КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Сжатие на основе статистических свойств данных и неравномерные коды
|
|
|
|
Методы такого сжатия изучаются в специальном разделе теории информации (подразделе теоретической информатики), который называется теорией экономного или эффективного кодирования. Экономное кодирование основано на использовании систем кодирования с переменной длиной кодового слова.
В системах равномерного кодирования, как нам уже известно, каждому символу алфавита A={ai}, i=1,…,n, ставится в соответствие кодовое слово с фиксированным числом разрядов. Например, в случае рассмотренного нами посимвольного двоичного кодирования каждому знаку алфавита A соответствует 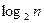 или
или 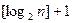 бит (двоичных разрядов). Однако давно известны и системы кодирования, в которых длина кодового слова непостоянна, например, код Морзе.
бит (двоичных разрядов). Однако давно известны и системы кодирования, в которых длина кодового слова непостоянна, например, код Морзе.
При использовании таких неравномерных кодов сразу же возникает проблема выделения кодовых слов из закодированной последовательности символов для однозначного декодирования сообщений. Например, в коде Морзе для этого предусмотрена специальная кодовая комбинация-разделитель (тройная пауза). Однако более экономным является использование при кодировании так называемого условия префиксности кода (условия Фано): никакое кодовое слово не должно являться началом другого кодового слова. Выполнение этого условия гарантирует однозначное разбиение последовательности символов на кодовые слова без применения разделителей: очередное кодовое слово получается последовательным считыванием символов до тех пор, пока получающаяся комбинация не совпадет с одним из кодовых слов.
Пусть, например, A={0,1, …,9}. Закодируем символы данного алфавита наборами двоичных знаков следующим образом:
0 – 00 5 – 110
1 – 01 6 – 1110
2 – 1000 7 – 11110
3 – 1001 8 – 111110
4 – 101 9 – 111111
Нетрудно видеть, что перед нами – префиксный код. Теперь появляется возможность однозначного декодирования любого сообщения. Например, последовательность 1110110111110100000000110011111110101 допускает лишь одно разбиение на кодовые слова 1110 110 111110 1000 00 00 01 1001 111111 01 01 и соответствует сообщению 65820013911.
Префиксный код называется примитивным, если его нельзя сократить, т.е. при вычеркивании любого знака хотя бы в одном кодовом слове код перестает быть префиксным. Префиксный код, приведенный выше в качестве примера, является примитивным.
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 553; Нарушение авторских прав?; Мы поможем в написании вашей работы!