КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм Лемпеля-Зива
|
|
|
|
Алгоритм названный так по первым буквам фамилий авторов и году своего опубликования. Классический алгоритм предельно прост, и может быть описан следующим образом: "если в прошедшем ранее выходном потоке уже встречалась подобная последовательность байт, причем запись о ее длине и смещении от текущей позиции короче чем сама эта последовательность, то в выходной файл записывается ссылка (смещение, длина), а не сама последовательность".
Пример 1: Строка "КОЛОКОЛ_ОКОЛО_КОЛОКОЛЬНИ" с помощью алгоритма LZ77 будет закодирована строкой "КОЛО(-4,3)_(-5,4)О_(-14,7)ЬНИ".
Пример 2: Строка "ААААААА" с помощью алгоритма LZ77 будет закодирована "А(-1,6)". С помощью алгоритма RLE она же будет закодирована как "(А,7)". Видно, что степень сжатия такой последовательности алгоритмом LZ77 несколько ниже. В тоже время алгоритм LZ77 более универсален.
Основу алгоритма составляют четыре базовых принципа:
- Каждая очередная закодированная последовательность символов добавляется к ранее закодированным символам таким образом, что вместе с ними она образует разложение всей исходной последовательности на несовпадающие между собой фразы.
- Разложение хранится в памяти и используется в дальнейшем в качестве словаря.
- Кодирование осуществляется при помощи указателей на фразы из уже сформированного словаря фраз.
- Кодирование является динамической процедурой, ориентированной на блоки. Сам процесс кодирования может быть дополнен скользящими окнами, содержащими текущий словарь фраз и окно просмотра.
Скользящий (sliding) словарь V объемом |V|= 2...32 кБ. В качестве словаря используются |V| байт сжимаемого текста, предшествующие текущему кодируемому символу в позиции pos (отсюда и название “скользящий”-словарь как бы скользит вдоль по тексту от его начала к концу, поддерживая самую свежую информацию о его содержании). Перед началом процесса компрессии словарь пуст (см. рис 1 а).
Под строкой будем понимать любую непрерывную последовательность символов (букв), начинающаяся с определенной позиции в словаре или в тексте, длиной |s| £ smax. smax обычно выбирается из диапазона 16...256 байт. Словами в словаре выступают любые строки длины не более smax, начинающиеся в любой позиции словаря. Таким образом, в словаре всегда присутствует |V| - smax слов.
Если очередная входная строка s текста совпадает со строкой из словаря, то она заменяется на указатель ptr вида ptr= < 1, distance, length>. Если же строки s в словаре не оказалось, генерируется код chr вида chr = <0, symbol >, где symbol -текущий символ исходного текста.
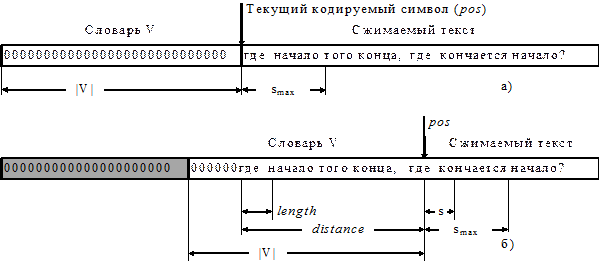
На рис 1. б) показан вид словаря и кодируемого текста на 23-ем символе, когда алгоритм обнаружил совпадение слова “где “ с таким же словом в словаре длиной length = 4 байта, на расстоянии distance =23 байта от текущей позиции pos. Будет сгенерирован код ptr =<1,23,4>.
Префикс, как видно, нужен для того, чтобы отличить код ptr от кода chr. Именно префикс вносит в алгоритм кодирования LZ77 некоторую дополнительную информацию, из-за которой возможно возрастание избыточности. Длина ptr -кода
|ptr| = 1 + élog(| V|)ù + élog (| smax|)ù (бит),
chr -кода
|chr| = 1 + élog(| symbol|)ù (бит).
Очевидно, что если длина ptr -кода в байтах превышает length, то такое кодирование лишь увеличит избыточность, поэтому в алгоритм вводят порог (threshold), равный обычно 2-3 байтам и, если совпадающая строка короче этого порога, она записывается в явном виде посредством chr -кодов.
Обратное восстановление текста осуществляется значительно быстрее и проще процедуры кодирования. Поскольку к моменту декодирования очередного символа весь предыдущий текст уже известен, то декодеру не требуется передавать словарь. Словарь строится декодером автоматически по тому же алгоритму, на основе уже полученных символов. Если декодер обнаруживает, что поступил chr -код, он просто копирует symbol в выходной поток и в словарь, передвигая затем словарь на одну позицию вслед за текстом. Если же поступил ptr -код, декодер копирует length символов, начиная с позиции distance в словаре. Напомним, что distance отсчитывается от конца словаря к началу.
Все характеристики “классического” варианта алгоритма почти целиком определяются размером словаря |V| и максимальной длиной строк в словаре smax.
Высокоэффективным оказывается способ двухступенчатого кодирования информации, когда выходной поток кодировщика LZ77 поступает на вход блока арифметического кодера (LZARI) или кодера Хаффмена (LZHUF). Подобное решение, используемое в архиваторах LHA, ARJ, PKZIP, RAR делает их одними из самых эффективных и популярных в настоящий момент.
Алгоритм LZ78, предложенный в 1978 г. Лемпелом и Зивом, нашел свое практическое применение только после реализации LZW84, предложенной Уэлчем (Welch) в 1984 г. Этот алгоритм является одним из наиболее оптимальных с точки зрения сочетания степени сжатии и скорости работы.
В отличие от предыдущего (LZ77), в данном алгоритме понятия строки и словаря несколько изменены. Словарь является расширяющимся (expanding). Первоначально в нем содержится только 256 строк длиной в одну букву – все коды ASCII. В процессе работы словарь разрастается до своего максимального объема |Vmax| строк (слов). Обычно, объем словаря достигает нескольких десятков тысяч слов. Каждая строка в словаре имеет свою известную длину и этим похожа на привычные словари и отличается от строк LZ77, которые допускали использование подстрок. Таким образом, количество слов в словаре точно равно его текущему объему. В процессе работы словарь пополняется по следующему алгоритму:
В словаре ищется слово str, максимально совпадающее с текущим кодируемым словом в позиции pos исходного текста. Так как словарь первоначально не пустой, такое слово всегда найдется.
В выходной файл помещается номер найденного слова в словаре position и следующий символ из входного текста B (на котором обнаружилось различие) - < position, B >. Длина кода при этом равна | position |+| B |= élog Vmaxù + 8 (бит).
Если словарь еще не полон, новая строка str+B добавляется в словарь по адресу last_position, размер словаря возрастает на одну позицию;
Указатель в исходном тексте pos смещается на | strB | = | str | + 1 байт дальше к символу, следующему за В.
В таком варианте алгоритм почти не нашел практического применения и был значительно модернизирован. Изменения коснулись принципов управления словарем и способа формирования выходного кода:
- так как словарь увеличивается постепенно и одинаково для кодера и декодера, для кодирования позиции нет необходимости использовать élog Vmaxù бит, а можно брать лишь élog Vù бит, где V - текущий объем словаря.
- самая серьезная проблема LZ78-переполнение словаря: если словарь полностью заполнен, прекращается его обновление и процесс сжатия может ухудшиться. Отсюда следует вывод - словарь нужно иногда обновлять, но когда и как значительно? Самый простой способ - как только словарь заполнился его полностью обновляют. Недостаток очевиден – кодирование начинается на пустом месте, как бы с начала, и пока словарь не накопится, степень сжатия будет небольшой. Более сложные алгоритмы используют два словаря, которые заполняются синхронно, но с задержкой на |V|/2 слов один относительно другого. После заполнения одного словаря, он очищается, а работа переключается на другой. Еще более сложными являются эвристические методы обновления словарей в зависимости от частоты использования тех или иных слов.
Выходной код также формируется несколько иначе. В словаре ищется слово str, максимально совпадающее с текущим кодируемым словом в позиции pos исходного текста. В выходной файл помещается номер найденного слова в словаре < position >. Длина кода равна | position | = élogVù (бит). Если словарь еще не полон, новая строка strB добавляется в словарь по адресу last_position, размер словаря возрастает на одну позицию. Указатель в исходном тексте pos смещается на | str | байт дальше к символу В.
|
|
|
|
|
Дата добавления: 2014-12-16; Просмотров: 2542; Нарушение авторских прав?; Мы поможем в написании вашей работы!