КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Последовательность выполняемых действий. Теоретическая подготовка
|
|
|
|
Теоретическая подготовка.
Оптическое распознавание символов (англ. optical character recognition,
OCR) — механический или электронный перевод изображений рукописного,
машинописного
или
печатного
текста
в
текстовые
данные
—
последовательность кодов, использующихся для представления символов в
компьютере (например, в текстовом редакторе). Распознавание широко
используется для конвертации книг и документов в электронный вид, для
автоматизации систем учѐта в бизнесе или для публикации текста на веб-
странице. Оптическое распознавание текста позволяет редактировать текст,
осуществлять поиск слова или фразы, хранить его в более компактной форме,
демонстрировать
или
распечатывать
материал,
не
теряя
качества,
анализировать информацию, а также применять к тексту электронный
перевод,
форматирование
или
преобразование
в
речь.
Оптическое
распознавание
текста
является
исследуемой
проблемой
в
областях
распознавания образов, искусственного интеллекта и компьютерного зрения.
Системы оптического распознавания текста требуют калибровки для
работы с конкретным шрифтом; в ранних версиях для программирования
было необходимо изображение каждого символа, программа одновременно
могла работать только с одним шрифтом. В настоящее время больше всего
распространены так называемые «интеллектуальные» системы, с высокой
степенью точности распознающие большинство шрифтов. Некоторые
системы оптического распознавания текста способны восстанавливать
исходное форматирование текста, включая изображения, колонки и другие
нетекстовые компоненты.
1. Ознакомление с программой CuneiForm.
|
|
|
СuneiForm — это программа для оптического распознавания текста
документов в редактируемый вид. Результаты работы программы можно
редактировать в офисных программах и текстовых редакторах и сохранять в
популярных форматах, проводить по ним полнотекстовый поиск.
CuneiForm
является
предшественницей
систем
промышленного
распознавания и понимания документов.
Возможности
· При распознавании с помощью CuneiForm сохраняется структура
документа и его форматирование.
· Программа распознает таблицы любой структуры и сложности, в том
числе и без отображения линий табличной сетки.
· Распознаются любые печатные шрифты: книги, газеты, журналы,
распечатки с лазерных и матричных принтеров, тексты с пишущих
машинок и т.п.
· Алгоритмы оптического распознавания (OCR, Optical Character
Recognition), встроенные в программу позволяют распознавать текст с
матричного принтера, плохих ксерокопий и факсов.
· Распознавание документов более чем на 20 языках: на русском,
английском,
немецком,
французском,
испанском,
итальянском,
шведском, украинском и других.
· Для повышения качества распознавания в программе используется
словарная проверка. При этом стандартный словарь можно расширить
за счет импорта новых слов из текстовых файлов.
2. Особенности программы
· CuneiForm не умеет работать с некоторыми сканерами (в особенности
сканерами МФУ). В таких случаях необходимо сканировать документ
при помощи стандартных функций Windows.
· Необходимо следить за разрешением сканирования. Это связано с тем,
что CuneiForm не может обрабатывать большие файлы (свыше 100
Кбайт), а чем выше разрешение, тем больший размер файла-скана. Зато
качество
распознавания
текста
в
программе
очень
высокое,
оптимальным вариантом разрешающей способности будет 200 dpi
(можно и больше, но тогда есть вероятность, что программа зависнет).
|
|
|
· Малое количество языков, в CuneiForm есть смешанный англо-русский
режим распознавания.
3. Запускаем и работаем с CuneiForm.
Интерфейс CuneiForm намного
проще, чем у его коммерческого
аналога – Fine Reader, и почти не
требует
можно
настройки.
полностью
Программой
управлять
благодаря
кнопкам
на
панели
инструментов. Рассмотрим их более детально:
Программа может
работать
в
режиме
мастера,
активируется
который
первой
кнопкой.
CuneiForm
Но
если
не
поддерживает текущий
сканер,
режима
то
от
этого
стоит
|

|
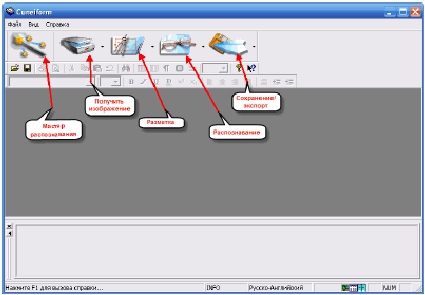
отказаться. Следующая кнопка запускает процесс сканирования (опять же,
если есть поддержка сканера). На этой и следующих кнопках Вы можете
заметить небольшие стрелочки. Нажав на них, мы получим доступ к
некоторым дополнительным функциям.
Теперь опробуем CuneiForm на практике. Первой кнопкой, которую
следует
нажать,
будет
«Получить
изображение».
Если
же
такой
возможности
нет,
то
откроем уже готовый скан
(поддерживаются форматы
JPG, GIF, BMP, PNG (не
всегда корректно), а также
TIF (в полной мере)).
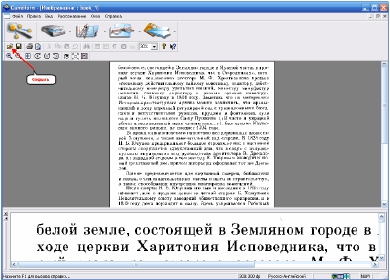
Теперь
следует
произвести разметку. Она
помогает
определить
блоки, из которых состоит
страница. Поддерживается
распознавание блоков в
виде текста (синяя рамка),
рисунков (зеленая рамка)
или
таблиц
(оранжевая
рамка) (автоматическую разметку можно доработать вручную, используя
контекстное меню блока).
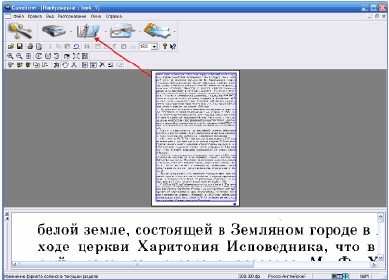
Когда текст обозначен, самое время провести его распознавание. Для
этого нажимаем следующую кнопку. По окончании процесса распознавания
в рабочем окне отобразится текст, который можно редактировать в
небольшом встроенном текстовом редакторе похожем на Microsoft Word.
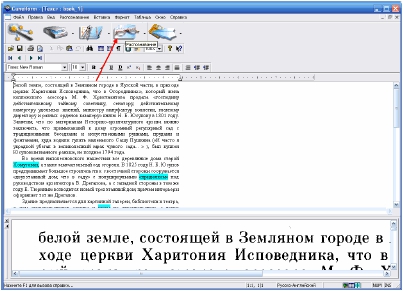
При этом Вы сразу сможете увидеть те слова, в которых программа «не
|
|
уверена»
(голубая
подсветка) и в которых
есть
ошибка
(сомнительная буква —
розовая).
И,
наконец,
после
успешного редактирования
можно сохранить результат
нашей
работы.
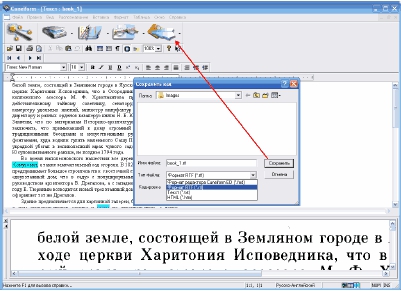
Кликаем
последнюю
кнопку
на
панели
инструментов
и
сохраняем текст как RTF,
HTML или TXT-файл.
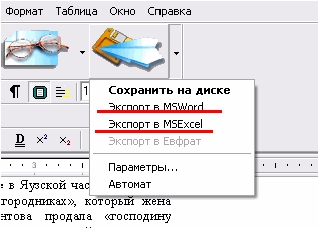
Нажав на стрелочку сбоку, возможно выбрать опции экспорта в одну из
|
|
|
предложенных программ (Microsoft Word, Excel или Евфрат).
Посмотрите на предыдущий
скриншот. Обратите внимание, что
в дополнительных меню кнопок,
начиная с «Разметки» и заканчивая
«Сохранением», есть в конце пункт
«Автомат».
Активирование
этой
опции освобождает вас от нажатия
выбранной кнопки. То есть можно
|
|
|
автоматизировать процесс обработки скана до того, что вы будете лишь
открывать новый документ. Все остальное CuneiForm сделает сама.
Программа изначально настроена самым оптимальным образом, но
если захотеть что-нибудь изменить, просто зайдите в меню «Файл» и
выберите опцию «Общие параметры». Это может пригодиться для смены
языка и некоторых других параметров распознавания, форматирования и
сканирования текстов.
Сканируем несколько страниц.
В пакет CuneiForm входит ещѐ одна утилита. Откройте «Пуск» снова и
в папке с программой обнаружите ещѐ одно приложение — «Пакетное
распознавание». Представьте, что Вы отсканировали несколько страниц и
теперь надо еѐ распознать.
Если открывать каждый
файл-скан по отдельности
на
это
уйдет
масса
времени,
пакетный
же
режим
возможность
представляет
указать
нужные
файлы,
а
об
остальном
программа
позаботится сама.
|

|
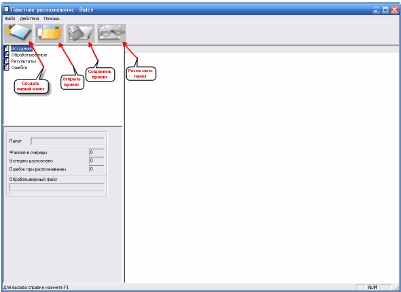
Для начала нужно
создать
новый
пакет
файлов.
Нажимаем
соответствующую кнопку
и
следуем
подсказкам
запустившегося мастера:
На последнем этапе
возможно
сохранить
либо
наш
просто
пакет,
либо начать немедленное
распознавание. В последнем случае запустится режим распознавания,
который может затянуться на несколько минут (в зависимости от количества
файлов-сканов).
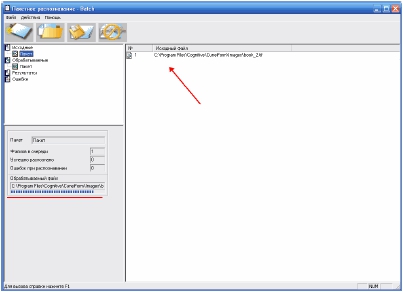
По
окончании
распознавания
Вы
увидите в основном окне
все
распознанные
документы.
распознавание
Если
прошло
успешно, то в левой
боковой
панели
Вы
обнаружите активными
только
два
списка:
«Исходные» и «Обработанные». Если же будут файлы, которые не удалось
|
|
|
распознать, их найдете в разделе «Ошибки».
Теперь необходимо сохранить полученные файлы.
Результаты работ показать преподавателю.
|
|
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 476; Нарушение авторских прав?; Мы поможем в написании вашей работы!