КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Умножение матриц ленточным методом
Введение
Лабораторная работа №3
“Параллельные алгоритмы умножения матриц”
Цель работы – изучение производительности программ параллельной обработки матриц большой размерности с использованием коллективных коммуникаций библиотек MPI.
Последовательный алгоритм умножения матриц реализуется тремя вложенными циклами:
double MatrixA[Size][Size];
double MatrixB[Size][Size];
double MatrixC[Size][Size];
int i,j,k;
...
for (i=0; i<Size; i++){
for (j=0; j<Size; j++){
MatrixC[i][j] = 0;
for (k=0; k<Size; k++){
MatrixC[i][j] += MatrixA[i][k]*MatrixB[k][j];
}
}
}
Этот алгоритм является итеративным и ориентирован на последовательное вычисление строк матрицы С. Действительно, при выполнении одной итерации внешнего цикла (цикла по переменной i) вычисляется одна строка результирующей матрицы.
Из определения операции матричного умножения следует, что вычисление всех элементов матрицы С может быть выполнено независимо друг от друга. Как результат, возможный подход для организации параллельных вычислений состоит в использовании в качестве базовой подзадачи процедуры определения одного элемента результирующей матрицы С. Для проведения всех необходимых вычислений каждая подзадача должна содержать по одной строке матрицы А и одному столбцу матрицы В. Общее количество получаемых при таком подходе подзадач оказывается равным 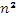 (по числу элементов матрицы С). Можно отметить, что достигнутый уровень параллелизма является в большинстве случаев избыточным. Обычно при проведении практических расчетов такое количество сформированных подзадач превышает число имеющихся процессоров и делает неизбежным этап укрупнения базовых задач. Поэтому определим базовую задачу как процедуру вычисления всех элементов одной из строк матрицы С. Такой подход приводит к снижению общего количества подзадач до величины n. Для выполнения всех необходимых вычислений базовой подзадаче должны быть доступны одна из строк матрицы A и все столбцы матрицы B. Простое решение этой проблемы – дублирование матрицы B во всех подзадачах не является оптимальным с точки зрения затрат памяти на хранение данных. Поэтому организация вычислений должна быть построена таким образом, чтобы в каждый текущий момент времени подзадачи содержали лишь часть данных, необходимых для проведения расчетов, а доступ к остальной части данных обеспечивался бы при помощи передачи данных между процессорами.
(по числу элементов матрицы С). Можно отметить, что достигнутый уровень параллелизма является в большинстве случаев избыточным. Обычно при проведении практических расчетов такое количество сформированных подзадач превышает число имеющихся процессоров и делает неизбежным этап укрупнения базовых задач. Поэтому определим базовую задачу как процедуру вычисления всех элементов одной из строк матрицы С. Такой подход приводит к снижению общего количества подзадач до величины n. Для выполнения всех необходимых вычислений базовой подзадаче должны быть доступны одна из строк матрицы A и все столбцы матрицы B. Простое решение этой проблемы – дублирование матрицы B во всех подзадачах не является оптимальным с точки зрения затрат памяти на хранение данных. Поэтому организация вычислений должна быть построена таким образом, чтобы в каждый текущий момент времени подзадачи содержали лишь часть данных, необходимых для проведения расчетов, а доступ к остальной части данных обеспечивался бы при помощи передачи данных между процессорами.
Алгоритм представляет собой итерационную процедуру, количество итераций которой совпадает с числом подзадач. На каждой итерации алгоритма каждая подзадача содержит по одной строке матрицы А и одному столбцу матрицы В. При выполнении итерации проводится скалярное умножение содержащихся в подзадачах строк и столбцов, что приводит к получению соответствующих элементов результирующей матрицы С. По завершении вычислений в конце каждой итерации столбцы матрицы В должны быть переданы между подзадачами с тем, чтобы в каждой подзадаче оказались новые столбцы матрицы В и могли быть вычислены новые элементы матрицы C. При этом данная передача столбцов между подзадачами должна быть организована таким образом, чтобы после завершения итераций алгоритма в каждой подзадаче последовательно оказались все столбцы матрицы В. Возможная простая схема организации необходимой последовательности передач столбцов матрицы В между подзадачами состоит в представлении топологии информационных связей подзадач в виде кольцевой структуры. В этом случае на каждой итерации подзадача i, 0i<n, будет передавать свой столбец матрицы В подзадаче с номером i+1 (в соответствии с кольцевой структурой подзадача n-1 передает свои данные подзадаче с номером 0).
Когда размер матриц n оказывается больше, чем число процессоров p, базовые подзадачи можно укрупнить, объединив в рамках одной подзадачи несколько соседних строк и столбцов перемножаемых матриц. Размер полос при этом следует выбрать равным k=n/p (мы считаем, что n кратно p).
|
|
Дата добавления: 2014-12-26; Просмотров: 1437; Нарушение авторских прав?; Мы поможем в написании вашей работы!