КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Групповые операции с данными
|
|
|
|
Вопросы для защиты
1. Назначение скрипта.
2. Перечислите шаги создания скрипта.
3. Настройка скрипта.
Лабораторная работа №6
Цель работы: ознакомиться с приемами групповой обработки данных.
Узел Групповая обработка работает похожим на Скрипт образом. Основным отличием от него является то, что входной набор делится на части по указанным группам, и затем каждая группа отдельно «прогоняется» через копию цепочки узлов обработки.
Если аналогом скрипта является процедура в языке программирования, то аналогом групповой обработки – цикл. Групповая обработка позволяет создавать очень гибкие сценарии, особенно она незаменима в тех случаях, когда нужно обрабатывать отдельные «пачки» данных внутри одного набора в зависимости от статистических характеристик каждой такой «пачки» (сумма, среднее, количество записей и т.д.).
Рассмотрим групповую обработку на конкретном примере. Импортируйте в Deductor текстовый файл Trade.txt. Фрагмент набора данных приведен на рис. 1.
Рисунок 1 – Фрагмент набора данных
Отсортируйте его по возрастанию по полю Дата (Год + Месяц). Далее из этого поля узлом Калькулятор выделите год, создав новое поле с функцией
SUBSTR(COL1;1;4).
Необходимо выполнить следующую задачу: рассчитать для каждого месяца каждого года (т.е., по сути, строки набора данных) долю и долю с накоплением от годовой суммы в пределах одного года.
Ситуация характеризуется тем, что имеется не один год, а несколько: с 2000 по 2004.
Воспользуйтесь Групповой обработкой. Для наглядности сначала проделайте все необходимые действия над одной группой, например 2000 год, а затем «распространите» эти действия на весь исходный набор данных (рис. 2).

Рисунок 2 – Применение узла Групповая обработка
Сначала выделите эту группу фильтром и последовательно добавьте два поля двумя калькуляторами:
1. Доля (PART):
ROUND(COL2/Stat("COL2";"SUM")*100;2),
2. Накапливающаяся доля (CUM_PART):
CumulativeSum("PART").
Далее добавьте к исходному набору данных узел Групповая обработка. На первом шаге нужно указать поля для определения групп при обработке данных. В нашем случае это поле Год (рис.8.3).
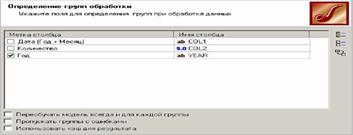
Рисунок 3 – Определение групп обработки
На следующей вкладке укажите начальный этап обработки – узел с меткой Калькулятор: Доля.
Конечным узлом будет Калькулятор: Накапливающаяся доля.
В результате групповой обработки получится набор данных фрагмент набора которых представлен на рис.4.
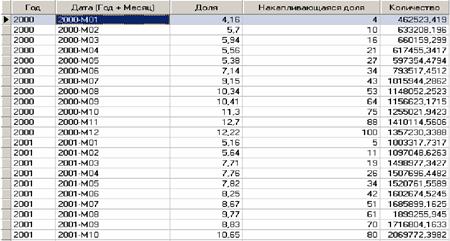
Рисунок 4 – Результат выполнения групповой обработки
Обратите внимание – накапливающаяся доля доходит до 100% в каждом году, и «сбрасывается» с началом нового года. Таким образом, мы получили желаемый результат. Без групповой обработки получить это было бы гораздо сложнее.
На первой вкладке мастера настройки узла были доступны три опции. Разберем их детальнее.
Флаг Переобучать модель всегда и для каждой группы актуален, когда в цепочке узлов, на которые ссылается групповая обработка, имеются какие-либо модели – линейная регрессия, нейронная сеть и так далее. Поэтому в случае простых действий – Калькулятор, Фильтр, Замена данных, Сортировка и другие – на данный флаг не нужно обращать внимания.
Флаг Пропускать группы с ошибками исключит из результирующего набора группы, при «прогоне» которых через цепочку узлов возникла ошибка. В подавляющем большинстве случаев это бывает также при наличии в цепочке узлов каких-либо моделей, поэтому при простых действиях флаг ставить не нужно.
Флаг Использовать кэш для результата определяет один из двух вариантов функционирования узла: «без использования кэширования» и «с использованием кэширования».
Кэш – это подборка данных, дублирующих оригинальные значения, сохранённые где-то или вычисленные ранее, когда оригинальные данные труднодоступны из-за большого времени доступа или для вычисления. Многие программы записывают куда-либо промежуточные или вспомогательные результаты работы, чтобы не вычислять их каждый раз, когда они понадобятся. Это ускоряет работу, но требует дополнительной памяти (оперативной или дисковой).
Кэш требуется для экономии памяти. Это необходимо, когда групп обработки много и каждая группа требует больших вычислительных затрат. Большие вычислительные затраты, как правило, возникают при переобучении моделей – пересчете коэффициентов регрессии, подборе весов нейронной сети и так далее. Поэтому здесь совет следующий. Когда групп немного и в цепочке узлов «прогона» групп нет моделей, то кэш не нужен. В иных случаях лучше поставить флаг с кэшем.
Задание для практической работы
Повторите в Deductor пример с групповой обработкой.
|
|
|
|
|
Дата добавления: 2014-10-31; Просмотров: 1019; Нарушение авторских прав?; Мы поможем в написании вашей работы!