КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Двоичный поиск
|
|
|
|
Блочный поиск
Пусть файл или таблица упорядочены по возрастанию ключей и пусть на каждом шаге поиска имеется возможность выбирать любую по счету запись для сравнения ее ключа с аргументом поиска. Как организовать последовательность сравнений в этом случае, чтобы уменьшить сложность поиска?
Можно просматривать не каждую, а, например, сотые записи таблицы. Как только будет обнаружена запись с ключом, превышающим аргумент поиска, просматриваются (методом последовательного поиска) последние пропущенные 99 записей. Этот алгоритм называется поиском с пропусками или блочным поиском: записи группируются в блоки и сначала ищется нужный блок, а затем в нем ищется нужная запись.
Оптимальное число записей в блоке при равновероятных запросах равно квадратному корню из числа записей в файле. Среднее число записей, которые должны быть просмотрены при удачном поиске, в этом случае также равно 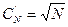 . Примем это без доказательства.
. Примем это без доказательства.
Пусть, как и в предыдущем случае, таблица поиска упорядочена по возрастанию ключей. Если теперь выбрать для проверки запись из середины таблицы, то, если эта запись не окажется искомой, множество возможных претендентов сократится приблизительно в два раза: искомая запись находится в одной из половин таблицы. На этой идее последовательного деления множества записей пополам основан двоичный или дихотомический поиск.
На каждом i-м шаге двоичного поиска считывается и сравнивается с аргументом запись 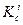 , находящаяся примерно в середине некоторого множества
, находящаяся примерно в середине некоторого множества 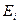 последовательно расположенных записей таблицы
последовательно расположенных записей таблицы
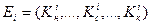 ,
,
где  , и
, и 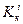 соответствуют начальной, серединной и конечной записям множества на i-м шаге поиска. Взяв в качестве исходного множества
соответствуют начальной, серединной и конечной записям множества на i-м шаге поиска. Взяв в качестве исходного множества 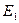 всю таблицу
всю таблицу 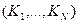 , шаги повторяются до тех пор, пока либо аргумент поиска не совпадет с ключом сравниваемой записи
, шаги повторяются до тех пор, пока либо аргумент поиска не совпадет с ключом сравниваемой записи 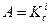 , либо множество не станет пустым. В первом случае поиск оканчивается удачно, во втором - неудачно. В качестве множества
, либо множество не станет пустым. В первом случае поиск оканчивается удачно, во втором - неудачно. В качестве множества 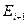 для следующего шага берется правое или левое подмножество текущего шага, причем
для следующего шага берется правое или левое подмножество текущего шага, причем
|
|
|
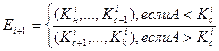
Рис. 2.4 поясняет алгоритм двоичного поиска на примере таблицы из 16 записей и значения аргумента 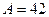 . В этом методе особенно удивительно то, что уже после двух сравнений три четверти таблицы будут вне области поиска.
. В этом методе особенно удивительно то, что уже после двух сравнений три четверти таблицы будут вне области поиска.

Рис.2.4.
Пример двоичного поиска записи в таблице
Двоичный поиск удобно представить в виде двоичного дерева (см. рис.2.5). Вершинами дерева двоичного поиска являются ключи, сравниваемые с аргументом поиска. При этом корнем является ключ записи, сравниваемой на первом шаге. Поиск можно интерпретировать как прохождение дерева от корня до искомой записи. Если достигнута конечная вершина, а заданный ключ не найден, то искомая запись в файле отсутствует. Число вершин на единственном пути от корня к искомой записи равно числу сравнений, выполняемых алгоритмом двоичного поиска при попытке отыскания нужной записи.
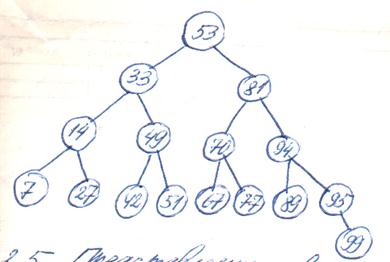
Рис.2.5.
Представление двоичного поиска в виде бинарного дерева
Среднее число сравнений в случае равновероятных запросов равно
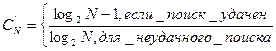
Ни один метод, основанный на сравнении ключей, не может дать лучших результатов при равновероятных запросах.
Рассмотрим случай неравновероятных запросов. Пусть, например, некоторая запись файла запрашивается с вероятностью, намного превосходящей суммарную вероятность запросов остальных записей. В этом случае, очевидно, что, прежде всего, целесообразно проверить эту запись, а только затем - остальные. Приведенные рассуждения показывают, что в случае неравновероятных запросов двоичный поиск, вообще говоря, не является оптимальным.
|
|
|
Даже в случае равновероятных запросов преимущества двоичного поиска не всегда бесспорны. Это, прежде всего, относится к ситуациям, когда время считывания записей непостоянно. В последнем случае доступ к серединным записям может быть сопряжен с большими затратами времени, чем доступ к записям в начале таблицы и алгоритм двоичного поиска оказывается менее эффективным.
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 560; Нарушение авторских прав?; Мы поможем в написании вашей работы!