КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Лекция 17. Интерфейсы стандарта РС. Внутренние шины стандарта РС
17.1. Классификация интерфейсов
Интерфейсом называется способ соединения различных устройств системы. На рис.17.1 приведена классификация различных интерфейсов.
Наиболее часто используемыми интерфейсами являются:
ISA – архитектура индустриального стандарта – шина, разработанная для IBM/PC. Имеет две модификации ISA-8 и ISA-16. В настоящее время не поддерживается в новых разработках.
PCI – Peripheral Component Interconnect – периферийное соединение компонентов. Универсальная шина для Pentium-систем. Получила дальнейшее развитие в шинах PCI-X, AGP и PCI-Exp.
PS/2 – порты для подключения мыши и клавиатуры.
IDE – Integrated Drivers Electronics - интерфейс подключения жестких дисков. Часто используется эквивалент ATA – AT (улучшенный) attachment или SATA – последовательный ATA. eSATA – для внешних подключений.
SCSI (скази) – Small Computer System Interface – высокоскоростной интерфейс для рабочих станций.
LAN – Local Area Network - сетевое соединение.
IrDA – InfraRed Data Association.
MIDI – Musical Instrumens Digital Interface – интерфейс для подключения музыкальных инструментов.
USB – универсальная последовательная шина.
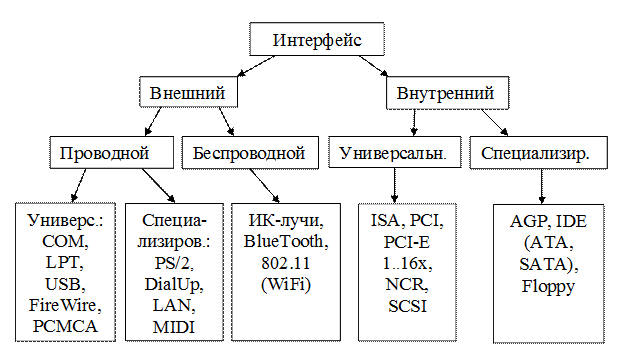
Рис. 17.1. Классификация интерфейсов
Основные характеристики интерфейсов сведены в таблицу 17.1.
Таблица 17.1
| Интерфейс | Пропускная способность | Кол-во уcт-в | Горячая замена | Расстояние | Кол-во контактов |
| ISA | 1МБ/с | Нет | |||
| Последоват. порт COM | 11кБ/с | Нет | 10м | 9(25) | |
| Параллельный порт LPT | 0.6-2МБ/с | Нет | 4м | 25(36) | |
| Floppy | 35кБ/с | Нет | 1м | ||
| IDE | 33,66,100,133МБ/с | Нет | 0.5м | 40/80 | |
| SCSI | >300MБ/с | Нет | 6м | 50…80 | |
| DialUp 56к | <6кБ/с | Нет | >1км | 2 (RJ-11) | |
| PCI /PCI-X | 0.1-0.5 / 2 ГБ/с | Нет | |||
| IrDA | <500кБ/с | Да | 3 м | - | |
| BlueTooth | до 60кБ/с | Да | 10…100м | - | |
| LAN 10/100 | 1…10МБ/с | 1 (>1) | Да | 100м | 4 (RJ-45) |
| Serial ATA/eSATA(I,II,III) | 150,300,750MБ/с | Да | 1м | ||
| AGP 1x/2x/4x/8x | 0.26…2ГБ/с | Нет | |||
| USB 1.1/2.0 (3.0) | 0.5..60 (600) МБ/с | Да | 5м | ||
| FireWire (IEEE 1394a/b) | 50/100МБ/с | Да | 4.5м | ||
| 802.11(WiFi) | >5МБ/с | Да | 10…100м | - | |
| PCI Express 16x/1x | >4ГБ/с | Нет | 164/36 |
На практике FireWire быстрее USB на 20%. Хотя теоретическая пропускная способность данной шины на 20% медленнее, чем у USB. Две витые пары FireWire против одной у USB, автономная (аппаратная) работа и наличие выделенной шины адреса на практике приводит к такой ситуации.
17.2. Шины расширения РС
Шины расширения (expansion bus) ввода-вывода являются средствами подключения системного уровня: они позволяют адаптерам и контроллерам периферийных устройств непосредственно использовать системные ресурсы компьютера – пространство адресов памяти и ввода-вывода, прерывания, прямой доступ к памяти. Устройства, подключенные к шинам расширения, могут и сами управлять этими шинами, получая доступ к остальным ресурсам компьютера. Шины расширения механически реализуются в виде слотов (щелевых разъемов) или штырьковых разъемов; для них характерна малая длина проводников, то есть они сугубо локальны, что позволяет достигать высоких скоростей работы. Эти шины могут и не выводиться на разъемы, а использоваться для подключения устройств в интегрированных системных платах. В истории шин расширения ПК насчитывается уже 3 поколения.
К первому поколению относится ISA – асинхронная параллельная шина с низкой пропускной способностью (единицы мегабайт в секунду), не имеющая средств обеспечения надежности обмена и автоконфигурирования.
Второе поколение началось с шины EISA (а также МСА), за которой последовали шина PCI и ее расширение PCI-X. Это поколение параллельных синхронных надежных шин со средствами автоконфигурирования. Имеются варианты, снабженные возможностью «горячего» подключения-отключения. Скорость передачи достигает единиц гигабайт в секунду. Для подключения большого числа устройств применяется иерархическое объединение шин с помощью мостов в древовидную структуру.
Для третьего поколения (шина PCI Express, она же 3GIO, Hyper Transport, Advanced Switching) характерен переход от шин к двухточечным соединениям с последовательным интерфейсом; средством объединения множества абонентов являются «коммутационные фабрики». По сути, третье поколение расширения ввода-вывода приближается к сугубо локальным (в пределах системной платы) сетям.
В современных компьютерах основной шиной расширения пока является шина PCI и ее расширение PCI-X; ее дополняет порт AGP. Происходит переход на PCI Express – это средство подключения графического адаптера постепенно вытесняет AGP. Шина ISA из настольных компьютеров уходит, но она сохраняет свои позиции в промышленных и встраиваемых компьютерах как в традиционном слотовом варианте, так и в «бутербродном» варианте РС/104. В блокнотных компьютерах широко применяются слоты PCMCIA с шинами PC Card и Card Bus, появляется и Express Card. Сравнительные характеристики шин расширения PC-совместимых компьютеров представлены в табл. 17.2.
Таблица 17.2
| Шина | Пиковая пропускная способность, Мбайт/c | Разрядность данных | Разрядность адреса | Частота, МГц |
| ISA-8 | ||||
| ISA-16 | ||||
| LPC | 6,7 | 8/16/32 | ||
| EISA | 33,3 | 8/33 | ||
| MCA-16 | ||||
| MCA-32 | ||||
| PCMCIA | 10/20 | 8/16 | ||
| Card Bus | ||||
| VLB | 32/64 | 33-50 (66) | ||
| PCI | 133-533 | 32/64 | 32/64 | 33/66 |
| PCI-X | 533-4256 | 16/32/64 | 32/64 | 66-133 |
| AGP 1x/2x/4x/8x | 266/533/1066/2132 | 32/64 | ||
| PCI-Express | 496-15872 | 1/2/4/8/12/16/32 | 32/64 | 2,5 ГГц |
17.3. Шина ISA
Шина ISA (архитектура индустриального стандарта) является первым стандартом IBM PC. Разъем состоит из двух рядов А1-А31, B1-B31 и продолжения C1-C18, D1-D18. Контакты имеют следующее название и обозначение:
SА0...SА19, LА17...LА23 – шина адреса. SА0 - младший разряд;
BALE – строб адреса;
SD7...SD0, SD15...SD8 – шина данных. SD0 - младший разряд;
+5V, -5V, +12V, -12V – напряжение питания для МС на системной плате и расширениях (до 100мА);
GND – общий провод;
RESET – сброс ЦП и других устройств компьютера в исходное состояние;
CLK – синхросигнал МП. В XT он равнялся OSC/3 = 4,77МГц, а в AT составлял 6..20 и более МГц;
IRQ2...IRQ7, IRQ9...IRQ12, IRQ14, IRQ15 – линии запроса прерываний от адаптеров ввода-вывода;
DRQ0...DRQ3 и DRQ5...DRQ7 – линии запроса на обслуживание каналами ПДП;
MASTER# – этот сигнал используется совместно с DRQ-сигналом с целью получения контроля над системой для процессоров или контроллеров, расположенных на платах расширения;
DАCK0...DАCK3, DАCK5...DАCK7 – линии подтверждения захвата системной шины соответствующим каналом ПДП;
AEN – разрешение адреса ПДП;
T/C – конец передачи данных ("окончание счета"). Прекращения обмена по активному в данный момент каналу ПДП;
SMEMW#, MEMW#, SMEMR#, MEMR# – запись-чтение в память;
SMEMW# и SMEMR# формируются только в случае записи данных в первый Мбайт памяти;
IOW#, IOR# – запись-чтение порта ввода-вывода;
I/O CHCK# – ошибка канала ввода-вывода;
I/O CHRDY# – готовность канала ввода-вывода. 0 – "не готов";
MEM CS16# – сигнал формируется периферийными адаптерами как признак передачи двухбайтовых слов;
I/O CS16# – указание системе о переносе данных в виде двухбайтовых слов между процессором и периферийным портом;
SBHE – разрешение передачи старшего байта данных;
0WS – в AT используется как сигнал "нулевого состояния ожидания".
В настоящее время шина ISA для подключения к ПК стандартных плат расширения либо пользовательских устройств практически не применяется и вытеснена шиной PCI.
17.4. Шины PCI и PCI-X
PCI и PCI-X – синхронные параллельные шины расширения ввода-вывода, обеспечивающие надежный высокопроизводительный обмен и автоматическое конфигурирование устройств (Plug & Play). Шины PCI и PCI-X являются ближайшими «родственниками» с полной взаимной совместимостью устройств. Большинство положений, относящихся к PCI, относится и к PCI-X, так что в дальнейшем описании термин «РСI» в основном относится к обоим вариантам (различия подчеркиваются особо).
Шина PCI позволяет объединять одноранговые устройства. Любое устройство шины может выступать как в роли инициатора транзакций, так и в роли целевого устройства. Целевое устройство отвечает на транзакции, адресованные к его ресурсам (областям памяти и портам ввода-вывода). Ядро компьютера (центральный процессор и память) для шины PCI также представляется устройством – главным мостом (host bridge). В транзакциях к устройствам PCI, инициированных центральным процессором, главный мост является инициатором транзакций. В транзакциях от устройств PCI, обращающихся к ядру (к системной памяти), главный мост является целевым устройством. Право на управление шиной в любой момент времени дается лишь одному устройству данной шины; арбитраж запросов на управление шиной осуществляется централизованным способом. Арбитр, как правило, является частью моста.
Наличие активных устройств (помимо ЦП) позволяет в компьютере выполнять параллельно несколько операций обмена: одновременно с обращениями процессора могут выполняться транзакции от мастеров шины PCI. Эта параллельность – PCI Concurrency – возможна лишь для обменов по непересекающимся путям. Одновременный доступ нескольких инициаторов к одному ресурсу (как правило, к системной памяти) требует довольно сложной организации контроллера этого ресурса, но ради повышения суммарной эффективности работы на эти усложнения приходится идти. В системе с несколькими шинами PCI возможно параллельное функционирование устройств-мастеров на разных шинах – PCI Peer Concurrency. Однако если они обращаются к одному ресурсу (системной памяти), то какие-то фазы этих обменов все-таки приходится выполнять последовательно.
Важной частью шины PCI является система автоматического конфигурирования: конфигурирование выполняется каждый раз при включении питания и инициализации системы. Специальное конфигурационное ПО позволяет обнаружить и идентифицировать все установленные устройства, а также выяснить их потребности в ресурсах (областях памяти, адресах ввода-вывода, прерываниях). Спецификация PCI требует от устройств способности перемещать все занимаемые ресурсы (области в пространстве памяти и ввода-вывода) в пределах доступного адресного пространства. Это позволяет обеспечить бесконфликтное распределение ресурсов для множества устройств. Одно и то же функциональное устройство может быть сконфигурировано по-разному, отображая свои операционные регистры либо на пространство памяти, либо на пространство адресов ввода-вывода. Драйвер может определить текущую настройку, прочитав содержимое регистра базового адреса устройства. Драйвер также может определить номер запроса на прерывание, который используется устройством. Для конфигурирования устройств существует специальный набор функций PCI BIOS.
При частоте шины 33МГц и разрядности 32 бит теоретическая максимальная скорость достигает 132 Мбайт/с. Слоты PCI с шагом 0,05 дюйма имеют два ряда по 62 контакта в 32-битном варианте и 2х94 – в 64-битном.
Контакты имеют следующее назначение:
AD[31:0] – Address/Data – мультиплексированная шина адреса/данных. В начале транзакции передается адрес, в последующих тактах – данные;
CLK–Clock – сигнал тактовой частоты шины. Должна лежать в пределах 20-33 МГц; начиная с PCI 2.1 – до 66 МГц, в PCI-X – до 100 и 133 МГц;
RST#–Reset – сброс всех регистров в начальное состояние (по нажатию кнопки Reset и при перезагрузке);
С/ВЕ[3:0]# – Command/Byte Enable – команда/разрешение обращения к байтам. Команда, определяющая тип очередного цикла шины, задается четырехбитным кодом в фазе адреса;
FRAME# – Кадр. Введением сигнала отмечается начало транзакции (фаза адреса), снятие сигнала указывает на то, что последующий цикл передачи данных является последним в транзакции;
DEVSEL#–Device Select – устройство выбрано (ответ целевого устройства (ЦУ) на адресованную к нему транзакцию);
PAR–Parity – общий бит четности для линий AD[31:0] и С/ВЕ[3:0]#;
PERR#–ParityError – сигнал об ошибке четности (для всех циклов, кроме специальных). Вырабатывается любым устройством, обнаружившим ошибку;
SERR –System Error – системная ошибка (ошибка четности адреса или данных в специальном цикле или иная катастрофическая ошибка). Аактивизируется любым устройством PCI и вызывает NMI;
IRDY# –Initiator Ready – готовность ведущего устройства к обмену данными;
TRDY#–Target Ready – готовность целевого устройства к обмену данными;
STOP#–запрос целевого устр-ва к ведущему на останов текущей транзакции;
LOCK#– сигнал блокировки (захвата) шины для обеспечения целостного выполнения операции. Используется мостом, которому для выполнения одной операции требуется провести несколько транзакций PCI;
REQ[3:0]#–Request – запрос от ведущего устройства на захват шины (для слотов устройств 3:0);
GNT[3:0]#– Grant – предоставление управления шиной ведущему устройству;
IDSEL–Initialization Device Select — выбор устройства в циклах конфигурационного считывания и записи;
REQ64#–Request 64 bit – запрос на 64-битный обмен;
АСК64#–Подтверждение 64-битного обмена;
INTRA#, INTRB#, INTRC#, INTRD#–Interrupt А, В, С, D – линии запросов прерывания, чувствительность к уровню, активный уровень – низкий, что допускает совместное использование линий;
M66EN–66MHz_Enable – разрешение частоты синхронизации до 66 МГц;
SDONE–Snoop Done – сигнал завершенности цикла слежения для текущей транзакцией;
TCK–Test Clock – синхронизация тестового интерфейса JTAG;
TDI–Test Data Input – входные данные тестового интерфейса JTAG;
TDO–Test Data Output – выходные данные тестового интерфейса JTAG;
TMS–Test Mode Select – выбор режима для тестового интерфейса JTAG;
TRST–Test Logic Reset – сброс тестовой логики.
В каждый момент времени шиной может управлять только одно ведущее устройство, получившее на это право от арбитра. Каждое ведущее устройство имеет пару сигналов – REQ# для запроса на управление шиной и GNT# для подтверждения предоставления управления шиной. Устройство может начинать транзакцию (устанавливать сигнал FRAME#) только при полученном активном сигнале GNT# и дождавшись отсутствия активности шины. Заметим, что за время ожидания покоя арбитр может «передумать» и отдать управление шиной другому устройству с более высоким приоритетом. Снятие сигнала GNT# не позволяет устройству начать следующую транзакцию и даже может заставить прекратить начатую транзакцию.
На шине PCI все транзакции трактуются как пакетные: каждая транзакция начинается фазой адреса, за которой может следовать одна или несколько фаз данных (рис.17.2). Количество фаз данных в пакете явно не указывается. Если устройство не поддерживает пакетные транзакции в ведомом режиме, то оно должно потребовать прекращения пакетной транзакции в течение первой фазы данных. В ответ на это ведущее устройство завершает данную транзакцию и продолжает обмен последующей транзакцией со следующим значением адреса. После завершающей фазы данных ведущее устройство снимает сигнал IRDY#, и шина переходит в состояние покоя (idle).

Рис. 17.2. Цикл обмена на шине PCI
Шина является синхронной – фиксация всех сигналов выполняется по положительному перепаду (фронту) сигнала CLK.
На одной шине PCI может быть не более четырех устройств (слотов). Для подключения шины PCI к другим шинам применяются специальные аппаратные средства – мосты шины PCI (PCI Bridge). Главный мост (Host Bridge) используется для подключения PCI к системной шине (шине процессора или процессоров).
Особенности PCI-X
Протокол шины PCI-X во многом совпадает с PCI, изменения протокола нацелены на повышение эффективности использования тактов шины. В обычной шине PCI все транзакции начинаются одинаково (с фазы адреса) как пакетные с заранее неизвестной длиной. При этом реально транзакции ввода-вывода всегда имеют лишь одну фазу данных; длинные пакеты эффективны только для обращений к памяти (и применяются они именно для этого). В PCI-X транзакции по длине разделены на два типа:
· пакетные (burst) транзакции – все команды, обращенные к памяти (кроме команд чтения двойного слова);
· одиночные транзакции размером в двойное слово – остальные команды.
17.5. Графический интерфейс AGP
Порт AGP (Accelerated Graphic Port – ускоренный графический порт) был введен для подключения графических адаптеров с 3D-акселераторами. Такой адаптер содержит: акселератор – специализированный графический процессор; локальную память, используемую и как видеопамять, и как локальное ОЗУ графического процессора; управляющие и конфигурационные регистры, доступные как локальному, так и центральному процессорам. Акселератор может обращаться и к локальной памяти, и к системному ОЗУ, в котором для него могут храниться наборы данных, не умещающиеся в локальной памяти (как правило, текстуры большого объема). Основная идея порта AGP заключается в предоставлении акселератору максимально быстрого доступа к системной памяти (локальная ему и так близка), более приоритетного, чем доступ к ОЗУ со стороны других устройств.
Порт AGP представляет собой 32-разрядный параллельный синхронный интерфейс с тактовой частотой 66 МГц; большая часть сигналов позаимствована с шины PCI. Однако, в отличие от PCI, интерфейс порта AGP двухточечный, соединяющий графический акселератор с памятью и системной шиной процессора каналами данных чипсета системной платы, не пересекаясь с «узким местом» – шиной PCI. Обмен через порт может происходить как по протоколу PCI, так и по протоколу AGP.
Отличительные особенности порта AGP (обеспечивают «ускоренность»):
· конвейеризация обращений к памяти;
· умноженная относительно тактовой частоты порта частота передачи данных (2х/4х/8х);
· «внеполосная» подача команд (SBA), обеспеченная демультиплексированием шин адреса и данных.
Конвейеризация обращений к памяти порта AGP показана на рис.17.3, где сравниваются обращения к памяти по шине PCI и через порт AGP. В PCI во время реакции памяти на запрос шина простаивает (но не свободна). Конвейерный доступ AGP позволяет в это время передавать следующие запросы, а потом получать поток ответов.
Спецификация AGP предусматривает возможность постановки в очередь до 256 запросов, но при конфигурировании Plug &Play уточняются реальные возможности конкретной системы. AGP поддерживает две пары очередей для операций записи и чтения памяти с высоким и низким приоритетом.
Умножение частоты передачи данных обеспечивает при частоте 66 МГц пиковую пропускную способность до 533 Мбайт/с в режиме 2х, до 1066 Мбайт/с при 4х и до 2132 Мбайт/с при 8х. Выше 66 МГц тактовую частоту официально не поднимают.

Рис. 17.3. Цикл обращения к памяти PCI и AGP
Демультиплексирование (разделение) шины адреса и данных реализовано несколько необычно. С целью экономии числа интерфейсных линий шину адреса и команды в демультиплексированном режиме AGP представляют всего 8 линий SBA (SideBand Address), по которым команда, адрес и значение длины передачи передаются последовательно за несколько тактов. Поддержка демультиплексированной адресации не являлась обязательной для устройства AGP 1.0, поскольку имеется альтернативный способ передачи адреса по шине AD. В версии AGP 2.0 она стала обязательной, а в 3.0 – это уже единственный способ передачи адреса.
Порт AGP содержит практически полный набор сигналов шины PCI и дополнительные сигналы AGP. Устройство, подключаемое к порту AGP, может предназначаться как исключительно для операций AGP, так и для комбинированных операций AGP и PCI. Акселератор адаптера является мастером (ведущим устройством) порта AGP, свои запросы он может выполнять как в режиме AGP, так и в режиме PCI. В режиме AGP обмены выполняются с поддержкой (или без поддержки) таких свойств, как внеполосная адресация (SBA) и скорости 2х/4х/8х. Для транзакций в режиме AGP ему доступно только системное ОЗУ (но не локальная память устройств PCI). Кроме того, адаптер является целевым устройством PCI, для которого, помимо обычных команд PCI, может поддерживаться (или не поддерживаться) быстрая запись (Fast write) со скоростью 2х/4х/8х стороны процессора. В качестве целевого устройства адаптер выступает при обращениях ЦП к его локальной памяти, регистрам ввода-вывода и конфигурационного пространства.
Порт AGP позволяет акселератору работать в двух режимах – DMA и DIME (Direct Memory Execute). В режиме DMA акселератор при вычислениях рассматривает локальную память как первичную, а когда ее недостаточно, подкачивает в нее данные из основной памяти. В режиме DIME, он же режим исполнения (executive mode), локальная и основная память для акселератора логически равнозначны и располагаются в едином адресном пространстве. В режиме DMA для трафика порта характерны длительные блочные передачи, в режиме DIME трафик порта насыщен короткими произвольными запросами.
Спецификации AGP разрабатывались фирмой Intel на базе шины PCI 2.1 с частотой 66 МГц; пока имеется три основные версии спецификаций:
· AGP 1.0 (1996г.) – определен порт с конвейерным обращением к памяти и двумя альтернативными способами подачи команд: внеполосной (по шине SBA) и внутриполосной (по сигналу РIРЕ#). Режимы передачи – 1х/2х, питание интерфейса – 3,3В.
· AGP 2.0 (1998г.) – добавлена возможность быстрой записи в режиме PCI (Fast Writes), а также режим 4х с питанием 1,5В.
· AGP 3.0 (2002г., проект назывался AGP8X) – добавлен режим 8х с питанием 0,8 В и динамическим инвертированием байтов, отменены скорости 1х и 2х; оставлен один способ подачи команд – внеполосный (SBA); исключены некоторые команды AGP; введены команды изохронного обмена; введена возможность выбора размера страниц, описанных в таблице GART; введена селективная поддержка когерентности при обращениях к разным страницам в пределах GART.
Порт AGP предназначен только для подключения интеллектуального графического адаптера (причем только одного), имеющего 3D-акселератор. Системная логика порта AGP отличается сложным контроллером памяти, который выполняет глубокую буферизацию и высокопроизводительное обслуживание запросов AGP (от адаптера) и других своих клиентов – центрального процессора (одного или нескольких) и шины PCI. Единственный вариант подключения нескольких адаптеров с AGP – организация на системной плате нескольких портов AGP, что вряд ли когда-нибудь будет применяться.
AGP может реализовать всю пропускную способность 64-битной системы памяти современного компьютера. При этом возможны конкурирующие обращения к памяти со стороны как процессора, так и мостов шин PCI. Фирма Intel впервые ввела поддержку AGP в чипсеты для процессоров Р6, конкуренты используют AGP и в системных платах для процессоров с интерфейсом Pentium (сокет Super 7). В настоящее время порт AGP имеется во многих системных платах для PC-совместимых компьютеров и других платформ (даже Macintosh). Однако в перспективе его заменит PCI Express.
17.6. Интерфейс PCI-Express
PCI Express – новая архитектура соединения компонентов, введенная под эгидой PCI SIG, известная и под названием 3GIO (3-Generation Input/Output – ввод-вывод 3-го поколения). Здесь шинное соединение устройств с параллельным интерфейсом заменено двухточечными последовательными соединениями через коммутаторы. В этой архитектуре сохраняются многие программные черты шины PCI, что обеспечивает плавный переход от PCI к PCI Express. В архитектуре появились новые возможности: управление качеством обслуживания (Quality of Service, QoS), потреблением и бюджетом связей. Протокол PCI Express характерен малыми накладными расходами и малыми задержками выполнения транзакций.
PCI Express позиционируется как универсальная архитектура ввода-вывода для компьютеров разных классов, телекоммуникационных устройств и встроенных систем. Высокая пропускная способность достигается при соизмеримой с PCI цене и даже ниже. Сфера применения – от соединений между микросхемами на плате до межплатных разъемных и кабельных соединений. Высокая пропускная способность на контакт соединения позволяет минимизировать число таких контактов. Малое число сигнальных линий позволяет применять малогабаритные конструктивы. Универсальность дает возможность использования единой программной модели для всех форм-факторов. Спецификация PCI Express Base specification Revision 1.0a опубликована в апреле 2003 года.
Пример топологии средств ввода-вывода, иллюстрирующий архитектуру PCI Express, приведен на рис.17.4. Центральным элементом архитектуры является корневой комплекс (root complex), соединяющий иерархию ввода-вывода с центром – процессором (одним или несколькими) и памятью. Корневой комплекс может иметь один и более портов PCI Express, каждый из этих портов определяет свой домен иерархии (hierarchy domain). Каждый домен состоит из одной конечной точки (endpoint) или субиерархии – нескольких конечных точек, связанных коммутаторами. Наличие непосредственных одноранговых коммуникаций между элементами разных доменов обязательным не является, но может иметь место в конкретных реализациях. Для обеспечения прозрачных одноранговых коммуникаций в корневом комплексе должны присутствовать коммутаторы. Возможность взаимодействия центрального процессора с любым устройством любого домена безусловна, как и возможность обращения любого устройства к памяти. Корневой комплекс должен генерировать запросы к конфигурационному пространству – его роль аналогична главному мосту PCI.
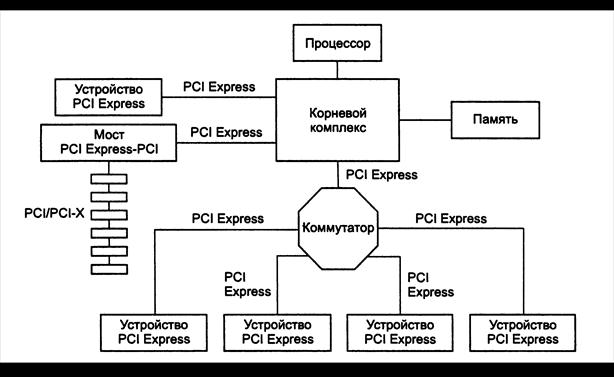
Рис. 17.4. Топология PCI- Express
Конечная точка – это устройство, способное инициировать или/и исполнять транзакции PCI Express от своего имени или от имени устройства, не являющегося устройством PCI Express (например, от имени хост-контролера USB). Конечная точка должна быть видима в одном из доменов иерархии – представлять в нем свои конфигурационные регистры и отвечать как исполнитель на конфигурационные запросы. В качестве механизма сигнализации прерываний все конечные точки используют MSI. В PCI Express рассматриваются два типа конечных точек: «наследники» (legacy) и новые точки, построенные по идеологии PCI Express. К «наследным» точкам имеется ряд послаблений в плане адресации памяти, перемещаемости ресурсов (из пространства ввода-вывода в пространство памяти) и некоторых нюансов.
Коммутатор (switch) имеет несколько портов PCI Express. Логически он представляет собой несколько виртуальных мостов PCI-PCI, соединяющих порты коммутатора со своей внутренней локальной шиной. Однако тех издержек, которые вносят «настоящие» мосты PCI, коммутатор не вносит. Коммутатор транслирует между портами пакеты всех типов, основываясь на адресной информации, актуальной для пакета данного типа. Арбитраж между портами коммутатора может учитывать виртуальные каналы и, соответственно, взвешенно распределять пропускную способность. Коммутатор не имеет права разбивать пакеты на более мелкие (у мостов PCI такое право имеется). Мост PCI-Express-PCI соединяет иерархию шин PCI/PCI-X с «фабрикой» ввода-вывода.
Конфигурирование «фабрики» осуществляется либо со 100-процентной совместимостью с конфигурационным механизмом PCI 2.3, либо с использованием расширенного конфигурационного пространства PCI-X. Каждое соединение PCI Express с помощью виртуальных мостов отображается в виде логической шины PCI со своим номером. Логически устройства отображаются в конфигурационном пространстве как устройства PCI, каждое из которых может иметь 1-8 функций со своим набором конфигурационных регистров.
Ключевые отличия новой шины от AGP и PCI:
· Шина PCI-Express – параллельная. Пропускная способность – более 4ГБ/с.
· Спецификация разделена на целый стек протоколов, каждый уровень которого может быть усовершенствован, упрощен или заменен, не сказываясь на остальных.
· В изначальной спецификации заложена возможность горячей замены карт.
· Заложены возможности контроля целостности передаваемых данных (CRC).
· Предусмотрены богатые возможности управления питанием.
· Пропускная способность одинакова в обе стороны, шина является полнодуплексной.
· Ниже задержки (латентность).
· Нет принципиальных ограничений на число таких графических разъемов в системе.
Контрольные вопросы
1. Как устроена шина ISA? Ее достоинства и недостатки.
2. Как устроена шина PCI и в чем ее ценность?
3. Почему интерфейс AGP называется портом? Каковы характеристики AGP?
4. Чем отличаются и что общего между PCI и AGP?
5. Построение и характеристики шины PCI-Express.
|
|
Дата добавления: 2014-12-07; Просмотров: 1348; Нарушение авторских прав?; Мы поможем в написании вашей работы!