КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Шифрование с помощью компьютерной клавиатуры
 |
Частотный криптоанализ
Помимо этого иногда может помочь частотный анализ. Он основывается на предположении о том, что частота появления заданной буквы алфавита в достаточно длинных текстах одна и та же для разных текстов одного языка.
В нашем случае вполне возможно, что если частота встречаемости какого-либо знака в зашифрованном тексте совпадает со средней частотой встречаемости какой-то буквы алфавита для других текстов, то этот знак и обозначает эту самую букву.
Вот пример таблицы с относительными частотами букв русского языка.
(пример взят отсюда http://denisavr.livejournal.com/445453.html).
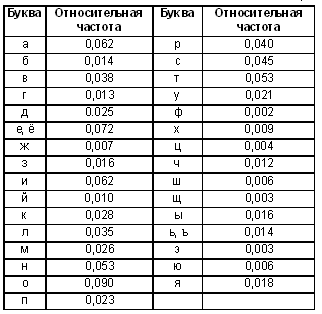
“Как следует из таблицы, наиболее частая буква русского языка — о. Ее относительная частота, равная 0,090, означает, что на 1000 букв русского текста приходится в среднем 90 букв о. В таком же смысле понимаются относительные частоты и остальных букв. В таблице не указан еще один “символ” — промежуток между словами (пробел). Его относительная частота наибольшая и равна 0,175.”
Частотный анализ может довольно удачно применяться и для других моноалфавитных шифров, которые рассматривались ранее.
Думаю понятно, что этот вид шифра более новый, чем те, о которых я говорил ранее. Тем не менее в интернете довольно часто можно встретить различные задачки с его использованием.
Здесь может быть несколько способов шифрования.
1 способ.
Вместо каждой буквы исходного текста записывается ее порядковый номер на клавиатуре. Например, Ц => 2, В => 15.
Также бывают случаи, когда отсчет ведется с конца. То есть первой буквой будет Ю.
2 способ.
Текст записывается с помощью английской раскладки клавиатуры. То есть вместо буквы А будет буква F, вместо Е будет T и так далее.
|
|
|
3 способ.
Первой цифрой пишется порядковый номер ряда на клавиатуре (отсчет чаще сверху вниз, но бывает и наоборот), а второй цифрой – номер буквы в ряду (чаще слева направо, но бывают и исключения). Шифр может записываться в виде дроби, где в числителе стоит номер ряда, а в знаменателе – номер буквы. Либо в виде последовательности цифр, сначала номер ряда, потом номер буквы в ряду.
Пример:

4 способ.
Всего один раз встречал подобный способ шифрования, но стоит упомянуть и о нем.
Буквы исходного текста «обводятся» окружающими их буквами.
Например, буква Р будет выглядеть так ИПЕНГОТ; У => ЫЦ34КАВ.
Также можно шифровать и знаки препинания, и английские буквы.
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 2353; Нарушение авторских прав?; Мы поможем в написании вашей работы!