КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Процессор пересылок
|
|
|
|
Способы организации высокопроизводительных процессов
В данной лекции рассматриваются математические основы, способы организации и особенности проектирования современных процессоров на основе архитектуры пересылок, ассоциативной памяти, потоковой обработки, транскомпьютерной орг-ции вычислений.
План:
1. Процессоры пересылок.
2. Ассоциативные процессоры.
3. Потоковые процессоры.
4. Транскопмьютеры.
1.1 Иерархия памяти в классической архитектуре
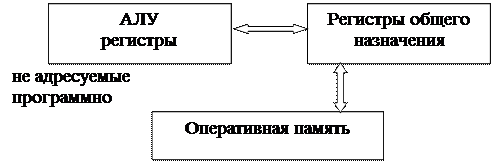
Классические принципы построения процессора предусматривают наличие развитой иерархии памяти, в которой внутренние регистры АЛУ не адресуются программой, быстрая память процессора представлена регистрами общего назначения с собственной адресацией, а выборка команд и данных происходит из оперативной памяти, имеющей сквозную адресацию. Схематично эта иерархия представлена на рис 6.1. В неймановских машинах пересылки данных между процессором и памятью выполняются довольно часто и поочередно, а так как ширина канала пересылки мала, то здесь образуется
|
Фон - Неймановская иерархия памяти
Рис 6.1
С другой стороны иерархия памяти приводит к тому, что в машинной команде применяется много разных способов адресации, при этом разные уровни иерархии рассматриваются логически как разные устройства.
1.2 Организация памяти в процессоре пересылок
Основной идеей разработчиков процессора пересылок был отказ от классической иерархии памяти в пользу логического объединения адресного пространства. Эта идея получила название сквозной адресации. При этом разная память может представлять собой физически различные устройства, но с точки зрения устройства управления процессором - это единое адресное пространство, имеющее единый способ адресации в машинной команде и каждый элемент такой сквозной памяти является программно доступным.
|
|
|
Таким образом, с точки зрения машинной команды можно единым образом адресовать и обращаться, как к специальным регистрам управления процессором, внутренним регистрам схем выполнения машинных команд АЛУ, регистрам общего назначения (РОН), так и к словам оперативной памяти (ОП). Схема сквозного адресного пространства представлена на рис 6.2.
 |
Сквозное адресное пространство в процессоре пересылок
Рис 6.2
Такой подход к организации памяти порождает и специфический подход к организации работы процессора и механизму выполнения машинных команд.
1.3 Организация процессора пересылок
1.3.1 Адресная фиксация схем исполнения машинных команд
С учетом механизма сквозной адресации следующей идеей разработчиков было распределение схем выполнения машинных команд АЛУ со своими собственными регистрами операндов и результатов по фиксированным адресам сквозной памяти.
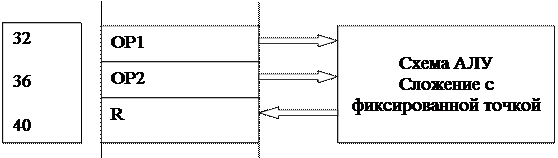 |
Адресная фиксация схемы АЛУ
Рис 6.3
Например, схема сложения чисел с фиксированной точкой, обладающая собственными регистрами двух операндов и регистром результата оказывалась фиксированной в определенных адресах сквозной памяти, а именно в тех, которые назначались для регистров этой схемы. Вариант такой фиксации схемы АЛУ приведен на рис 6.3.
Таким образом, область сквозного адресного пространства, соответствующая входным/выходным регистрам схем АЛУ оказывалась жестко разделена и закреплена за соответствующими схемами и за машинными командами.
1.3.2 Механизм запуска машинной команды

Механизм запуска машинной команды предусматривал пересылку операндов в соответствующие входные регистры исполнительной схемы, что в принятой системе сквозной адресации реализовывалось пересылкой содержимого из одного слова памяти в другое. Именно этот механизм и дал название данной архитектуре - «процессор пересылок». Поскольку каждая машинная команда оказывалась жестко закрепленной за фиксированными адресами сквозной памяти, то запуск той, или иной операции был связан только с адресами расположения соответствующих входных регистров (рис 6.4).
|
|
|
Для синхронизации процесса выполнения машинных команд внутри схем АЛУ предусматривались биты готовности операндов, которые устанавливались в «1» после пересылки операнда команды. Наличие всех необходимых операндов запускало по схеме «И» выполнение команды, после чего результат помещался схемой в выходной регистр, а биты готовности операндов сбрасывались в «0». Во время выполнения очередной команды УУ задерживало следующую команду пересылки до появления результата в выходном регистре.
Запуск машинной команды в процессоре пересылок
Рис 6.4
1.4 Пример программы в процессоре пересылок
Рассмотрим фрагмент программы процессора пересылок для вычисления следующего арифметического выражения, в рамках стандартного понимания символических имен:
Y = ((a+b)*(c+d))
Будем считать, что схемы АЛУ для операций с плавающей точкой фиксированы на следующие адреса сквозной памяти (операнд 1, операнд 2, результат), а сами операнды имеют длину в 4 байта:
Сложение - 64, 68, 72;
Умножение - 76, 80, 84;
Фрагмент программы (операция пересылки справа на лево):
64, a; (пересылка первого операнда для сложения)
68, b; (пересылка второго операнда для сложения)
(выполнение команды сложения - результат по адресу 72)
64, 76; (пересылка результата, как операнда для умножения)
64, c; (пересылка первого операнда для сложения)
68, d; (пересылка второго операнда для сложения)
(выполнение команды сложения - результат по адресу 72)
64, 80; (пересылка результата, как операнда для умножения)
(выполнение команды умножения - результат по адресу 84)
Y, 84; (пересылка результата в оперативную память)
1.5 Реализация перехода по адресу и сравнения
Реализация операции сравнения в процессоре пересылок аналогично обычным арифметическим операциям - схемы сравнения фиксированы на определенные адреса сквозной памяти, но в поле результата схема помещает «0» или «1», в зависимости от результата сравнения операндов. Эта реализацию проиллюстрирована на рис 6.5 слева.
|
|
|
Более интересно реализован механизм выполнения команды перехода по адресу. Регистр адреса команды УУ так же является словом в едином адресном пространстве (и следовательно доступен программисту!) и расположен по адресу «0». По адресу «4» расположено поле смещения, которое или вычисляется компилятором, и следовательно расположено в области загруженной программы, или вычисляется в программе. Со словами по адресам «0», «4» и «8» коммутирована схема целочисленного сложения. При установке битов готовности операндов, т. е. после пересылки смещения и результата сравнения, эта схема выполняет сложение смещения и текущего адреса команды, при условии, что слово по адресу «8» содержит «1», т.е. при истинности результата сравнения - рис 6.5 справа. Поскольку это приводит к модификации текущего адреса команды, то тем самым процессор выполняет переход на другую команду в программе.
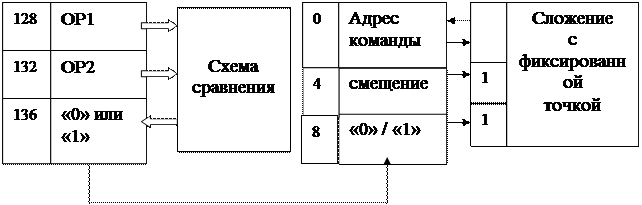
Реализация сравнения и перехода по адресу в процессоре пересылок
Рис 6.5
1.6 Замечания по реализации процессора пересылок
Основным достоинством данной архитектуры является независимость устройства управления от набора машинных команд и возможность универсально расширять этот набор путем включения регистров исполнительной схемы команды в сквозную память процессора. Недостатки архитектуры связаны с большим объемом пересылок данных, однако определенная часть этих пересылок - пересылки между регистрами схем АЛУ. Очевидно, что должны быть приняты определенные решения по гибкой адресации операндов ОП, что приводит к введению регистров базы и индекса.
Эта архитектура нашла свое применение в ряде специализированных процессоров, например в TMS 320 - процессоре обработки сигналов.
|
|
|
|
|
Дата добавления: 2014-01-14; Просмотров: 848; Нарушение авторских прав?; Мы поможем в написании вашей работы!