КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Построение двоичного группового кода 1 страница
|
|
|
|
Построение конкретного корректирующего кода производят, исходя из требуемого объема кода Q, т. е. необходимого числа передаваемых команд или дискретных значений измеряемой величины и статистических данных о наиболее вероятных векторах ошибок в используемом канале связи.
Вектором ошибки называют n-разрядную двоичную последовательность, имеющую единицы в разрядах, подвергшихся искажению, и нули во всех остальных разрядах. Любую искаженную кодовую комбинацию можно рассматривать теперь как сумму (или разность) но модулю 2 исходной разрешенной кодовой комбинации и вектора ошибки.
Исходя из неравенства 2k – l 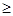 Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом.
Q (нулевая комбинация часто не используется, так как не меняет состояния канала связи), определяем число информационных разрядов k, необходимое для передачи заданного числа команд обычным двоичным кодом.
Каждой из 2k - 1 ненулевых комбинаций k -разрядного безызбыточного кода нам необходимо поставить в соответствие комбинацию из п символов. Значения символов в п – k проверочных разрядах такой комбинации устанавливаются в результате суммирования по модулю 2 значений символов в определенных информационных разрядах.
Поскольку множество 2k комбинаций информационных символов (включая нулевую) образует подгруппу группы всех n-разрядных комбинаций, то и множество 2k n-разрядных комбинаций, полученных по указанному правилу, тоже является подгруппой группы n-разрядных кодовых комбинаций. Это множество разрешенных кодовых комбинаций и будет групповым кодом.
Нам надлежит определить число проверочных разрядов и номера информационных разрядов, входящих в каждое из равенств для определения символов в проверочных разрядах.
|
|
|
Разложим группу 2n всех n-разрядных комбинаций на смежные классы по подгруппе 2k разрешенных n-разрядных кодовых комбинаций, проверочные разряды в которых еще не заполнены. Помимо самой подгруппы кода в разложении насчитывается 2n-k – 1 смежных классов. Элементы каждого класса представляют собой суммы по модулю 2 комбинаций кода и образующих элементов данного класса. Если за образующие элементы каждого класса принять те наиболее вероятные для заданного канала связи вектора ошибок, которые должны быть исправлены, то в каждом смежном классе сгруппируются кодовые комбинации, получающиеся в результате воздействия на все разрешенные комбинации определенного вектора ошибки. Для исправления любой полученной на выходе канала связи кодовой комбинации теперь достаточно определить, к какому классу смежности она относится. Складывая ее затем (по модулю 2) с образующим элементом этого смежного класса, получаем истинную комбинацию кода.
Ясно, что из общего числа 2n – 1 возможных ошибок групповой код может исправить всего 2n-k – 1разновидностей ошибок по числу смежных классов.
Чтобы иметь возможность получить информацию о том, к какому смежному классу относится полученная комбинация, каждому смежному классу должна быть поставлена в соответствие некоторая контрольная последовательность символов, называемая опознавателем (синдромом).
Каждый символ опознавателя определяют в результате проверки на приемной стороне справедливости одного из равенств, которые мы составим для определения значений проверочных символов при кодировании.
Ранее указывалось, что в двоичном линейном коде значения проверочных символов подбирают так, чтобы сумма по модулю 2 всех символов (включая проверочный), входящих в каждое из равенств, равнялась нулю. В таком случае число единиц среди этих символов четное. Поэтому операции определения символов опознавателя называют проверками на четность. При отсутствии ошибок в результате всех проверок на четность образуется опознаватель, состоящий из одних нулей. Если проверочное равенство не удовлетворяется, то в соответствующем разряде опознавателя появляется единица. Исправление ошибок возможно лишь при наличии взаимно однозначного соответствия между множеством опознавателей и множеством смежных классов, а следовательно, и множеством подлежащих исправлению векторов ошибок.
|
|
|
Таким образом, количество подлежащих исправлению ошибок является определяющим для выбора числа избыточных символов п – k. Их должно быть достаточно для того, чтобы обеспечить необходимое число опознавателей. Если, например, необходимо исправить все одиночные независимые ошибки, то исправлению подлежат п ошибок:
000…01
000…10
……….
010…00
100…00
Различных ненулевых опознавателей должно быть не менее п. Необходимое число проверочных разрядов, следовательно, должно определяться из соотношения
2n-k -1 n или 2n-k -1 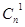
Если необходимо исправить не только все единичные, но и все двойные независимые ошибки, соответствующее неравенство принимает вид
2n-k-l + 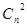
В общем случае для исправления всех независимых ошибок кратности до s включительно получаем
2n-k-l + +…+ 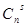
Стоит подчеркнуть, что в приведенных соотношениях указывается теоретический предел минимально возможного числа проверочных символов, который далеко не во всех случаях можно реализовать практически. Часто проверочных символов требуется больше, чем следует из соответствующего равенства.
Одна из причин этого выяснится при рассмотрении процесса сопоставления каждой подлежащей исправлению ошибки с ее опознавателем.
4.8.1 Составление таблицы опознавателей
Начнем для простоты с установления опознавателей для случая исправления одиночных ошибок. Допустим, что необходимо закодировать 15 команд. Тогда требуемое число информационных разрядов равно четырем. Пользуясь соотношением 2n-k - 1= п, определяем общее число разрядов кода, а следовательно, и число ошибок, подлежащих исправлению (n = 7). Три избыточных разряда позволяют использовать в качестве опознавателей трехразрядные двоичные последовательности.
|
|
|
В данном случае ненулевые последовательности в принципе могут быть сопоставлены с подлежащими исправлению ошибками в любом порядке. Однако более целесообразно сопоставлять их с ошибками в разрядах, начиная с младшего, в порядке возрастания двоичных чисел (табл. 4.6).
Таблица 4.6.
| Векторы ошибок | Опознаватели | Векторы ошибок | Опознаватели |
При таком сопоставлении каждый опознаватель представляет собой двоичное число, указывающее номер разряда, в котором произошла ошибка.
Коды, в которых опознаватели устанавливаются по указанному принципу, известны как коды Хэмминга.
Возьмем теперь более сложный случай исправления одиночных и двойных независимых ошибок. В качестве опознавателей одиночных ошибок в первом и втором разрядах можно принять, как и ранее, комбинации 0...001 и 0...010.
Однако в качестве опознавателя одиночной ошибки в третьем разряде комбинацию 0...011 взять нельзя. Такая комбинация соответствует ошибке одновременно в первом и во втором разрядах, а она также подлежит исправлению и, следовательно, ей должен соответствовать свой опознаватель 0...011.
В качестве опознавателя одиночной ошибки в третьем разряде можно взять только трехразрядную комбинацию 0...0100, так как множество двухразрядных комбинаций уже исчерпано. Подлежащий исправлению вектор ошибки 0...0101 также можно рассматривать как результат суммарного воздействия двух векторов ошибок 0...0100 и 0...001 и, следовательно, ему должен быть поставлен в соответствие опознаватель, представляющий собой сумму по модулю 2 опознавателей этих ошибок, т.е. 0...0101.
Аналогично находим, что опознавателем вектора ошибки 0...0110 является комбинация 0...0110.
Определяя опознаватель для одиночной ошибки в четвертом разряде, замечаем, что еще не использована одна из трехразрядных комбинаций, а именно 0...0111. Однако, выбирая в качестве опознавателя единичной ошибки в i-м разряде комбинацию с числом разрядов, меньшим i, необходимо убедиться в том, что для всех остальных подлежащих исправлению векторов ошибок, имеющих единицы в i-м и более младших разрядах, получатся опознаватели, отличные от уже использованных. В нашем случае подлежащими исправлению векторами ошибок с единицами в четвертом и более младших разрядах являются: 0...01001, 0...01010, 0...01100.
|
|
|
Если одиночной ошибке в четвертом разряде поставить в соответствие опознаватель 0...0111, то для указанных векторов опознавателями должны были бы быть соответственно
 0…0111 0…0111 0…0111
0…0111 0…0111 0…0111
0…0001 0…0010 0…0100
_______ ________ _______
0…0110 0…0101 0…0011
Однако эти комбинации уже использованы в качестве опознавателей других векторов ошибок, а именно: 0...0110, 0...0101, 0...0011.
Следовательно, во избежание неоднозначности при декодировании в качестве опознавателя одиночной ошибки в четвертом разряде следует взять четырехразрядную комбинацию 1000. Тогда для векторов ошибок
0...01001, 0...01010, 0...01100
опознавателями соответственно будут:
0...01001, 0...01010, 0...01100.
Аналогично можно установить, что в качестве опознавателя одиночной ошибки в пятом разряде может быть выбрана не использованная ранее четырехразрядная комбинация 01111.
Действительно, для всех остальных подлежащих исправлению векторов ошибок с единицей в пятом и более младших разрядах получаем опознаватели, отличающиеся от ранее установленных:
Векторы ошибок Опознаватели
0...010001 0…01110
0...010010 0…01101
0...010100 0…01011
0...011000 0…00111
Продолжая сопоставление, можно получить таблицу опознавателей для векторов ошибок данного типа с любым числом разрядов. Так как опознаватели векторов ошибок с единицами в нескольких разрядах устанавливаются как суммы по модулю 2 опознавателей одиночных ошибок в этих разрядах, то для определения правил построения кода и составления проверочных равенств достаточно знать только опознаватели одиночных ошибок в каждом из разрядов. Для построения кодов, исправляющих двойные независимые ошибки, таблица таких опознавателей определена с помощью вычислительной машины вплоть до 29-го разряда [Теория кодирования. Сборник. – М.:Мир, 1964]. Опознаватели одиночных ошибок в первых пятнадцати разрядах приведены в табл. 4.7.
По тому же принципу аналогичные таблицы определены и для ошибок других типов, например для тройных независимых ошибок, пачек ошибок в два и три символа.
4.8.2 Определение проверочных равенств
Итак, для любого кода, имеющего целью исправлять наиболее вероятные векторы ошибок заданного канала связи (взаимно независимые ошибки или пачки ошибок), можно составить таблицу опознавателей одиночных ошибок в каждом из разрядов. Пользуясь этой таблицей, нетрудно определить, символы каких разрядов должны входить в каждую из проверок на четность.
Таблица 4.7.
| Номер разряда | Опознаватель | Номер разряда | Опознаватель | Номер разряда | Опознаватель |
Рассмотрим в качестве примера опознаватели для кодов, предназначенных исправлять единичные ошибки (табл. 4.8).
Таблица 4.8.
| Номер разрядов | Опознаватель | Номер разрядов | Опознаватель | Номер разрядов | Опознаватель |
В принципе можно построить код, усекая эту таблицу на любом уровне. Однако из таблицы видно, что оптимальными будут коды (7, 4), (15, 11), где первое число равно n, а второе k, и другие, которые среди кодов, имеющих одно и то же число проверочных символов, допускают наибольшее число информационных символов.
Усечем эту таблицу на седьмом разряде и найдем номера разрядов, символы которых должны войти в каждое из проверочных равенств.
Предположим, что в результате первой проверки на четность для младшего разряда опознавателя будет получена единица. Очевидно, это может быть следствием ошибки в одном из разрядов, опознаватели которых в младшем разряде имеют единицу. Следовательно, первое проверочное равенство должно включать символы 1, 3, 5 и 7-го разрядов: a1 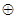 a3 a5 a7=0.
a3 a5 a7=0.
Единица во втором разряде опознавателя может быть следствием ошибки в разрядах, опознаватели которых имеют единицу во втором разряде. Отсюда второе проверочное равенство должно иметь вид a2 a3 a6 a7= 0.
Аналогично находим и третье равенство: a4 a5 a6 a7= 0.
Чтобы эти равенства при отсутствии ошибок удовлетворялись для любых значений информационных символов в кодовой комбинации, в нашем распоряжении имеется три проверочных разряда. Мы должны так выбрать номера этих разрядов, чтобы каждый из них входил только в одно из равенств. Это обеспечит однозначное определение значений символов в проверочных разрядах при кодировании. Указанному условию удовлетворяют разряды, опознаватели которых имеют по одной единице. В нашем случае это будут первый, второй и четвертый разряды.
Таким образом, для кода (7, 4), исправляющего одиночные ошибки, искомые правила построения кода, т. е. соотношения, реализуемые в процессе кодирования, принимают вид:
a1=a3 a5 a7,
a2=a3 a6 a7, (4.1)
a4=a5 a6 a7.
Поскольку построенный код имеет минимальное хэммингово расстояние dmin = 3, он может использоваться с целью обнаружения единичных и двойных ошибок. Обращаясь к табл. 4.8, легко убедиться, что сумма любых двух опознавателей единичных ошибок дает ненулевой опознаватель, что и является признаком наличия ошибки.
Пример 27. Построим групповой код объемом 15 слов, способный исправлять единичные и обнаруживать двойные ошибки.
В соответствии с dи 0 min r+s+1код должен обладать минимальным хэмминговым расстоянием, равным 4. Такой код можно построить в два этапа. Сначала строим код заданного объема, способный исправлять единичные ошибки. Это код Хэмминга (7, 4). Затем добавляем еще один проверочный разряд, который обеспечивает четность числа единиц в разрешенных комбинациях.
Таким образом, получаем код (8, 4). В процессе кодирования реализуются соотношения:
a1=a3 a5 a7,
a2=a3 a6 a7,
a4=a5 a6 a7.
a8=a1 a2 a3 a4 a5 a6 a7,
Обозначив синдром кода (7, 4) через S1, результат общей проверки на четность — через S2(S2 = 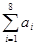 ) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
) и пренебрегая возможностью возникновения ошибок кратности 3 и выше, запишем алгоритм декодирования:
при S1= 0 и S2= 0 ошибок нет;
при S1= 0 и S2= 1 ошибка в восьмом разряде;
при S1 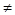 0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
0 и S2= 0 двойная ошибка (коррекция блокируется, посылается запрос повторной передачи);
при S1 0 и S2= 1 одиночная ошибка (осуществляется ее исправление).
Пример 28. Используя табл. 4.8, составим правила построения кода (8,2), исправляющего все одиночные и двойные ошибки.
Усекая табл. 4.7 на восьмом разряде, найдем следующие проверочные равенства:
a1 a5 a8=0,
a2 a5 a8=0,
a3 a5=0,
a4 a5=0,
a6 a8=0,
a7 a8=0.
Соответственно правила построения кода выразим соотношениями
a1=a5 a8 (4.2 а)
a2=a5 a8 (4.2 б)
a3=a5 (4.2 в)
a4=a5 (4.2 г)
a6=a8 (4.2 д)
a7=a8 (4.2 е)
Отметим, что для построенного кода dmin = 5, и, следовательно, он может использоваться для обнаружения ошибок кратности от 1 до 4.
Соотношения, отражающие процессы кодирования и декодирования двоичных линейных кодов, могут быть реализованы непосредственно с использованием сумматоров по модулю два. Однако декодирующие устройства, построенные таким путем для кодов, предназначенных исправлять многократные ошибки, чрезвычайно громоздки. В этом случае более эффективны другие принципы декодирования.
4.8.3 Мажоритарное декодирование групповых кодов
Для линейных кодов, рассчитанных на исправление многократных ошибок, часто более простыми оказываются декодирующие устройства, построенные по мажоритарному принципу. Это метод декодирования называют также принципом голосования или способом декодирования по большинству проверок. В настоящее время известно значительное число кодов, допускающих мажоритарную схему декодирования, а также сформулированы некоторые подходы при конструировании таких кодов.
Мажоритарное декодирование тоже базируется на системе проверочных равенств. Система последовательно может быть разрешена относительно каждой из независимых переменных, причем в силу избыточности это можно сделать не единственным способом.
Любой символ аi выражается d (минимальное кодовое расстояние) различными независимыми способами в виде линейных комбинаций других символов. При этом может использоваться тривиальная проверка аi = аi. Результаты вычислений подаются на соответствующий этому символу мажоритарный элемент. Последний представляет собой схему, имеющую d входов и один выход, на котором появляется единица, когда возбуждается больше половины его входов, и нуль, когда возбуждается число таких входов меньше половины. Если ошибки отсутствуют, то проверочные равенства не нарушаются и на выходе мажоритарного элемента получаем истинное значение символа. Если число проверок d 2s+ 1 и появление ошибки кратности s и менее не приводит к нарушению более s проверок, то правильное решение может быть принято по большинству неискаженных проверок. Чтобы указанное условие выполнялось, любой другой символ aj(j i) не должен входить более чем в одно проверочное равенство. В этом случае мы имеем дело с системой разделенных проверок.
Пример 29. Построим систему разделенных проверок для декодирования информационных символов рассмотренного ранее группового кода (8,2).
Поскольку код рассчитан на исправление любых единичных и двойных ошибок, число проверочных равенств для определения каждого символа должно быть не менее 5. Подставив в равенства (4.2 а) и (4.2 б) значения а8, полученные из равенств (4.2 д) и (4.2 е) и записав их относительно a5 совместно с равенствами (4.2 в) и (4.2 г) и тривиальным равенством a5 = a5, получим следующую систему разделенных проверок для символа a5:
a5 = a6 a1,
a5 = a7 a2,
а5 = а3,
а5 = a4,
а5 = а5.
Для символа a8 систему разделенных проверок строим аналогично:
a8 = a3 a1,
a8 = a4 a2,
a8 = а6,
a8 = a7,
a8 = а8.
4.8.4 Матричное представление линейных кодов
Матрицей размерности l 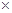 n называют упорядоченное множество l n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
n называют упорядоченное множество l n элементов, расположенных в виде прямоугольной таблицы с l строками и n столбцами:
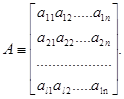
Транспонированной матрицей к матрице А называют матрицу, строками которой являются столбцы, а столбцами строки матрицы А:
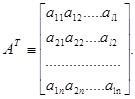
Матрицу размерности n n называют квадратной матрицей порядка n. Квадратную матрицу, у которой по одной из диагоналей расположены только единицы, а все остальные элементы равны нулю, называют единичной матрицей I. Суммой двух матриц А 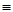 |аij| и В |bij| размерности l n называют матрицу размерности l n:
|аij| и В |bij| размерности l n называют матрицу размерности l n:
А + В |аij| + |bij| |аij + bij|.
Умножение матрицы А |аij| размерности l n на скаляр с дает матрицу размерности l n: с А c |аij| | c аij|.
Матрицы А |аij| размерности l n и В |bjk| размерности n m могут быть перемножены, причем элементами cik матрицы — произведения размерности l m являются суммы произведений элементов l-й строки матрицы А на соответствующие элементы k-го столбца матрицы В:
cik = 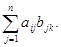
|
|
|
|
|
Дата добавления: 2014-11-25; Просмотров: 1072; Нарушение авторских прав?; Мы поможем в написании вашей работы!