КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Процедура Хафмана
Процедура Шеннона-Фано
В этом алгоритме предварительно производится упорядочивание сообщений по возрастанию или убыванию вероятностей pj. Разбиение на подмножества производится путем выбора разделяющей границы в упорядоченной последовательности так, чтобы суммарные вероятности подмножеств были по возможности одинаковыми. Кодовое дерево, построенное этим методом для примера в таблице 1.1, приведено на рис.1.5. Возле каждой вершины дерева указывается суммарная вероятность соответствующего подмножества.
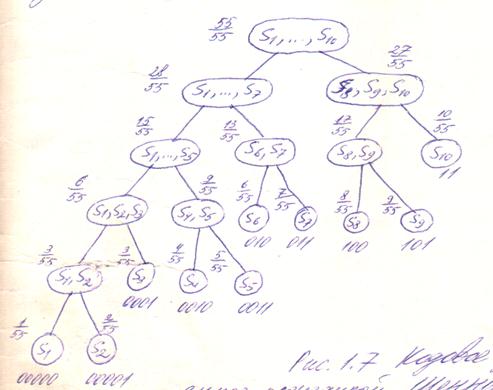
Рис.1.5
Кодовое дерево в процедуре Шеннона-Фано
Выполнив расчеты по формуле 1.3, получим: λkS= 3,145(бит/сообщение).Таким образом, код, полученный при помощи процедуры Шеннона-Фано, оказывается более экономным, чем код из таблицы 1.1.
Рассмотренная в §13процедура Шеннона-Фано является простым, но не всегда оптимальным алгоритмом построения экономного кода. Причина состоит в том, что способ разбиения на подмножества ограничен: вероятности сообщений, отнесенных к первому подмножеству, всегда больше или всегда меньше вероятностей сообщений, отнесенных ко второму подмножеству. Оптимальный алгоритм, очевидно, должен учитывать все возможные комбинации при разбиении на равновероятные подмножества. Это обеспечивается в процедуре Хафмана.
Процедура Хафмана представляет собой рекурсивный алгоритм, который строит бинарное дерево «в обратную сторону», т.е. от конечных вершин к корню. Основная идея алгоритма состоит в том, чтобы объединить два сообщения с наименьшими вероятностями – например, p1 и p2 – в одно множество и далее решать задачу с m-1 сообщениями и вероятностями p1’ = p1 + p2; p2’ = p3; …; pm-1’ = pm. Кодовое дерево, построенное процедурой Хафмана для рассматриваемого примера, приведено на рис.1.6.
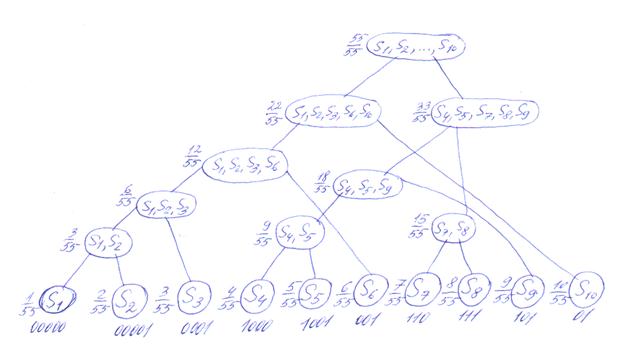
Рис.1.6
Кодовое дерево в процедуре Хафмана
Расчеты по формуле 1.3 дают среднее значение длины кодового слова λkS= 3,145(бит/сообщение), что совпадает с результатом применения процедуры Шеннона-Фано. Это означает, что для данного примера процедура Шеннона-Фано также оказалась оптимальной.
|
|
Дата добавления: 2014-11-20; Просмотров: 569; Нарушение авторских прав?; Мы поможем в написании вашей работы!