КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Методы доступа к данным
|
|
|
|
Метод доступа к данным – это совокупность технических и программных средств, обеспечивающих возможность хранения и выборки данных, расположенных на физических устройствах. В методе доступа важны два компонента: структура памяти и механизм поиска. Структура памяти – представление хранимых записей, составляющих файл и т.д. Механизм поиска – алгоритм, определяющий путь доступа, который возможен в рамках заданной структуры памяти, и количество шагов вдоль этого пути для нахождения искомых данных.
Выделяют три основных группы методов доступа к данным: последовательные, индексные, произвольные методы доступа. Последовательные методы используются при поиске большого числа записей (от 10 до 100%), индексные для получения одной или нескольких записей, произвольные для получения отдельных записей.
В группе последовательных методов доступа к данным используется один файл базы данных. Перебор записей выполняется, начиная с первой, последовательно одна за другой. Записи не упорядочены и обычно имеют фиксированный размер. В зависимости от способа организации записей в файле различают последовательный метод доступа на смежной и несмежной памяти.
а) В случае последовательного метода доступа на смежной памяти записи хранятся в виде логической последовательности, организация которой похожа на одномерный линейный массив. Например, в файле хранятся имена:
| Лена | Катя | Ира | Света | Галя |
При поиске записи, например со значением «Ира», поиск начинается с первой записи до тех пор, пока не будет, найдена нужная запись или не будет, достигнут конец файла. При добавлении новой записи запись добавляется в конец файла. При удалении записи сначала осуществляется её поиск, затем начиная со следующей, записи по одной записи последовательно переписываются на предыдущее место, после чего самая последняя запись файла удаляется. Либо все записи, начиная со следующей после удаляемой, переписываются в новый файл и все записи из него записываются в исходный файл, начиная с указателя на удаляемую запись, а конечная запись удаляется. При изменении записи сначала выполняется последовательный поиск нужной записи, затем удаляется и добавляется новая запись
|
|
|
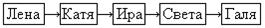 |
б) В случае последовательного метода доступа на несмежной памяти записи хранятся в виде линейного списка. В данном случае невозможно использование бинарного поиска, т.к. данные не упакованы плотно и отсутствует возможность вычисления промежуточных адресов.
Все алгоритмы при работе с линейными списками хорошо изучены и реализованы. При поиске нужной записи осуществляется проход по списку, начиная с первого элемента, пока не будет найден нужный элемент списка. Для внесения изменения в некоторое информационное поле записи файла осуществляется последовательный перебор элементов списка с последующим исправлением информационного поля нужного элемента списка. При удалении, после того как нужный элемент найден, указатель на удаляемый элемент переносится на следующий за ним элемент, а от самого удаляемого элемента освобождается память. При добавлении новый элемент добавляется в конец списка.
В группе индексных методов доступа все действия с записями осуществляются при наличии двух файлов – индексного и основного файла базы данных. В индексном файле хранятся значения первичных ключей основного файла базы данных и адреса или указатели на записи основного файла с соответствующими значениями первичного ключа. Индексный файл всегда упорядочен по значениям ключей и, соответственно поиск в нём осуществляется быстрыми методами поиска. Индексный файл значительно меньше собственно базы данных. В зависимости от способа организации индексного файла и основного файла базы данных имеется множество разновидностей индексных методов доступа. Некоторые из них рассмотрены ниже.
|
|
|
 |
В индексно-последовательном методе доступа индексный файл всегда упорядочен по первичному ключу (главному атрибуту физической записи), по значению которого идентифицируется физическая запись. Индексный файл содержит ссылки не на каждую запись базы данных, а на группу записей, хранимых в физическом блоке, по диапазону ключей. Например, если в блоке хранится 10 записей, то для него в индексном файле будет одна статья, а не 10, и размер индексного файла уменьшится в 10 раз. Таким образом, индексно-последовательный метод доступа строится на основе упорядоченного физически файла и иерархической структуры индексов блоков, каждый из которых упорядочен по значениям первичных ключей подобно записям в файле данных. Каждое значение ключа в индексе некоторого j-уровня представляет собой наибольшее значение ключа в блоке индекса или блоке данных на уровне (j + 1). На каждом уровне индекса и
Рисунок 3.3 – Пример организации индексного файла в индексно-последовательном методе доступа к данным
данных, последовательный поиск выполняется до тех пор, пока не будет установлено местонахождение искомой записи или ее отсутствие. На рисунке 3.3 приведен пример организации индексно-последовательного метода доступа к данным.
При добавлении записи, например со значением ключа 103, в индексном файле одним из быстрых методов поиска ищется номер блока, в котором необходимо разместить запись с указанным ключом. В данном случае это четвёртый блок, где запись размещается между 100 и 105, так как в блоках основного файла эти записи упорядочены. При поиске нужной записи по заданному ключу сначала ищется быстрым методом поиска в индексном файле номер блока, содержащего искомую запись, а затем последовательным методом в найденном блоке основного файла осуществляется поиск требуемой записи. При удалении записи сначала она ищется описанным выше способом, а затем удаляется из блока способом, описанным в последовательном методе доступа.
|
|
|
При индексно-произвольном методе доступа записи в основном файле базы данных хранятся в произвольном порядке, и создается отдельный файл статей, включающих значения ключа и физические адреса хранимых записей. Статья, содержащая действительный ключ и адрес, называется статьей индекса, а весь файл – индексом. Каждой записи базы данных соответствует статья индекса. На рисунке 3.4 показан пример организации индексного файла в индексно-произвольном методе доступа к данным. Особенность этой разновидности индексного метода доступа состоит в том, что основной файл базы данных не упорядочен и адреса записей с соответствующим значением ключа индексного файла определяются одним из способов произвольных методов доступа, например с помощью функции хеширования. Организация индексного файла может быть с плотным, иногда говорят с полным, индексом (в данном случае в индексном файле хранятся ключи всех записей) и неплотным индексом, как показано на рисунке. При добавлении записи заносятся в конец основного файла и в индексном файле вставляются в соответствующее место, чтобы не нарушить упорядоченность записей. При изменении, удалении записей сначала осуществляется быстрый их поиск в индексном файле, после чего по найденному адресу записи в основном файле производятся изменения и удаления в основном файле и, если необходимо, то изменения и удаления в индексном файле.
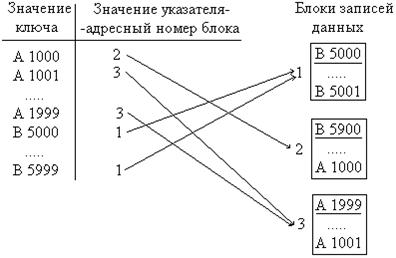 |
Рисунок 3.4 – Пример организации индексного файла в индексно-произвольном методе доступа к данным
К группе индексных методов доступа относится метод «Бинарное дерево». Запись бинарного дерева состоит из поля ключа записи и двух полей для указателей. Один из указателей хранит адрес на левое поддерево, второй указатель на правое поддерево. Листовые указатели записи бинарного дерева содержат указатели на блоки файла основных записей (файла данных). Записи бинарного дерева содержат только одно поле данных – информационное – значение ключа. На рисунке 3.5 показан пример организации индексного файла в виде бинарного дерева.
|
|
|
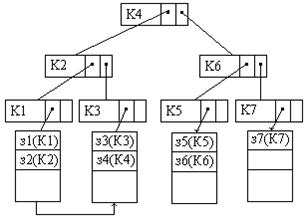 |
Рисунок 3.5 – Пример организации индексного файла в виде бинарного дерева
Существуют эффективные алгоритмы работы с древовидными структурами, включая добавление, удаление, изменение узлов дерева. К индексным методам доступа относится и метод доступа двусвязное дерево и мультисписковый метод доступа, название которых раскрывает способ организации индексных файлов. Особое место среди индексных методов доступа занимает инвертированный метод доступа, с помощью которого осуществляется реализация поиска по вторичному ключу и не реализуются алгоритмы ведения данных
В инвертированном методе доступа используется три файла – индекс вторичного ключа, инвертированный файл и основной файл базы данных. Индекс вторичного ключа содержит значения вторичных ключей, упорядоченных по возрастанию или убыванию и адрес блока в инвертированном файле. В инвертированном файле содержатся значения первичных ключей с данным значением вторичного ключа и адреса записей в основном файле, соответствующие значениям первичного ключа. На рисунке 3.6 показан пример организации инвертированного метода доступа.
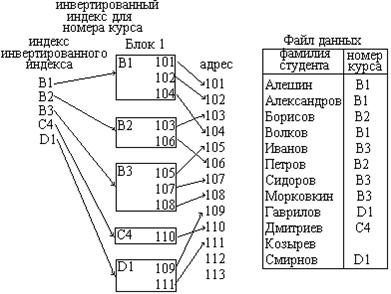 |
Рисунок 3.6 – Пример организации инвертированного метода доступа
С учетом особенностей организации индексно - последовательный метод поиска используют для организации первичных ключей, индексно-произвольный метод поиска реализует альтернативные или потенциальные ключи, инвертированный метод доступа реализует инверсионные входы.
В группе произвольных методов доступа используется основной файл базы данных и функция, преобразующая ключ в адрес, по которому хранится в основном файле запись с соответствующим значением ключа. К произвольным методам доступа относятся прямой метод доступа и метод хеширования идентификатора.
В прямом методе доступа каждой записи соответствует одно значение адреса. Если проектировщик базы данных может предусмотреть в памяти для каждой записи место, определяемое уникальным значением ее первичного ключа, тогда можно построить первичную функцию преобразования ключа в адрес, обеспечивающую запоминание и выборку каждой записи в точности за один произвольный доступ к блоку. С этой целью каждой совокупности ключевых значений записей, расположенных в одном и том же физическом блоке, можно присвоить относительный номер блока (относительный физический адрес). На самом деле данные хранятся в соответствии с порядком ключей, но при этом неявно им последовательно присвоены относительные номера блоков.
Например, компания имеет 30 отделений (с номерами от 1 до 30). В каждом блоке хранится 5 записей данных об отделениях, следовательно, нужно 6 блоков.
Функция преобразования ключа в адрес: 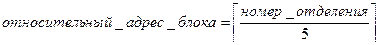 . Например, запись данных об 1 отделениях располагается с относительным номером 3. Такое абсолютное соответствие меду ключом и относительным адресом блока является основной отличительной чертой прямого метода доступа. В случае реальных данных не всегда возможно такое соответствие значения ключа ровно одному адресу, поэтому часто приходится строить более сложные функции.
. Например, запись данных об 1 отделениях располагается с относительным номером 3. Такое абсолютное соответствие меду ключом и относительным адресом блока является основной отличительной чертой прямого метода доступа. В случае реальных данных не всегда возможно такое соответствие значения ключа ровно одному адресу, поэтому часто приходится строить более сложные функции.
Метод хеширования идентификатора или метод рандомизации (random – произвольный доступ; hash – размешивание) – это метод быстрой выборки и обновления записей, относящийся к группе произвольных методов доступа. В этом методе используется следующая терминология. Идентификатор – атрибут, уникально определяющий каждый экземпляр некоторой сущности предметной области. В контексте файла и базы данных, идентификатор – это первичный ключ. Хеширование – метод доступа, обеспечивающий адресацию данных путем преобразования значения ключа в относительный или абсолютный физический адрес. Функция преобразования ключа – функция хеширования или функция рандомизации. В прямом методе доступа имеет место отображение 1:1, в методе хеширования - М: 1, то есть возможно преобразование двух или более значений ключа в один и тот же физический адрес, так называемый собственный адрес. Такие ключи называют синонимами, а случай преобразования ключа в уже занятый собственный адрес – коллизией.
Для прямого метода доступа характерна «неуправляемость ключа», то есть по значению ключа один раз вычисляются адреса и размещаются в памяти, это требует неоправданно больших служебных издержек памяти.
Хеширование обеспечивает эффективную выборку и обновление отдельных записей по заданному значению первичного ключа. Плата за эффективность – нарушение упорядоченности файла и потеря возможности выполнить пакетную обработку или генерацию отчетов, основанную на упорядоченности записей по первичному ключу. Один из способов организации хеширования – это когда все адресное пространство, непосредственно доступное функции хеширования, делится на несколько областей фиксированного размера, называемых бакетами. В качестве бакета можно использовать цилиндр, дорожку, блок и так далее, то есть любой участок памяти, адресуемый как единое целое. Бакет может состоять из более мелких физических единиц данных (дорожка, хранимая запись и другие). Наименьшая составная единица бакета, используемая при анализе метода хеширования, называется фрагментом (хранимой) записи данных или секцией. Пример организации метода хеширования идентификатора показан на рисунке 3.7
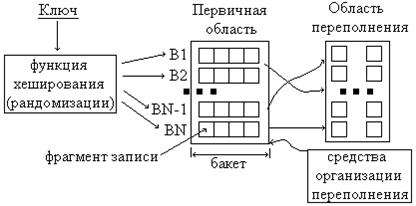 |
Рисунок 3.7 – Пример организации метода хеширования идентификатора
Процесс разрешения коллизий синонимов состоит из двух шагов: на первом шаге выполняется просмотр бакета с целью выявления в нем свободного пространства для новой записи. При наличии пространства просмотр прекращается. В противном случае, переходим на выполнение второго шага, который состоит в обработке переполнения.
В случае заполнения области переполнении и попытке размещения очередной записи в занятый бакет происходит либо реорганизация файла (освобождается область переполнения, выделяется большее число бакетов, либо размер бакетов увеличивается), либо выбирается другая функция хеширования.
Наилучшей функцией хеширования является функция, отображающая NR значений ключа в NR собственных адресов без синонимов. Теоретически будет NR! способов такого идеального отображения. Но если учесть, что существует NRNR способов присвоения NR ключами NR собственных адресов, то вероятность этого идеального отображения ничтожна. Рассмотрим пример. Пусть необходимо построить хеш-функции, ставящей в соответствие каждому значению ключа адрес для последовательности чисел 36, 16, 13, 5, 85 и для адресного пространства из 10 бакетов, причём построить функцию хеширования, не приводящую к коллизиям.
а) функция хеширования:= fхеш = значение ключа (mod 10) + 1. Значения 36 и 16 синонимы и они отображаются в бакет 7, а также 5 и 85, которые отображаются в бакете 6, то есть имеется четыре коллизии.
б) fхеш = сумма цифр значения ключа (mod 10) + 1. Тогда получим такое размещение значений ключа по адресам: 3 + 6 = 9; 9 mod 10 + 1 = 10
fхеш(16) = (1 + 6) mod 10 + 1 = 8
fхеш(13) = (1 + 3) mod 10 + 1 = 5
fхеш(5) = 5 mod 10 + 1 = 6
fхеш(85) = 13 mod 10 + 1 = 4
То есть, для данной комбинации цифр здесь нет коллизий. Метод деления является наиболее часто применяемым методом при построении функций хеширования.
Глава 4. Свойства баз данных
|
|
|
|
|
Дата добавления: 2014-10-15; Просмотров: 6952; Нарушение авторских прав?; Мы поможем в написании вашей работы!