КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Построение модели парной линейной регрессии
|
|
|
|
Прогнозировать изучаемые процессы можно с помощью регрессионных моделей. Наиболее простая из них – это модель парной линейной регрессии, которая имеет следующий вид:
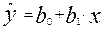 (3.14),
(3.14),
где b0 – свободный член уравнения, отражающий влияние всех неучтенных факторов; b1 – коэффициент при факторе x.
Суть построения модели сводится к определению параметров уравнения (b0, b1). В Excel построение этой модели осуществляется следующим образом.
1. Команда СЕРВИС – АНАЛИЗ ДАННЫХ – РЕГРЕССИЯ
2. Ввести параметры окна (рис. 47).
3. ОК
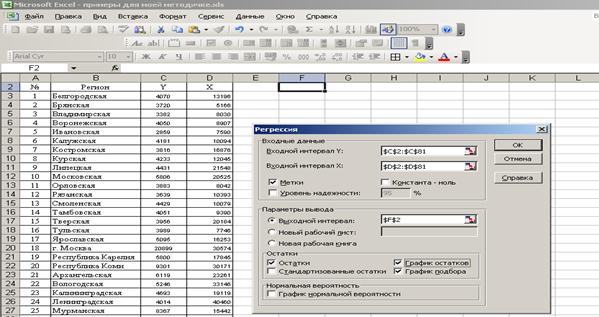
Рис. 47. Ввод параметров окна при построении парной регрессии.
Наиболее наглядно сравнение наблюдаемых значений и полученных с помощью модели иллюстрируется графиком подбора (рис. 48).

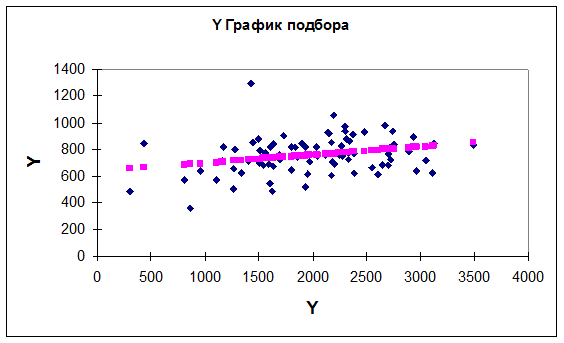
Рис. 48. Соотношение модельных и эмпирических значений Y.
Уравнение регрессии записывается на основе таблицы 2.
Таблица 2
Параметры регрессионного уравнения
| Коэффициенты | Стандартная ошибка | t-статистика | P-Значение | Нижние 95% | Верхние 95% | |
| Y-пересечение | 3873,838 | 311,1546 | 12,4 | 3,99E-20 | 3251,54 | 4496,14 |
| X | 0,078207 | 0,010632 | 7,3 | 1,75E-10 | 0,057 | 0,099 |
В данном случае регрессионное уравнение будет иметь вид:
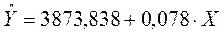 (3.15)
(3.15)
Интерпретировать это уравнение можно следующим образом: при увеличении среднедушевых инвестиций в экономику региона на 1 руб. (Х), среднедушевые доходы населения (Y) возрастут в среднем на 8 коп. при усредненном влиянии прочих факторов.
Качество модели в целом можно оценить множественным коэффициентом детерминации (R-квадрат), который для пары признаков Y и X равен:
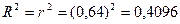 (3.16)
(3.16)
Таким образом, можно сделать вывод, что 41% изменчивости результативного признака Y объясняется изменчивостью признака X, то есть доля объясненной дисперсии результативного признака (Y) фактором (Х) равна 41%, что является достаточно хорошим результатом, учитывая однофакторность модели.
|
|
|
Этот результат подтверждается данными табл. 3, где в строке R-квадрат показано число 0,41, при умножении которого на 100 получаем множественный коэффициент детерминации.
Таблица 3
| ВЫВОД ИТОГОВ | |
| Регрессионная статистика | |
| Множественный R | 0,64 |
| R-квадрат | 0,41 |
| Нормированный R-квадрат | 0,405 |
| Стандартная ошибка | 2189,4 |
| Наблюдения |
Учитывая стохастическую природу построенной модели, необходимо оценить полученное уравнение регрессии с помощью средней ошибки аппроксимации и F-критерия Фишера, а статистическую значимость его параметров - с помощью t-критерия Стьюдента.
Найдем среднюю относительную ошибку аппроксимации по формуле:
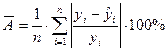 (3.17).
(3.17).
Для вычисления  , согласно формуле (3.17), составим таблицу, фрагмент которой показан на рис.49 в режиме формул и рис. 50 в режиме значений. Здесь в столбце J определяется сумма абсолютных относительных ошибок, а в ячейке К25 – сама средняя относительная ошибка аппроксимации.
, согласно формуле (3.17), составим таблицу, фрагмент которой показан на рис.49 в режиме формул и рис. 50 в режиме значений. Здесь в столбце J определяется сумма абсолютных относительных ошибок, а в ячейке К25 – сама средняя относительная ошибка аппроксимации.

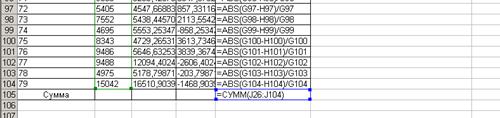
Рис. 49. Фрагмент таблицы расчета средней относительной ошибки аппроксимации в режиме формул
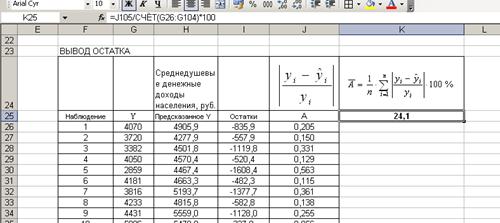
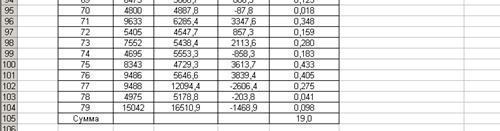
Рис. 50. Фрагмент таблицы расчета средней относительной ошибки аппроксимации в режиме значений
В нашем примере 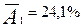 , т.к. значения средней относительной ошибки аппроксимации немногим более 20%, то можно точность уравнения определить как недостаточно высокую. В этом случае возникает вопрос, какие регионы имеют наибольшее отклонение от среднестатистического уровня, определенного с помощью модели
, т.к. значения средней относительной ошибки аппроксимации немногим более 20%, то можно точность уравнения определить как недостаточно высокую. В этом случае возникает вопрос, какие регионы имеют наибольшее отклонение от среднестатистического уровня, определенного с помощью модели  . Осуществим эту задачу с помощью автофильтра.
. Осуществим эту задачу с помощью автофильтра.
Решим задачу: определить первых пять регионов, имеющих наибольшее отклонение значений моделируемого признака от среднестатистического.
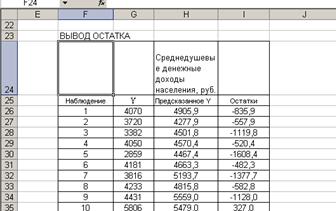
Решение. 1. В результате построения регрессионной модели имеем таблицу остатков (рис. 51).
|
|
|
Рис.51. Таблица остатков
2. Выделяем ее и назначаем режим автофильтра: Данные – Фильтр - Автофильтр.
3. В поле Остатки назначаем режим Первые 10 …, вводим соответствующие параметры (рис. 52):
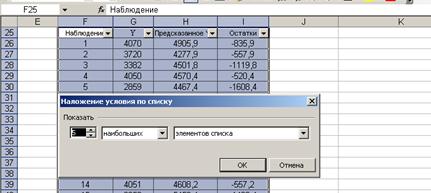
Рис.52. Назначение условий поиска
В результате получаем пять субъектов Федерации, имеющих наибольшее положительное отклонение от среднестатистического значения (рис. 53), т.е. в рамках построенной модели у этих регионов среднедушевые доходы необоснованно высоки.
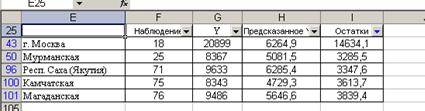
Рис. 53. Субъекты федерации, у которых высокие уровни среднедушевых доходов не обусловлены существующим уровнем инвестиционной активности
Список же регионов с высоким потенциалом уровня среднедушевых доходов получим, выбрав условие «Первые пять – наименьших» (рис. 54).
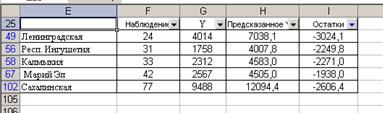
Рис. 54.. Субъекты федерации, у которых согласно построенной модели уровни среднедушевых доходов должны быть выше при существующем уровне инвестиционной активности
Если же остаток равен нулю, то уровень среднедушевых доходов в регионе соответствует среднестатистическому в рамках построенной модели. Однако такой случай в приведенном примере не наблюдался. Наибольшее соответствие эмпирического значения среднедушевых доходов с оценкой, полученной с помощью модели, у Ярославской области.
Исследование статистической значимости уравнения регрессии в целом проводится с помощью F-критерия Фишера-Снедокора. Прежде всего, выдвигается гипотеза Н0 о том, что уравнение в целом статистически незначимо, при конкурирующей гипотезе Н1: уравнение в целом статистически значимо. Расчетное значение критерия находится по формуле:
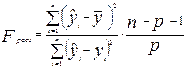 . (3.18)
. (3.18)
Для уравнения парной регрессии p = 1.
Пример получения количественной оценки F-критерия, согласно формуле (3.18), показан в таблице (рис. 55).
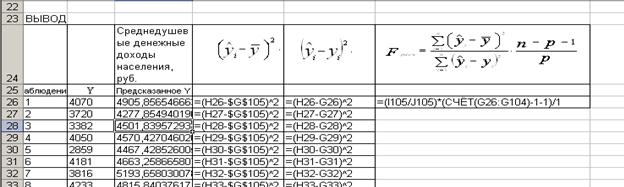

Рис.55. Фрагмент таблицы для расчета количественной оценки F-критерия в режиме формул
В режиме значений таблица получения количественной оценки F-критерия показана на рис. 56.


Рис.55. Фрагмент таблицы для расчета количественной оценки F-критерия
в режиме значений
Табличное (теоретическое) значение критерия находится по таблице критических значений распределения Фишера-Снедекора по уровню значимости α и двум числам степеней свободы (k 1 = p = 1 и k 2 = n – p – 1 = 79 – 1 – 1=77):
|
|
|
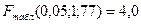 .
.
Если Fрасч<Fтабл, то гипотеза Н0 принимается, а уравнение линейной регрессии в целом считается статистически незначимым (с вероятностью ошибки 5%).
Для уравнения (3.15) Fрасч = 54,1, то есть неравенство не выполняется, следовательно, гипотеза Н0 отвергается. Делаем вывод, что построенная регрессионная модель в целом статистически значима.
Кроме оценки статистической модели в целом, необходимо проверить статистическую значимость оценок всех параметров (b0, b1) линейного уравнения. Осуществляется это с помощью t‑критерия Стъюдента.
Выдвигается гипотеза Н0: параметр bj = 0 (j = 0, 1) (статистически незначим, случайно отличается от 0), при конкурирующей гипотезе Н1: параметр bj ≠ 0 (статистически значим, неслучайно отличается от 0). Находится расчетное значение критерия Стъюдента:
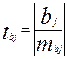 ,
,
где средняя квадратическая ошибка для параметра b0 равна
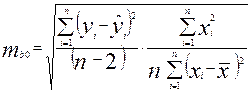 ,
,
а для параметра b1:
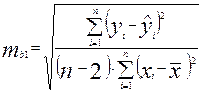 .
.
Расчет этих оценок показан в таблице в режиме формул на рис.56, а в режиме значений на рис. 57.


Рис. 56. Фрагмент таблицы в режиме формул для расчета средних квадратических ошибок для параметров b0 и b1
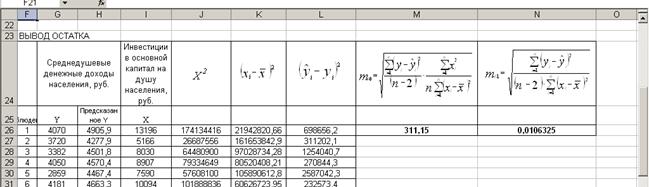
Рис. 57. Фрагмент таблицы в режиме значений для расчета средних квадратических ошибок для параметров b0 и b1
Зная mi, можно определить расчетное значение критерия Стъюдента:
для b0: 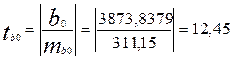
для b1: 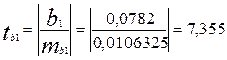
Теоретическое значение критерия tтабл находится по таблице критических значений распределения Стъюдента по уровню значимости α и числу степеней свободы k = n – p – 1. Если tbj > tтабл, то гипотеза Н0 отвергается с вероятность ошибки α, т.е. оценка коэффициента регрессии b j признается статистически значимой, в противном случае (t bj < tтабл) - незначимой.
Табличное значение критерия для уровня значимости α=0,05 и числа степеней свободы k = n – 2 = 79-2=77 равно: 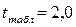
Найдем доверительные интервалы для параметров b0 и b1 уравнения (1).
∆b0= t табл ·mb0=2,0*311,15=622,30;
∆b1 = t табл ·mb1 =2,0*0,0106325=0,021265.
Следовательно, нижняя граница доверительного интервала для b0 равна:
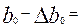 3873,8379 – 622,3 = 3251,54
3873,8379 – 622,3 = 3251,54
Верхняя граница доверительного интервала для b0 равна:
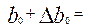 3873,8379 + 622,3 = 4496,14
3873,8379 + 622,3 = 4496,14
|
|
|
нижняя граница доверительного интервала для b1 равна:
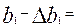 0,07820692– 0,021265 = 0,0569
0,07820692– 0,021265 = 0,0569
Верхняя граница доверительного интервала для b1 равна:
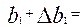 0,07820692+ 0,021265 = 0,099
0,07820692+ 0,021265 = 0,099
Таблица 4
Проверка критерия Стъюдента
| Уравнение регрессии
| ||||||
| Параметр уравнения b j | Среднеквадратическая ошибка параметра 
| Расчетное значение критерия 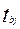
| Табличное значение критерия tтабл | Вывод о статистической значимости | Границы доверительных интервалов | |
| левая | правая | |||||
| b0 | 311,15 | 12,45 | 2,0 | значима | 3251,54 | 4496,14 |
| b1 | 0,0106 | 7,36 | значима | 0,0569 | 0,099 |
В результате проверки на статистическую значимость уравнения в целом, а также каждого его параметра можно сделать вывод о статистической его значимости, то есть построенная модель адекватно отражает рассматриваемое явление.
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 1028; Нарушение авторских прав?; Мы поможем в написании вашей работы!