КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекции по теме 4: Обработка результатов экспериментов 2 страница
Прежде, чем проводить сам дисперсионный анализ, необходимо определить понятия группового среднего и общего среднего. Предположим, что в ходе проведения эксперимента «подключается» некоторый фактор 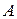 , который может принимать
, который может принимать 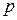 значений. Для каждого из этих значений фактора проводится серия опытов, в ходе которых измеряется
значений. Для каждого из этих значений фактора проводится серия опытов, в ходе которых измеряется 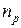 результатов. Результаты, принадлежащие одному и тому же уровню фактора, будут составлять единую группу, и таких групп будет .
результатов. Результаты, принадлежащие одному и тому же уровню фактора, будут составлять единую группу, и таких групп будет .
Результаты эксперимента обозначим как 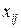 – значениями
– значениями 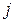 -членов в
-членов в 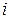 - группе. При этом будет изменяться от 1 до (индикатор члена группы), а изменяется от 1 до (индикатор группы). Тогда среднее значение каждой группы равно:
- группе. При этом будет изменяться от 1 до (индикатор члена группы), а изменяется от 1 до (индикатор группы). Тогда среднее значение каждой группы равно:
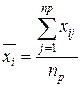
где 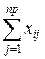 – сумма всех значений в -группе, а - число всех значений – группы. Общее среднее равно (
– сумма всех значений в -группе, а - число всех значений – группы. Общее среднее равно (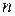 – общее число проведенных экспериментов, – число -групп):
– общее число проведенных экспериментов, – число -групп):
 .
.
Построим алгоритм однофакторного дисперсионного анализа.
1) Определим дисперсию безотносительно к значению, который принимает фактор (общая группировка). Для этого вычислим квадраты отклонений каждого из полученных значений от общего среднего, данные квадраты просуммируем
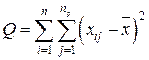 .
.
Выбор квадратов отклонений связан с тем, что отклонения могут принимать как положительные, так и отрицательные значения. Если рассматривать просто сумму отклонений значений от среднего, может возникнуть эффект компенсации положительного и отрицательного значений. В этом случае получаемая сумма будет либо слишком мала, либо равна 0. Более того, оценка дисперсии будет неверной.
Затем сумму квадратов 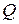 разделим на число степеней свободы (ЧСС) данного эксперимента, определяемое как число опытов – 1:
разделим на число степеней свободы (ЧСС) данного эксперимента, определяемое как число опытов – 1: 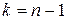 .
.
2) Определим дисперсию при условии влияния фактора , для чего находятся отклонения групповых средних от общей средней (если фактор действительно оказывает влияние, такие отклонения должны быть значимыми, что можно оценить с помощью дисперсий). Схема рассуждений такая же, как и в предыдущем случае. Здесь число степеней свободы будет определяться как число значений, принимаемых фактором, – 1: 
3) И, наконец, определяем дисперсию значений, вызываемую случайными причинами (погрешность средств измерений, влияние окружающей среды и т.п.) Данную дисперсию вычисляют, учитывая следующее. Изменение значений эксперимента может вызываться либо случайными явлениями, либо изменением значений факторов. Если «убрать» изменение значений факторов, то вариация значений эксперимента будет проявляться только за счет случайной компоненты. Таким образом, необходимо отклонение значений эксперимента от среднего в каждой группе значений факторов. Для этого вычисляются квадраты отклонений внутри каждой группы, т.е. при значении фактора, равного 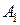 , оценивается отклонение значений, полученных при таких условиях эксперимента, от своего среднего
, оценивается отклонение значений, полученных при таких условиях эксперимента, от своего среднего 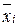 для , при
для , при 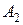 – отклонение значений от своего среднего для A2 и т.д. В статистике доказано, что
– отклонение значений от своего среднего для A2 и т.д. В статистике доказано, что 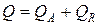 . Два параметра из этой суммы нам известны, так что найти недостающее
. Два параметра из этой суммы нам известны, так что найти недостающее 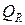 будет несложно.
будет несложно.
4) Оценим, влияет ли исследуемый фактор на результат эксперимента. Это можно сделать с помощью критерия согласия Фишера.
При проверке следуем простой логике: если разброс значений эксперимента при изменении фактора не отличается от разброса значений эксперимента при фиксированном значении фактора (т.е. вызываемого чисто случайными причинами), то фактор не оказывает никакого влияния на результаты.
Строим основную и альтернативную гипотезы:
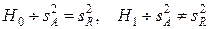
Согласно критерию Фишера (смотри приложение основной литературы), если отношение межгрупповой дисперсии к внутригрупповой меньше квантиля распределения Фишера при заданном уровне 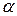 :
:
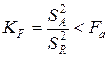 ,
,
то дисперсии считаются статистически неразличимыми, т.е. фактор не оказывает влияния на результат эксперимента. В противном случае – дисперсии статистически различимы, и фактор оказывает влияние на результат.
Замечание. В отличие от классического критерия согласия Фишера – Снедекора, при проверке различия между межгрупповой и внутригрупповой дисперсиями в числителе ВСЕГДА стоит межгрупповая дисперсия, даже если она с математической точки зрения меньше внутригрупповой.
5) В случае, если дисперсионный анализ обнаруживает наличие существенного влияния факторов на результат эксперимента, необходимо оценить, какой из уровней (значений) факторов оказывает наиболее существенное влияние. С этой целью при помощи критерия согласия Стьюдента производится сравнение средних значений, полученных при различных значениях уровней факторов (см. схему анализа, последнюю строку). Для сравнения одно из средних значений принимается за основное (базовое), а остальные сравниваются именно с этим значением.
Если значение критерия меньше квантиля распределения Стьюдента при заданном уровне значимости 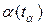 , то средние считаются статистически неразличимыми, т.е. разницы в смене уровня фактора по сравнению с основным уровнем – нет. В противном же случае – данный уровень фактора признается как наиболее сильно влияющий на результаты.
, то средние считаются статистически неразличимыми, т.е. разницы в смене уровня фактора по сравнению с основным уровнем – нет. В противном же случае – данный уровень фактора признается как наиболее сильно влияющий на результаты.
Табличный процессор MS Excel
В настоящее время трудно найти человека, не имеющего персональный компьютер и минимально необходимый набор программ, в том числе и MS Office, т.е. Word, Excel и т.д. Можно использовать возможности такой стандартной программы как Excel для работы с критериями согласия, в корреляционном, регрессионном анализе и т.д.
Для оценки статистических параметров распределений (моды, медианы
и т.п.) в мастере функций необходимо выбрать категорию «Статистические», а в ней – найти желаемую функцию.
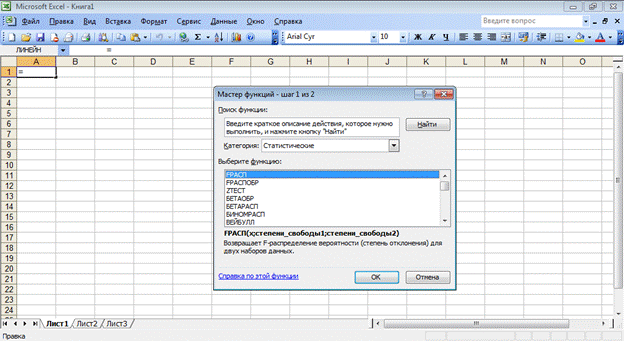
Рис.1. Вид окна мастера функций
Таблица 1
Статистические функции Excel для оценки параметров распределений
| Функция Excel | Описание |
| СРЗНАЧ (число1; число2;…) | Оценивает среднее значение по одной или нескольким выборкам. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| ДИСП(число1; число2;…) | Оценивает дисперсию выборки или нескольких выборок. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| МАКС (число1; число2;…) | Оценивает максимальное значение в одной или нескольких выборках. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| МИН (число1; число2;…) | Оценивает минимальное значение в одной или нескольких выборках. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| МЕДИАНА (число1; число2;…) | Оценивает медиану одной или нескольких выборок. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| МОДА (число1; число2;…) | Оценивает моду одной или нескольких выборок. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой |
| СТАНДОТКЛОН (число1; число2;…) | Оценивает стандартное отклонение по одной или нескольким выборкам. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| СКОС (число1; число2;…) | Оценивает асимметрию одной или нескольких выборок. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| ЭКСЦЕСС (число1; число2;…) | Оценивает эксцесс по одной или нескольким выборкам. При этом будет вычислено ОДНО общее значение для всех совокупностей. Число1, число2… – может быть не только отдельным числом, но и целой выборкой. |
| КВАРТИЛЬ (массив; часть) | Оценивает квартиль экспериментальной выборки. Массив – выборка данных; часть – определяет какой квартиль вычисляется (0 – минимальное значение выборки; 1 – нижний, 25 %-ый, квартиль; 2 – средний, 50 %-ый, квартиль или медиана; 3 – верхний, 75 %-ый, квартиль; 4 – максимальное значение выборки). |
ПЕРСЕНТИЛЬ (массив; 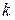 ) )
| Оценивает квартиль экспериментальной выборки. Массив – выборка данных; – определяет порядок вычисляемого персентиля (например, при 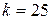 будет вычислен нижний квартиль). будет вычислен нижний квартиль).
|
| FРАСПОБР(вероятность; степени_свободы1; степени_свободы2) | Определяет значение квантиля распределения Фишера (т.е. критического значения). Вероятность – уровень значимости , задаваемый в процентах или долях от единицы.
|
| СТЬЮДРАСПОБР (вероятность; степени_свободы) | Определяет значение квантиля распределения Стьюдента (т.е. критического значения). Вероятность – уровень значимости , задаваемый в процентах или долях от единицы.
|
| ХИ2ОБР(вероятность; степени свободы) | Определяет значение квантиля 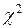 –распределения Пирсона (т.е. критического значения). Вероятность – уровень значимости , задаваемый в процентах или долях от единицы. –распределения Пирсона (т.е. критического значения). Вероятность – уровень значимости , задаваемый в процентах или долях от единицы.
|
С помощью перечисленных функций можно довольно-таки быстро и точно производить статистическую обработку данных, сокращая тем самым себе 3-5 (и более) часов, в зависимости от объемов обрабатываемых данных. Огромный плюс от наличия данных функций – критические значения того или иного критерия согласия всегда находятся «под рукой». Не надо искать специальные сборники таблиц со статистическими распределениями.
Кроме того, в таблицах критических значений, доступных большинству пользователей содержится обычно ограниченный набор данных. Excel же предоставляет, фактически, неограниченные возможности по поиску значений.
Для статистического анализа данных и планирования эксперимента необходимо установить в программе Excel надстройку «Анализ данных». Она представлена в установочных дисках MS Office. При установке полного комплекта программы Excel достаточно лишь активировать данную надстройку.
Для этого необходимо проделать следующее.
I. При работе в MS Office 2003
1.1. Войти в меню «Сервис»
1.2. Выбрать пункт «Надстройки»
1.3. В открывшемся окне выбрать пункт «Пакет анализа» и установить напротив данного пункта маркер. Нажать на кнопку «ОК». Если программа запросит установочный диск для установки данного пакета, введите в дисковод установочный диск, с которого устанавливался MS Office на Вашем компьютере и нажмите еще раз «ОК».
1.4. По окончании установки, зайдите в меню «Сервис» и найти в самом конце меню пункт «Анализ данных».
II. При работе в MS Office 2007 или 2010
2.1. В левом верхнем углу нажать кнопку «Office» и выбрать в правом нижнем углу открывшегося меню кнопку «Параметры Excel». В открывшемся окне в пункте «Управление» выбрать «Надстройки Excel» и нажать на кнопку «Перейти…». В окне «Надстройки» установить маркер в пункте «Пакет анализа» и нажать кнопку «ОК». После окончания установки в программе Excel на закладке «Данные» появляется секция «Анализ» с кнопкой «Анализ данных», нажав на которую можно вызвать на экран «Пакет анализа данных».
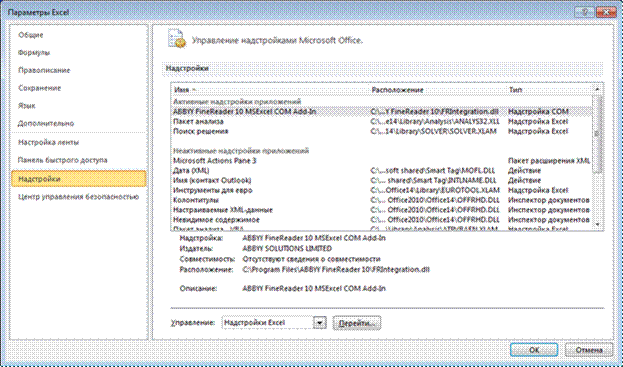
Рис.2. Окно «Параметры Excel»
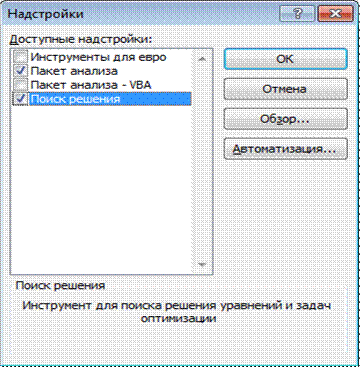
Рис.3. Окно «Надстройки» с выделенным пунктом «Пакет анализа»
После установки пакета «Анализ данных» при выборе соответствующего пункта на экране появится окно «Анализа данных».
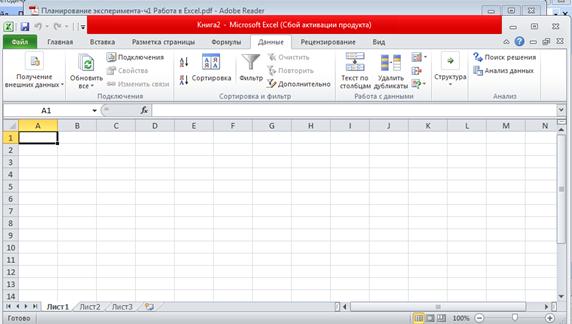
Рис.4. Закладка «Данные» на панели инструментов с выделенной секцией «Анализ»
Здесь находится весь необходимый для анализа данных и планирования эксперимента инструментарий.
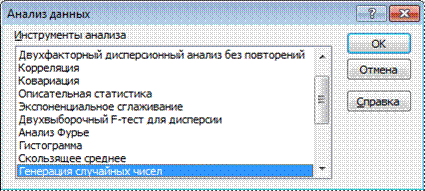
Рис.5. Окно «Анализ данных»
Рассмотрим лишь некоторые инструменты анализа, затронутые в данном учебном пособии. Заметим, что некоторые из этих инструментов (корреляционный анализ, критерии согласия) можно попытаться определить с помощью статистических функций, но, на мой взгляд, это несколько неудобно. Вы же можете пользоваться по своему усмотрению или статистическими функциями, или же инструментами анализа.
Графики, диаграммы
Таблицы.Таблица - это список приближенных (или точных) значений какой-либо функции при разных (точных!) значениях аргумента (или аргументов). Входом таблицы называют значения аргументов функции. Шагом называют интервал задания аргумента. Таблицы могут быть с одним или двумя входами. В первом случае она может быть оформлена в виде двух колонок (в одной – аргумент, в другой – функция).
Статистическая таблица– это особый способ краткой и наглядной записи сведений об изучаемых общественных явлениях. По внешнему виду статистическая таблица представляет собой ряд пересекающихся горизонтальных и вертикальных линий, образующих по горизонтали строки, а по вертикали – графы (столбцы, колонки), которые в совокупности составляют как бы скелет таблицы.
В образовавшиеся внутри таблицы клетки записывается информация. Составленную таблицу принято называть макетом таблицы.
Составленная и оформленная статистическая таблица должна иметь общий заголовок, боковые и верхние заголовки. Одними из ответственных моментов построения статистических таблиц являются разработка сказуемого, определение его содержания, правильное установление связи между группировочными признаками и показателями, их характеризующими.
График - современную науку невозможно представить без применения графиков. Они стали средством научного анализа и обобщения. Такие свойства графиков, как выразительность, доходчивость, лаконичность, универсальность, смысловая однозначность, легкость кодирования, а также обозримость графических изображений сделали их незаменимыми в исследовательской и практической работе.
График может иллюстрировать функциональную зависимость или служить вычислительным средством, позволяющим по значению одной переменной «считать» с чертежа значение второй переменной. Если в первом случае шкалы могут быть схематическими, скелетными, то во втором они должны быть детальными. График обычно помещают в рамку, на сторонах этой рамки наносят штрихи шкал. Как правило, штрихи направляют внутрь рамки, а обозначения переменных и единицы измерения - вне. Необходимо следить, чтобы поле чертежа было использовано оптимально. Пустое поле можно занять какой-либо дополнительной информацией. Для наилучшей демонстрации функциональной зависимости необходимо подобрать наиболее подходящие шкалы.
Статистический график– чертеж, на котором при помощи условных геометрических фигур (линий, точек или других символических знаков) изображаются статистические данные.
Диаграммапредставляет чертеж, на котором статистическая информация изображается посредством геометрических фигур или символических знаков.
Наиболее простой вид диаграммы – это столбиковые диаграммы,при которых построение данных изображается в виде столбиков от количественных значений изображаемых величин по определенному масштабу.
Разновидностью столбиковых диаграмм являются ленточные диаграммы, изображающие размеры признака в виде расположенных по горизонтали прямоугольников одинаковой ширины, но различной длины, пропорционально изображаемым величинам.
Ленточная диаграммапредставляет ряд простирающихся по оси абсцисс полос одинаковой ширины. Длина полос (лент) должна соответствовать значениям изображаемых показателей. В таких диаграммах удобно располагать надписи. Ее также используют для характеристики отдельных единиц совокупности. Достоинство линейных графиков в том, что на одном и том же поле графика можно изобразить несколько показателей, которые позволят сравнить и выявить специфику их развития во времени или характере изменения одного показателя по различным объектам в пространстве или на территории.
Линейные графики иногда строятся с логарифмической шкалой по оси ординат. В статистике коммерческой деятельности строятся графики с равномерной шкалой. Координатную сетку, в которой по оси абсцисс нанесена шкала в равномерном масштабе, принято называть арифметической.
Графики с равномерной шкалой по оси ординат дают достаточно наглядное представление об изменениях изучаемых абсолютных показателей.
При построении столбиковых диаграмм используется прямоугольная система координат. Значение изучаемого показателя изображается в виде вертикального столбика. Количество столбиков определяется числом изучаемых показателей (данных).
Столбиковые и полосовые диаграммы подходят для характеристики структуры совокупности. Структура состава воспринимается лучше в относительных величинах.
Диаграммы, в которых сравниваемые величины изображаются в виде правильных геометрических фигур, строятся так, чтобы площади их соотносились между собой как значения величин, этими фигурами изображаемых. Эти диаграммы должны выражать величину изображаемого явления размером своей площади. Для построения квадратных и круговых диаграмм необходимо из статистических данных извлечь квадратные корни, затем определить сторону квадрата или радиус круга соответственно принятому масштабу.
Все перечисленные графики и диаграммы можно построить с помощью программы Excel –мастера диаграмм (что будет нами рассмотрено на практическом занятии).
Описательная статистика и обработка экспериментальных данных
Слово «статистика» часто ассоциируется со словом «математика», и это пугает иногда исследователей, связывающих данное понятие со сложными формулами, требующими высокого уровня абстрагирования.
Известно, что статистика – это, прежде всего, способ мышления, и для ее применения нужно лишь иметь немного здравого смысла и знать основы математики. В нашей повседневной жизни мы, сами о том не догадываясь, постоянно занимаемся статистикой. Хотим ли мы спланировать бюджет, рассчитать потребление бензина автомашиной, оценить условия, которые потребуются для усвоения какого-то курса с учетом полученных до сих пор отметок, предусмотреть вероятность хорошей и плохой погоды по метеорологической сводке или вообще оценить, как повлияет то или иное событие на наше личное или совместное будущее, нам постоянно приходится отбирать, классифицировать и упорядочивать информацию, связывать ее с другими данными так, чтобы можно было сделать выводы, позволяющие принять верное решение.
Все эти виды деятельности мало отличаются от тех операций, которые лежат в основе научного исследования и состоят в синтезе данных, полученных на различных группах объектов в том или ином эксперименте, в их сравнении с целью выяснить показатели, изменяющиеся в одном направлении, и, наконец, в предсказании определенных фактов на основании тех выводов, к которым приводят полученные результаты. Именно в этом заключается цель статистики в науках вообще, особенно в гуманитарных. В последних нет ничего абсолютно достоверного, и без статистики выводы в большинстве случаев были бы чисто интуитивными и не могли бы составлять солидную основу для интерпретации данных, полученных в других исследованиях.
Для того, чтобы оценить огромные преимущества, которые может дать статистика, мы попробуем проследить за ходом расшифровки и обработки данных, полученных в эксперименте. Нам будет полезно рассмотреть в самых общих чертах три главных раздела статистики.
1. Описательная статистика, как следует из названия, позволяет описывать, подытоживать и воспроизводить в виде таблиц или графиков данные того или иного распределения, вычислять среднее для данного распределения и его размах и дисперсию.
2. Задача индуктивной статистики – проверка того, можно ли распространить результаты, полученные на данной выборке, на всю популяцию, из которой взята эта выборка. Иными словами, правила этого раздела статистики позволяют выяснить, до какой степени можно путем индукции обобщить на большее число объектов ту или иную закономерность, обнаруженную при изучении их ограниченной группы в ходе какого-либо наблюдения или эксперимента. Таким образом, при помощи индуктивной статистики делают какие-то выводы и обобщения исходя из данных, полученных при изучении выборки.
3. Наконец, измерение корреляции позволяет узнать, насколько связаны между собой две переменные, чтобы можно было предсказывать возможные значения одной и них, если мы знаем другую.
Существуют две разновидности статистических методов или тестов, позволяющих делать обобщение или вычислять степень корреляции. Первая разновидность – это наиболее широко применяемые параметрические методы, в которых используются такие параметры, как среднее значение или дисперсия данных. Вторая разновидность – это непараметрические методы, оказывающие неоценимую услугу в том случае, когда исследователь имеет дело с очень малыми выборками или с качественными данными; эти методы очень просты с точки зрения как расчетов, так и применения.
Введем некоторые основные понятия.
Популяция и выборка. Одна из задач статистики состоит в том, чтобы анализировать данные, полученные на части популяции с целью сделать выводы относительно популяции в целом.
Популяция в статистике не обязательно означает какую-либо группу людей или естественное сообщество; этот термин относится ко всем существам или предметам, образующим общую изучаемую совокупность, будь то атомы или студенты, посещающие то или иное учебное заведение.
Выборка – это небольшое количество элементов, отобранных с помощью научных методов так, чтобы она была репрезентативной, то есть отражала популяцию в целом.
Данные и их разновидности. Данные в статистике – это основные элементы, подлежащие анализу. Данными могут быть какие-то количественные результаты, свойства, присущие определенным членам популяции, место в той или иной последовательности – в общем, любая информация, которая может быть классифицирована или разбита на категории с целью обработки.
Построение распределения – это разделение первичных данных, полученных на выборке, на классы или категории с целью получить обобщенную упорядоченную картину, позволяющую их анализировать.
Существуют три типа данных:
1. Количественные данные, получаемые при измерениях (например, данные о весе, размерах, температуре, времени, результатах тестирования и т.п.). Их можно распределить по шкале с равными интервалами.
2. Порядковые данные, соответствующие местам этих элементов в последовательности, полученной при их расположении в возрастающем порядке (1-й, …, 7-й, …, 100-й; А, Б, В, …).
3. качественные данные, представляющие собой какие-то свойства элементов выборки или популяции. Их нельзя измерить и единственной их количественной оценкой служит частота встречаемости.
Из всех этих типов данных только количественные данные можно анализировать с помощью методов, в основе которых лежат параметры. Такие, например, как средняя арифметическая. Но даже к количественным данным такие методы можно применять лишь в том случае, если число этих данных достаточно, чтобы проявилось нормальное распределение.
Итак, для использования параметрических методов, в принципе необходимы три условия: данные должны быть количественными, их число должно быть достаточным, а их распределение – нормальным. Во всех остальных случаях всегда рекомендуется использовать непараметрические методы.
Описательная статистика позволяет обобщать первичные результаты, полученные при наблюдении или в эксперименте. Процедуры здесь сводятся к группировке данных по их значениям, построению распределения их частот, выявлению центральных тенденций распределения (например, средней арифметической) и, наконец, к оценке разброса данных по отношению к найденной центральной тенденции.
Вопросы для самоконтроля:
1. Полигон, гистограмма.
2. Корреляционно-регрессионный метод анализа.
3. Как вы понимаете сущность корреляционной связи? В чем ее отличие от функциональной связи?
4. Каковы признаки парной корреляции?
5. Что значит найти уравнение регрессии?
6. Какой вид имеет система нормальных уравнений?
7. С помощью каких коэффициентов можно определить степень тесноты парной линейной зависимости?
8. С чем связаны преимущества выборочного метода?
9. Генеральная совокупность и выборка.
10. Статистические оценки распределения.
11. Особенности дисперсионного анализа.
12. Обработка информации с использованием MS Excel.
|
|
Дата добавления: 2014-12-10; Просмотров: 919; Нарушение авторских прав?; Мы поможем в написании вашей работы!