КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Потоковые процессоры (векторные, суперскалярные)
|
|
|
|
Потоковыми называют процессоры, в основе работы которых лежит принцип обработки многих данных с помощью одной команды. Согласно классификации Флинна, они принадлежат к SIMD (single instruction stream / multiple data stream) архитектуре. Технология SIMD позволяет выполнять одно и то же действие, например, вычитание и сложение, над несколькими наборами чисел одновременно. SIMD-операции для чисел двойной точности с плавающей запятой ускоряют работу ресурсоемких приложений для создания контента, трехмерного рендеринга, финансовых расчетов и научных задач. Кроме того, усовершенствованы возможности 64-разрядной технологии ММХ (целочисленных SIMD-команд); эта технология распространена на 128-разрядные числа, что позволяет ускорить обработку видео, речи, шифрование, обработку изображений и фотографий. Потоковый процессор повышает общую производительность, что особенно важно при работе с ЗD-графическими объектами.
Может быть отдельный потоковый процессор (Single-streaming processor — SSP) и многопотоковый процессор (Multi-Streaming Processor - MSP).
Ярким представителем потоковых процессоров является семейство процессоров Intel, начиная с Pentium III, в основе работы которых лежит технология Streaming SIMD Extensions (SSE, потоковая обработка по принципу «одна команда — много данных»). Эта технология позволяет выполнять такие сложные и необходимые в век Internet задачи как обработка речи, кодирование и декодирование видео- и аудиоданных, разработка трехмерной графики и обработка изображений.
Представителями класса SIMD считаются матрицы процессоров: ILLIAC IV, ICL DAP, Goodyear Aerospace MPP, Connection Machine 1 и т.п. В таких системах единое управляющее устройство контролирует множество процессорных элементов. Каждый процессорный элемент получает от устройства управления в каждый фиксированный момент времени одинаковую команду и выполняет ее над своими локальными данными.
|
|
|
Другими представителями SIMD-класса являются векторные процессоры, в основе которых лежит векторная обработка данных. Векторная обработка увеличивает производительность процессора за счет того, что обработка целого набора данных (вектора) производится одной командой. Векторные компьютеры манипулируют массивами сходных данных подобно тому, как скалярные машины обрабатывают отдельные элементы таких массивов. В этом случае каждый элемент вектора надо рассматривать как отдельный элемент потока данных. При работе в векторном режиме векторные процессоры обрабатывают данные практически параллельно, что делает их в несколько раз более быстрыми, чем при работе в скалярном режиме. Максимальная скорость передачи данных в векторном формате может составлять 64 Гбайт/с, что на 2 порядка быстрее, чем в скалярных машинах. Примерами систем подобного типа являются, например, процессоры фирм NEC и Hitachi.
1. Исторически в больших ЭВМ и ПЭВМ наибольшее распространение получила система команд типа CISC (Complex Instruction Set Computer), содержавшая большое количество команд. Основой этой системы команд являлся формат
КОП R1, D2 (В2) (4.1)
где КОП представлял арифметико-логическую операцию в АЛУ, а второй адрес содержал обращение в память с базой или индексом B 2 и смещением D 2. Такая команда требовала многотактного выполнения.
2. Сокращенная система команд типа RISC (Redused Instruction Set Computer) более перспективна для параллельных процессоров, поскольку число команд в ней меньше и вследствие их простоты большинство команд можно реализовать аппаратно и выполнить за один такт.
Сокращение числа команд в RISC -системе достигается за счет разбиения формата (4.1) на два более простых формата:
|
|
|
Чт, Зп, Ri, D2 [B2] (4.2)
КОП Ri, Rj
Первый формат предназначен только для работы с памятью, второй — только для работы с АЛУ.
Если предположить, что имеется k кодов операций для работы с памятью и l кодов — для работы с АЛУ, то система команд типа CISC должна содержать k * l команд формата (4.1), а система RISC — только k+l команд. Следовательно, отказ от формата (4.1) значительно сокращает список системы команд.
3. Последующее упрощение системы команд достигается при переходе к типу MISC (Minimum Instruction Set Computer), в котором команда формата (4.2) разбивается на две команды:
Rk = В2 + D2 (4.3)
Чт, Зп, Ri, [Rk] (4.4)
где команда (4.3) выполняет индексную операцию, а команда (4.4) — упрощенное обращение в память.
Для иллюстрации особенностей построения суперскалярных систем в качестве базовой используется архитектура суперскалярного процессора Пентиум фирмы Intel с системой команд типа CISС. Вызвано это следующими причинами:
· суперскалярная организация процессора Пентиум достаточно проста для изучения, однако в ней отражены все особенности построения суперскалярных систем;
· система команд процессора Пентиум практически совпадает с системой команд широко известного семейства микропроцессоров i 80´86, поэтому примеры программ легко воспринимаются;
· наконец, в процессоре Пентиум на программном и аппаратном уровне принято ряд решений, приближающих его архитектуру к архитектуре RISC -процессоров, позволяющих, однако, сохранить программную совместимость с большим объемом ранее написанного прикладного матобеспечения.
Появление в структуре процессора более одного конвейера делает этот процессор суперскалярным. Также Mororola, Alpha, Sun, Dec, HP, IBM.
Процессоры с универсальным набором команд
В связи с необходимостью решения различных прикладных задач на ЭВМ общего назначения, уже начиная с машин второго поколения отчетливо наметилась тенденция к созданию универсального набора команд. Такой универсальный набор охватывал как разнообразные форматы данных, т.е. количество занимаемых объектом битов, так и различные типы данных, т.е. внутреннюю структуру формата данных. Наиболее широко используемые в рамках универсальных ЭВМ форматы и типы приведены в таб. 7.1.
Таблица 7.1 Форматы и типы данных
|
|
|
| Форматы | Типы |
| ® полуслово | числа с фиксированной точкой числа с плавающей точкой числа в двоично - десятичном представлении |
| ® слово | |
| ® двойное слово | |
| ® длинное слово |
Идея универсального набора команд предполагала самостоятельную реализацию одинаковой обработки, например сложения, для разных форматов и типов в виде отдельных машинных команд. Таким образом возникало несколько машинных команд (до 10 и более) для одной операции обработки, в результате чего общий набор машинных команд имел порядок 150 - 200.
Такие процессоры получили название «CISC процессоры», т.е. процессоры с универсальным или общим набором команд.
RISC – процессоры
Для быстрого выполнения программы, написанной на языке высокого уровня, не нужны сложные машинные команды - гораздо более важно сократить время выполнения наиболее часто используемых команд. Этот принцип был положен в основу RISC-архитектуры, которая представляет собой улучшенный вариант неймановской архитектуры. Благодаря сокращению набора команд упрощаются аппаратные схемы, а значит, обеспечивается оптимизация выполнения часто используемых команд. Кроме того, за счет применения большого числа регистров уменьшается частота (число) доступов к памяти, что также позволяет повысить скорость выполнения команды.
Таким образом основная идея RISC процессоров – малый фиксированный набор быстрых команды позволяет не только резко сократить набор машинных команд, отметим, что сокращение до 32 команд сокращает так же до 5 битов длину кода операции, но и сократить набор схем, реализующих команды, что позволяет при той же степени интеграции СБИС увеличить количество регистров и объем кэш-памяти.
Типичные представители этих машин: компьютер RISC Калифорнийского университета в Беркли, IBM 801, MIPS Станфордского университета, μ3L Университета шт. Юта, RIDGE 32 - фирмы Midge, Pyramid 90X фирмы Pyramid и др. RISC-архитектуру имеет и транспьютер фирмы «Инмос» - 32-разрядный процессор, спроектированный с оптимальным набором команд, позволяющим использовать язык высокого уровня Оккам.
|
|
|
Теговые машины (самостоятельно)
Одним из факторов, усложняющих разработку программного обеспечения, является наличие большого различия между понятиями операций и их объектов на языке программирования высокого уровня и понятиями операций и их объектов, определяемыми архитектурой компьютера. Это отличие носит название семантического разрыва. Иначе говоря, если на языке высокого уровня можно описать различные операции и типы данных, то в неймановской архитектуре разницы между программами и данными нет, как нет и разницы между типами данных. Это обстоятельство тяжелым бременем ложится на плечи программиста при составлении программы. И впоследствии оно является причиной усложнения отладки программы. Из-за отсутствия различий в типах данных и между программами и данными нельзя обнаружить, была ли ошибка связана с выполнением команды или с обращением к данным. Нельзя также обнаружить, выполняются ли данные в качестве команды или что к команде осуществляется обращение, как к данным.
Для решения этой проблемы Илифф предложил с помощью некоторого алгоритма добавлять ко всем данным информацию, необходимую для того, чтобы идентифицировать их как данные, использовать вместо линейного адресного пространства памяти структурированное пространство и добавлять к каждому элементу памяти информацию, показывающую атрибут этого элемента. Эта дополнительная информация получила название «тег». Машины, основанные на этом принципе, называют теговыми машинами. Так, различные типы данных характеризуются своими тегами, а однотипные команды, отличающиеся только типами операндов, никак не различаются. Например, программисту нет необходимости различать команды ADD (сложения) с плавающей и фиксированной запятой, как в CISC процессорах: машина это сделает автоматически, проверив типы операндов. В случае обращения с массивами данных добавляется такая теговая информация, как длина, ширина массива, индексы, а выход за пределы массива автоматически контролируется машиной при обращении к данным.
Майерс предложил проект SWARD - машины, в которой идеи теговых машин получили свое дальнейшее развитие.
В SWARD-машине данные представлены структурным элементом, называемым ячейкой. На рис. 7.1 приведен пример ячейки. Каждая ячейка состоит из поля тега и поля данных. Численные значения представлены в двоично-десятичном коде, и один разряд десятичного числа представлен четырьмя двоичными разрядами (битами). Память разбита на 4-разрядные единицы, которые называются признаками. Разрядность данных, указанных в поле тега, выражается числом признаков. Положительный знак числа выражается кодом 0000, отрицательный - 0001. Если используются массивы данных, то в поле тега указываются размерность массива, тип ячейки элемента массива, длина каждого измерения. Если элементом массива является целое число, то к типу ячейки после 1111 добавляется информация о длине числа. В SWARD-машине теговая информация используется не только применительно к данным, но и применительно к программным модулям.
 |
Представление данных в теговых машинах
Рис 7.1
Гарвардская архитектура (самостоятельно)
Еще одна архитектурная идея, связанная с преодолением проблемы семантического разрыва, но теперь в части неразличимости программы и данных, основывается на физическом разделении оперативной памяти на два независимых блока с собственными устройствами управления. Предложенная в Гарвардском университете она получила название «Гарвардская архитектура». Схема такого процессора приведена на рис 7.2
Схема процессора с гарвардской архитектурой
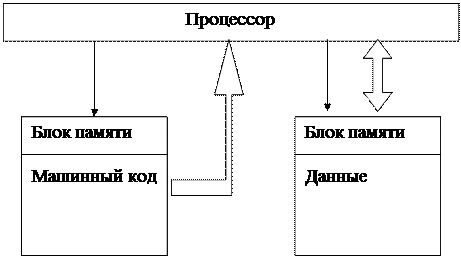 |
Рис 7.2
Два блока оперативной памяти для хранения программы и данных могут работать параллельно, что важно для конвейерной организации самого процессора. Для предотвращения возможности модификации программы во время выполнения (самомодифицируемые программы), что иногда активно использовалось при программировании в фон-неймановских процессорах, аппаратно запрещена операция записи в область машинного кода.
Такой подход к организации памяти широко используется в настоящее время в микропроцессорах, и в процессорах специального назначения, где чрезвычайно важно сохранить целостность программы, даже при возникновении аппаратной ошибки.
|
|
|
|
|
Дата добавления: 2014-01-14; Просмотров: 1787; Нарушение авторских прав?; Мы поможем в написании вашей работы!