КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Структуры типа Б-дерева
|
|
|
|
Одним из наиболее важных и распространенных индексов является структура типа Б-дерева (B-tree).
Причина необходимости создания структуры типа Б-дерева заключается в желании избежать обязательного просмотра всего содержимого индексированного файла согласно его физической последовательности. Дело в том, что если индексированный файл имеет большой размер, то и его индекс также очень велик. Поэтому последовательный просмотр даже одного только индекса требует больших затрат времени. Разрешить эту проблему можно тем же способом, что и раньше: рассмотреть индексный файл как обычный хранимый файл и создать для него еще один индекс. Эту операцию можно осуществлять повторно нужное количество раз (обычно она применяется трижды, поскольку создание большого количества иерархических уровней индексирования требуется для очень больших файлов). При этом индекс на каждом из уровней будет неплотным по отношению к нижнему индексируемому уровню (он обязательно должен быть неплотным, иначе такая структура бессмысленна, так как уровень n содержал бы такое же количество записей, что и уровень n+1, а для просмотра потребовалось бы такое же длительное время).
Структура типа Б-дерева является частным случаем индекса древовидного типа и впервые описана в статье Байера (Вауег) и Мак-Крайта (McCreight) в 1972 году. С тех пор Байером и другими исследователями было предложено множество вариантов реализации этой идеи. В результате бинарные индексы различных типов стали широко использоваться во всех современных СУБД.
В варианте Кнута индекс состоит из двух частей:
1. Набор последовательностей включает одноуровневый индекс для реальных данных, который обычно является плотным, но может быть и неплотным, если в индексированном файле проведена кластеризация на основе индекса
|
|
|
2. Набор индексов, в свою очередь, обеспечивает быстрый непосредственный доступ к набору последовательностей (а значит, и к данным). По сути, набор индексов является древовидным индексным файлом для набора последовательностей или, строго говоря, индексом со структурой Б-дерева. Комбинация набора индексов и набора последовательностей называется структурой типа Б-плюс-дерева (B-plus tree или B-tree). На рис. 13.5 показан простой пример такой структуры.
Числа 6, 8, 12,... 97, 99 являются значениями индексированного поля F. Корневой элемент содержит два значения поля F (50 и 82) и три указателя (номера страниц). Данные со значением поля F, равным или меньшим 50, могут быть найдены с помощью левого указателя; данные со значением поля F, большим 50 и равным или меньшим 82, – с помощью среднего указателя; наконец, данные со значением поля F, большим 82, – с помощью правого указателя. Другие элементы набора индексов следует интерпретировать подобным образом. Обратите внимание, что благодаря переходу на второй уровень по левому указателю в дальнейшем поиск по правому указателю будет осуществляться ко всем записям со значением поля F, большим 32 и равным или меньшим 50.
Вообще, Б-дерево порядка п содержит не менее п и не более 2п записей с данными в каждом из элементов структуры (для каждых k записей требуется также k+1 указателей). Кроме того, ни одна из записей не может использоваться двумя разными элементами.
Одним из недостатков иерархических структур является несбалансированность их работы после удаления или вставки некоторых элементов. Дело в том, что в результате таких изменений структуры элементы с реальными данными могут оказаться на разных уровнях и на разных расстояниях от корневого элемента. Поскольку во время поиска при каждом посещении элементов структуры происходит обращение к диску, общая продолжительность поиска в несбалансированной древовидной структуре может оказаться совершенно непредсказуемой.
|
|
|
Преимуществом структуры типа Б-дерева является возможность сбалансированной вставки или удаления значений. (Вот почему для английского написания такого индекса, "B-tree", иногда употребляют вместо символа "В" эпитет от "сбалансированный" (balanced).) Ниже приводится краткий алгоритм вставки нового значения V в структуру типа Б-дерева порядка п. Он рассчитан на вставку значения только лишь в набор индексов, но может быть достаточно просто расширен для вставки записи с данными в набор последовательностей.
1. На самом низком уровне набора индексов следует найти элемент (допустим, что это элемент N), с которым логически связано вставляемое значение V. Если элемент N содержит свободное пространство, то значение V вставляется в него и на этом процесс завершается.
2. В противном случае (если свободного пространства нет, т.е. придется создать еще один уровень) элемент N (допустим, что он содержит 2n индексных записей) разделяется на два элемента – N1 и N2. Обозначим символом 5 множество из 2n+1 значений, в котором 2n исходных значений и одно новое значение V. Тогда n первых значений этой логической (уже упорядоченной) последовательности необходимо поместить в элемент N1, n последних – в элемент N2, а среднее между ними значение W– в родительский элемент Р на более высоком структурном уровне. Впоследствии, при осуществлении поиска значения U и достижении элемента P, поиск будет перенаправлен в сторону элемента N1, если V<W, либо в сторону элемента N2, если U> W.
3. Далее этот процесс следует повторить для вставки среднего значения W в родительский элемент Р на более высоком структурном уровне.
В худшем случае процесс разделения элементов структуры может продлиться вплоть до корневого элемента всей структуры с образованием нового иерархического уровня.
Для удаления некоторого значения следует применить аналогичный алгоритм, но только в обратном порядке. А для изменения значения его можно удалить, а затем вставить новое.
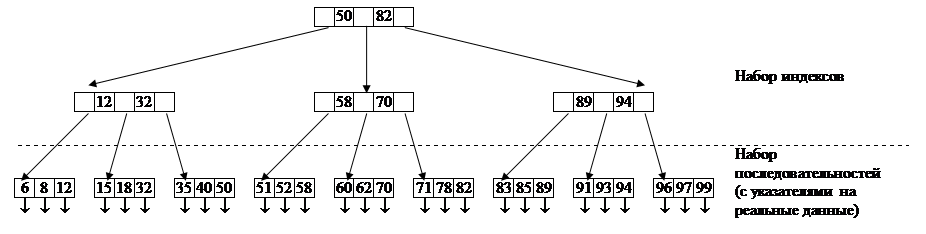 рис. 13.5 Пример структуры типа Б-дерева
рис. 13.5 Пример структуры типа Б-дерева
|
|
|
|
|
Дата добавления: 2014-11-20; Просмотров: 458; Нарушение авторских прав?; Мы поможем в написании вашей работы!