КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Бинарный поиск (дихотомия)
|
|
|
|
Алгоритмы поиска в сортированной таблице
Сортированные таблицы
Последовательные таблицы
Таблицы
В данном разделе рассмотрены плоские таблицы с фиксированным числом столбцов. Примером такой таблицы может служить телефонный справочник:
| Улица | Дом | Кв. | Фамилия И.О. | Телефон |
| Коммуны | Петров П.П. | |||
| Советская | Сидоров.С.С. |
Таблицу идентификаторов строит любой компилятор:
| Идентификатор | Тип | Длина | Адрес |
| Alpha | int | 0xEA45345 |
 Мы не рассматриваем таблиц с двумя входами типа таблицы умножения (рис.30), в которых искомая величина лежит на перекрестии строки и столбца. Строку таблицы называют также записью или кортежем. Столбец также называют полем или атрибутом. Поле или группа полей, по которым выполняется поиск данных в таблице, называется ключом. Если в таблице не может существовать более одной записи с данным значением ключа, то такой ключ называют первичным. Другие ключи называют непервичными или вторичными. В телефонном справочнике роль первичного ключа может играть, например, номер телефона. Фамилия не может быть первичным ключом, так как возможно существование однофамильцев. Все операции в таблице задаются по отношению к ключу, а выполняются над всей записью. К типичным операциям над таблицей относятся:
Мы не рассматриваем таблиц с двумя входами типа таблицы умножения (рис.30), в которых искомая величина лежит на перекрестии строки и столбца. Строку таблицы называют также записью или кортежем. Столбец также называют полем или атрибутом. Поле или группа полей, по которым выполняется поиск данных в таблице, называется ключом. Если в таблице не может существовать более одной записи с данным значением ключа, то такой ключ называют первичным. Другие ключи называют непервичными или вторичными. В телефонном справочнике роль первичного ключа может играть, например, номер телефона. Фамилия не может быть первичным ключом, так как возможно существование однофамильцев. Все операции в таблице задаются по отношению к ключу, а выполняются над всей записью. К типичным операциям над таблицей относятся:
- включение: дана пара ключ - данные. Требуется включить запись в таблицу так, что впоследствии ее можно было найти по ключу.
- поиск. Дан ключ, требуется найти запись.
- модификация: дан ключ, и новые значения изменяемых полей. Требуется найти запись и изменить данные.
- удаление. Дан ключ, требуется найти и удалить запись.
Как видно, во всех случаях, прежде чем выполнить операцию, требуется сначала найти запись. Это относится и к операции включения, так как для того, чтобы добавить запись в таблицу, требуется найти место вставки. Следует различать удачный и неудачный поиск (поиск того, чего в таблице нет), а также поиск единственной записи (по первичному ключу) и поиск многих записей, удовлетворяющих критерию поиска. Эффективность этих операций, как правило, различается. Мы будем рассматривать четыре основных способа организации таблиц:
|
|
|
- последовательные
- сортированные
- древовидные
- рассеянные (они же рандомизированные или hash – таблицы)
Новые записи помещаются в конец таблицы в порядке поступления. Поиск осуществляется перебором записей. Пусть таблица содержит N записей. Для успешного поиска единственной записи требуется просмотреть в среднем N/2 записей; в случае неудачного поиска придется просмотреть всю таблицу, то есть N записей. Поиск по вторичному ключу требует просмотра N записей. В любом случае время поиска пропорционально размеру таблицы.
Для того, чтобы физически удалить запись из таблицы, требуется выполнить сдвиг на одну позицию вверх всех нижележащих записей, что требует значительного времени. Как правило, так не поступают. Вместо этого запись помечают как удаленную в специально отводимом для этого байте. Операция упаковки, то есть физического удаления помеченных на удаление записей производится изредка. Такова, например, дисциплина работы со старейшим форматом файлов баз данных – dbf – форматом. Удаленные записи можно "сшить" в стек свободного пространства и использовать для вставки новых записей.
Последовательные таблицы есть смысл использовать, когда таблица мала или скорость поиска несущественна.
Контрольные вопросы
1) Напишите функцию, выполняющую физическое удаление записей из последовательной таблицы, помеченных символом ‘*’ в 1-м байте.
|
|
|
2) Напишите функцию поиска записи по фамилии в телефонном справочнике, который хранится как последовательная таблица в бинарном файле.
3) Напишите функцию, помещающую новую запись в первую удалённую позицию последовательной таблицы, или в конец таблицы, если удалённые позиции отсутствуют.
В обсуждаемых ниже алгоритмах для упрощения предполагается, что ключи – это целые числа, что никак не сказывается на сути дела. Примеры алгоритмов, свободных от каких – либо допущений будут приведены позже. Отметим, что для любого метода организации таблицы решение задачи поиска может быть сформулировано как решение уравнения Ключ=F(Адрес) относительно адреса при заданном ключе.
Бинарный поиск в сортированной таблице – это разновидность метода деления интервала пополам для решения уравнения f(x)=0.
Действительно, если ключи интерпретировать как числа, то в сортированной таблице они следуют в неубывающем порядке, например, как это изображено на рис. 31.
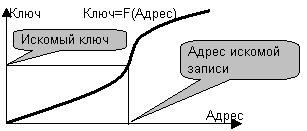
Рис.31. Постановка задачи поиска в сортированной таблице
Приведенный ниже алгоритм отыскивает индекс заданного целого числа в массиве сортированных целых чисел.
int BinSearch(int Key, int n, int t[]){
// int t[] - массив длиной n, в котором производится поиск
// ключа Key
// в случае успеха функция возвращает индекс найденного
// элемента, а в случае неудачи - тот индекс, на котором
// находился бы ключ, если бы он был в таблице
int i,j,k;
i=0;j=n-1;
while(j>i+1){
k=(i+j)/2; // середина интервала
if(t[k]==Key) return k;
if(t[k]<Key){
i=k;
} else {
j=k;
}
}
if(t[i]<Key){
k=j;
} else {
k=i;
}
return k;
}
Очевидно, что число делений интервала пополам не превышает 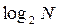 . Это и есть оценка быстродействия бинарного поиска. Функция bsearch, выполняющая бинарный поиск, входит состав библиотек, поставляемых практически с любым компилятором, и имеет прототип:
. Это и есть оценка быстродействия бинарного поиска. Функция bsearch, выполняющая бинарный поиск, входит состав библиотек, поставляемых практически с любым компилятором, и имеет прототип:
void *bsearch(const void *key, const void *base, size_t nelem, size_t width, int (*fcmp)(const void *a, const void *b));
Аргументы:
- key – адрес записи, имеющей структуру такую же, как и запись таблицы. В этой записи заполнены только поля, составляющие ключ.
- base – адрес начала таблицы
- nelem – число записей в таблице
- width – длина записи в байтах
- fcmp – функция, определяемая пользователем, которая сравнивает ключи записей, имеющих адреса a и b и возвращает –1 (*a<*b), 0(*a==*b) и 1(*a>*b).
|
|
|
Функция bsearch возвращает адрес найденной записи или NULL.
Для поиска в сортированной таблице могут быть использованы любые методы решения уравнения Ключ=F(Адрес), в частности метод золотого сечения и интерполяционные методы.
|
|
|
|
|
Дата добавления: 2014-12-08; Просмотров: 757; Нарушение авторских прав?; Мы поможем в написании вашей работы!