КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Нахождение параметров линейной регрессии. Нахождение коэффициента корреляции
|
|
|
|
Нахождение коэффициента корреляции
Выбирается пункт меню Сервис – Анализ данных – Корреляция.
Задается входной интервал для X и Y – А1:В16 (группирование данных – по столбцам), устанавливается флажок в окошке «Метки» (это означает, что в первой строке – метки (имена данных) – x и y), «Выходной диапазон» - на новый лист или указывается выходной интервал на исходном листе.
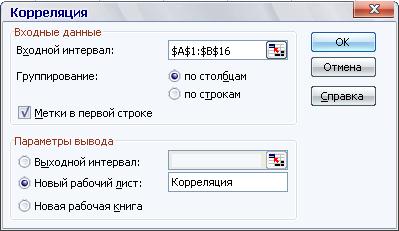
Полученная матрица симметрична относительно главной диагонали. Для однофакторной регрессии получаем матрицу следующего вида:
| x | y | |
| x | ||
| y | -0,86389 |
Коэффициент корреляции 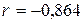 , что свидетельствует о наличии достаточной линейной зависимости между фактором x и откликом y. Знак «-» означает, что связь обратная – с ростом фактора x отклик y уменьшается.
, что свидетельствует о наличии достаточной линейной зависимости между фактором x и откликом y. Знак «-» означает, что связь обратная – с ростом фактора x отклик y уменьшается.
Чтобы найти параметры регрессии, выбираем пункт меню Сервис – Анализ данных – Регрессия. Здесь задаем диапазоны отдельно для Y, отдельно – для X (для многофакторной регрессии в поле «Входной интервал Х» выделяем все значения Х), устанавливаем флажок в окошке «Метки», «Остатки», «График подбора», «Выходной диапазон» – на новый лист, Ок.
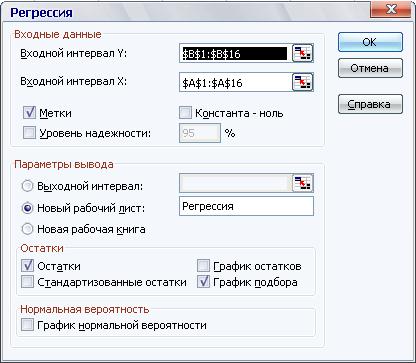
Результат получаем в виде нескольких таблиц (таблицы 1.15 – 1.18) и графика подбора (рисунок 1.4). В таблицах жирным шрифтом выделены величины, которые будут использоваться для дальнейших расчетов.
Таблица 1.15 – Регрессионная статистика
| Множественный R | 0,8639 |
| R-квадрат | 0,7463 |
| Нормированный R-квадрат | 0,7268 |
| Стандартная ошибка | 1,7980 |
| Наблюдения |
Здесь R-квадрат = 0,746 (74,6%) – значит, общее качество модели хорошее; стандартная ошибка 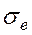 = 1,798.
= 1,798.
Таблица 1.16 – Дисперсионный анализ
| df | SS | MS | F | Значимость F | |
| Регрессия | 123,6341 | 123,6341 | 38,2423 | 0,000033 | |
| Остаток | 42,0279 | 3,2329 | |||
| Итого | 165,6620 |
|
|
|
Значимость F = 0,000033, что означает, что полученная модель адекватна по критерию Фишера исходным данным с уровнем доверия 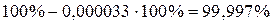 . Все дальнейшие расчеты выполняются только при условии адекватности модели.
. Все дальнейшие расчеты выполняются только при условии адекватности модели.
Таблица 1.17 – Коэффициенты модели
| Коэффициенты | Стандартная ошибка | t- статистика | P- Значение | Нижние 95% | Верхние 95% | |
| Y-пересечение | 48,2720 | 1,0157 | 47,5256 | 5,78202 E-16 | 46,077 | 50,4663 |
| x | -0,0012 | 0,0002 | -6,1840 | 3,30228 E-05 | -0,002 | -0,0008 |
Здесь коэффициенты линейной модели 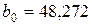 ,
, 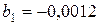 .
.
Оба коэффициента статистически значимы по критерию Стьюдента, т. к. для 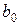 P-Значение =
P-Значение = 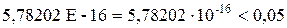 . и для
. и для 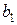 P-Значение =
P-Значение = 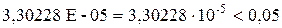 .
.
Полученная модель 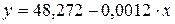 .
.
Таблица 1.18 – Вывод остатка
| Наблюдение | Предсказанное y | Остатки |
| 38,31 | 0,03 | |
| 44,88 | -0,19 | |
| 40,54 | -1,14 | |
| 38,37 | 0,56 | |
| 44,89 | 2,07 | |
| 41,96 | -2,48 | |
| 46,03 | 0,02 | |
| 45,28 | -1,78 | |
| 44,17 | 1,94 | |
| 45,54 | -2,75 | |
| 40,20 | -0,05 | |
| 39,33 | 1,11 | |
| 46,42 | 3,34 | |
| 44,51 | -1,52 | |
| 39,85 | 0,84 |
Здесь «Предсказанное y» – рассчитанные по модели значения отклика.

Рисунок 1.4 – График подбора
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 536; Нарушение авторских прав?; Мы поможем в написании вашей работы!