КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм Хафмана
|
|
|
|
В основе этого алгоритма лежит кодирование не байтами, а битовыми группами.
• Перед началом кодирования производится частотный анализ кода документа и выявляется частота повтора каждого из встречающихся символов.
• Чем чаще встречается тот или иной символ, тем меньшим количеством битов он кодируется (соответственно, чем реже встречается символ, тем длиннее его кодовая битовая последовательность).
• Образующаяся в результате кодирования иерархическая структура приклады вается к сжатому документу в качестве таблицы соответствия.
Пример кодирования символов русского алфавита представлен на рис. 14.1.
Как видно из схемы, представленной на рис. 14.1, используя 16 бит, можно закодировать до 256 различных символов. Однако ничто не мешает использовать и последовательности длиной до 20 бит — тогда можно закодировать до 1024 лексических единиц (это могут быть не символы, а группы символов, слоги и даже слова).
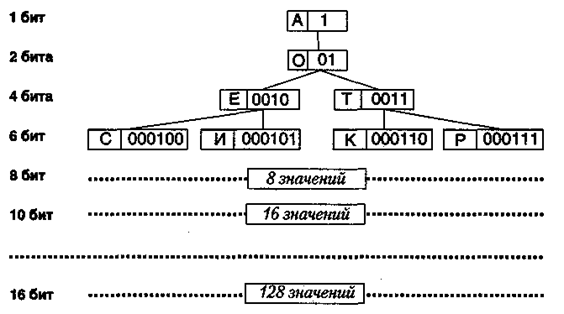
Рис. 14.1. Пример побуквенного кодирования русского алфавита
по алгоритму Хафмана
В связи с тем, что к сжатому архиву необходимо прикладывать таблицу соответствия, на файлах малых размеров алгоритм Хафмана малоэффективен. Практика также показывает, что его эффективность зависит и от заданной предельной длины кода (размера словаря). В среднем, наиболее эффективными оказываются архивы с размером словаря от 512 до!024 единиц (длина кода до 18-20 бит).
|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 348; Нарушение авторских прав?; Мы поможем в написании вашей работы!