5000 (vector parallel processing), MPP-архитектура. Производительность одного процессора составляет 9.6 Гфлопс, пиковая производительность системы может достигать 1249 Гфлопс, максимальная емкость памяти – 8 Тбайт. Система масштабируется до 512
 Рис. 4.5. Fujitsu-VPP5000
Парадигма программирования на PVP-системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
На практике рекомендуется выполнять следующие процедуры: Рис. 4.5. Fujitsu-VPP5000
Парадигма программирования на PVP-системах предусматривает векторизацию циклов (для достижения разумной производительности одного процессора) и их распараллеливание (для одновременной загрузки нескольких процессоров одним приложением).
На практике рекомендуется выполнять следующие процедуры:
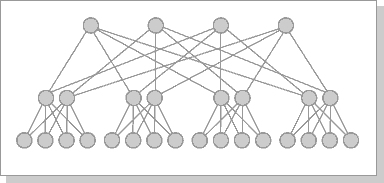 Рис. 4.7. Кластерная архитектура "Fat-tree"
Поскольку способ соединения процессоров друг с другом больше влияет на производительность кластера, чем тип используемых в ней процессоров, то может оказаться более целесообразным создать систему из большего числа дешевых компьютеров, чем из меньшего числа дорогих. В кластерах, как правило, используются операционные системы, стандартные для рабочих станций, чаще всего свободно распространяемые (Linux, FreeBSD), вместе со специальными средствами поддержки параллельного программирования и балансировки нагрузки. При работе с кластерами, так же, как и с MPP-системами, используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (чаще всего – MPI). Умеренная цена подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач. Рис. 4.7. Кластерная архитектура "Fat-tree"
Поскольку способ соединения процессоров друг с другом больше влияет на производительность кластера, чем тип используемых в ней процессоров, то может оказаться более целесообразным создать систему из большего числа дешевых компьютеров, чем из меньшего числа дорогих. В кластерах, как правило, используются операционные системы, стандартные для рабочих станций, чаще всего свободно распространяемые (Linux, FreeBSD), вместе со специальными средствами поддержки параллельного программирования и балансировки нагрузки. При работе с кластерами, так же, как и с MPP-системами, используют так называемую Massive Passing Programming Paradigm – парадигму программирования с передачей данных (чаще всего – MPI). Умеренная цена подобных систем оборачивается большими накладными расходами на взаимодействие параллельных процессов между собой, что сильно сужает потенциальный класс решаемых задач.
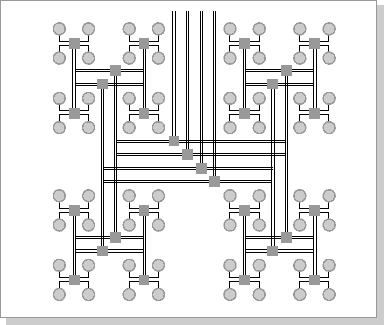 Рис. 4.8. Кластерная архитектура "Fat-tree" (вид сверху на предыдущую схему) Рис. 4.8. Кластерная архитектура "Fat-tree" (вид сверху на предыдущую схему)
|
|
|
|
|
|
|
|
|
|
|
|
|
Литература:
1. Основные классы современных параллельных компьютеров, Лаборатория НИВЦ МГУ http://www.parallel.ru/computers/classes.html
2. Э. Таненбаум Распределенные системы: принципы и парадигмы. – СПб: Питер, 2003. – 877 с.
3. Информационный Интернет-канал с рейтингом 500 наиболее производительных компьютерных систем в мире http://www.top500.org.
4. Шпаковский Г.И. Организация параллельных ЭВМ и суперскалярных процессоров. Учебное пособие.- Мн.: Белгосуниверситет, 1996. — 296 с.
5. Hockney R. W., Jesshope C.R. Parallel Computers 2. Architecture, Programming and Algorithms. - Adam Hilger, Bristol and Philadelphia, 1988. (русский перевод 1 издания: Р.Xокни, К.Джессхоуп. Параллельные ЭВМ. Архитектура, программирование и алгоритмы. - М.: Радио и связь, 1986)
6. Гергель В.П., Стронгин, Р.Г. Основы параллельных вычислений для многопроцессорных вычислительных систем. Учебное пособие – Нижний Новгород: Изд-во ННГУ им. Н.И. Лобачевского, 2003. 184 с.
7. Архитектуры и топологии многопроцессорных вычислительных систем. Курс лекций. Учебное пособие / А.В.Богданов, В.В.Корхов, В.В.Мареев, Е.Н.Станкова.- М. «ИНТУИТ», 2004.- 176 с.
|
|
|
|
|
Дата добавления: 2014-01-14; Просмотров: 631; Нарушение авторских прав?; Мы поможем в написании вашей работы!