КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Сведения о сортировке
|
|
|
|
ИЛИ
И
ЕСЛИ
Синтаксис:
ЕСЛИ(логическое_выражение; значение_если_истина; значение_если_ложь).
- Предназначение: Функция ЕСЛИ выполняет то ("Значение если ИСТИНА") или иное ("Значение если ЛОЖЬ") действие в зависимости от того, выполняется (равно ИСТИНА) условие или нет (равно ЛОЖЬ).
- аргумент1. Логическое выражение: Все, что дает в результате логические значения ЛОЖЬ или ИСТИНА. Обычно либо выражения отношения (A1>=12) либо функции, возвращающие логические значения (И, ИЛИ).
- аргумент2. Значение если ИСТИНА: любое допустимое в Excel выражение.
- аргумент3. Значение если ЛОЖЬ: любое допустимое в Excel выражение.
- возвращаемое значение: может возвращать значения любых типов, в зависимости от аргументов 2 и 3.
Функция ЕСЛИ позволяет организовать в формуле ветвление. Вспомните сказки: налево пойдешь — коня потеряешь, прямо пойдешь — в болото попадешь, направо пойдешь — засосёт в чёрную дыру. Использование функций ЕСЛИ, И, ИЛИ граничит с программированием. Неудивительно, что для многих людей разобраться, как они работают, очень сложно. В голове должен быть чёткий алгоритм решения задачи и требуется хорошее понимание понятия "тип данных"
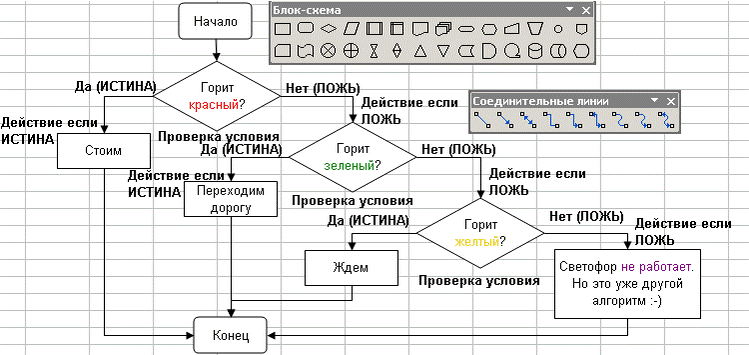
Алгоритм перехода через дорогу на светофор
Синтаксис:
Логич_знач И(логич_знач1; логич_знач2;...; логич_знач30)
- Предназначение: Функция И используется тогда, когда нужно проверить, выполняются ли несколько условий ОДНОВРЕМЕННО. Одно из наиболее часто используемых применений функции И — проверка, попадает ли число x в диапазон от x1 до x2.
- аргументы: Функция И принимает от 1 до 30 аргументов (в Office 2007 — до 256), каждый из которых является логическим значением ЛОЖЬ или ИСТИНА, либо любым выражением или функцией, которое в результате дает ЛОЖЬ или ИСТИНА.
- возвращаемое значение: Функция И возвращает логическое значение. Если ВСЕ аргументы функции И равны ИСТИНА, возвращает ИСТИНА. Если хотя бы один аргумент имеет значение ЛОЖЬ, возвращает ЛОЖЬ. Примечание: Функция И почти никогда не используется сама по себе, обычно её используют в качестве аргумента других функций, например, ЕСЛИ.
Синтаксис:
Логич_знач ИЛИ(логич_знач1; логич_знач2;...; логич_знач30)
- Предназначение: Функция ИЛИ используется тогда, когда нужно проверить, выполняется ли ХОТЯ-БЫ ОДНО из многих условий.
- аргументы: Функция ИЛИ принимает от 1 до 30 аргументов (в Office 2007 — до 256), каждый из которых является логическим значением ЛОЖЬ или ИСТИНА, либо любым выражением или функцией, которое в результате дает ЛОЖЬ или ИСТИНА.
- возвращаемое значение: Функция ИЛИ возвращает логическое значение. Если ХОТЯ БЫ ОДИН аргумент имеет значение ИСТИНА, возвращает ИСТИНА. Если ВСЕ аргументы имеют значение ЛОЖЬ, возвращает ЛОЖЬ.
Примечание: Функция ИЛИ почти никогда не используется сама по себе, обычно её используют в качестве аргумента других функций, например, ЕСЛИ.
77. Способы анализа данных в электронных таблицах.
В состав Microsoft Excel входит набор средств анализа данных (так называемый пакет анализа), предназначенный для решения сложных статистических и инженерных задач. Для анализа данных с помощью этих инструментов следует указать входные данные и выбрать параметры; анализ будет выполнен с помощью подходящей статистической или инженерной макрофункции, а результат будет помещен в выходной диапазон. Другие средства позволяют представить результаты анализа в графическом виде.
Другие функции. В Microsoft Excel представлено большое число статистических, финансовых и инженерных функций. Некоторые из них являются встроенными, другие доступны только после установки пакета анализа.
Обращение к средствам анализа данных. Средства, которые включены в пакет анализа данных, описаны ниже. Они доступны через команду Анализ данных меню Сервис. Если этой команды нет в меню, необходимо загрузить надстройку Пакет анализа.
 Дисперсионный анализ
Дисперсионный анализ
Существует несколько видов дисперсионного анализа. Требуемый вариант выбирается с учетом числа факторов и имеющихся выборок из генеральной совокупности.
Однофакторный дисперсионный анализ. Это средство служит для анализа дисперсии по данным двух или нескольких выборок. При анализе сравнивается гипотеза о том, что каждый пример извлечен из одного и того же базового распределения вероятности с альтернативной гипотезой, предполагающей, что базовые распределения вероятности во всех выборках разные. Если имеется всего две выборки, применяют функцию ТТЕСТ. Для более двух выборок не существует обобщения функции ТТЕСТ, и вместо этого можно воспользоваться моделью однофакторного дисперсионного анализа.
Двухфакторный дисперсионный анализ с повторениями. Этот вид анализа применяется, если данные можно систематизировать по двум параметрам. Например, в опыте по измерению роста растения обрабатывали удобрениями различных производителей (например, А, В, С) и содержали при различной температуре (например, низкой и высокой). Таким образом, для каждой из 6 возможных пар условий {удобрение, температура} имеется набор наблюдений за ростом растений. С помощью этого дисперсионного анализа можно проверить следующие гипотезы.
1. Извлечены ли данные о росте растений для различных марок удобрений из одной генеральной совокупности независимо от температуры.
2. Извлечены ли данные о росте растений для различных уровней температуры из одной генеральной совокупности независимо от марки удобрения.
3. Извлечены ли 6 выборок, представляющих все пары значений {удобрение, температура}, используемые для оценки влияния различных марок удобрений (шаг 1) и уровней температуры (шаг 2), из одной генеральной совокупности. Альтернативная гипотеза предполагает, что влияние конкретных пар {удобрение, температура} превышает влияние отдельно удобрения и отдельно температуры.
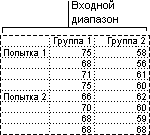
Двухфакторный дисперсионный анализ без повторения. Этот вид анализа полезен при классификации данных по двум измерениям, как и двухфакторный дисперсионный анализ с повторением. Однако при этом анализе предполагается только одно наблюдение для каждой пары (например, для каждой пары {удобрение, температура}) в примере выше. При этом анализе можно добавлять проверки в шаги 1 и 2 двухфакторного дисперсионного анализа с повторениями, но недостаточно данных для добавления проверок в шаг 3.
Корреляционный анализ
Функции КОРРЕЛ и ПИРСОН вычисляют коэффициент корреляции между двумя переменными измерений, когда для каждой переменной измерение наблюдается для каждого субъекта N (пропуск наблюдения для субъекта приводит к игнорированию субъекта в анализе). Корреляционный анализ иногда применяется, если имеется более двух переменных измерений для каждого субъекта N. В результате выдается таблица, корреляционная матрица, показывающая значение функции КОРРЕЛ (или ПИРСОН) для каждой возможной пары переменных измерений.
Коэффициент корреляции, как ковариационный анализ, характеризует область, в которой два измерения "изменяются вместе". В отличие от ковариационного анализа коэффициент масштабируется таким образом, что его значение не зависит от единиц, в которых выражены переменные двух измерений (например, если вес и высота являются двумя измерениями, значение коэффициента корреляции не изменится после перевода веса из фунтов в килограммы). Любое значение коэффициента корреляции должно находится в диапазоне от -1 до +1 включительно.
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
Ковариационный анализ
Корреляционный и ковариационный анализ можно использовать для одинаковых значений, если в выборке наблюдается N различных переменных измерений. Оба вида анализа возвращают таблицу (матрицу), показывающую коэффициент корреляции или ковариационный анализ, соответственно, для каждой пары переменных измерений. В отличие от коэффициента корреляции, масштабируемого в диапазоне от -1 до +1 включительно, соответствующие значения ковариационного анализа не масштабируются. Оба вида анализа характеризуют область, в которой две переменные "изменяются вместе".
Ковариационный анализ вычисляет значение функции КОВАР для каждой пары переменных измерений (напрямую использовать функцию КОВАР вместо ковариационного анализа имеет смысл при наличии только двух переменных измерений, то есть при N=2). Элемент по диагонали таблицы, возвращаемой после проведения ковариационного анализа в строке i, столбец i, является ковариационным анализом i-ой переменной измерения с самой собой; это всего лишь дисперсия генеральной совокупности для данной переменной, вычисляемая функцией ДИСПР.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть, большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация), или, наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
Описательная статистика
Это средство анализа служит для создания одномерного статистического отчета, содержащего информацию о центральной тенденции и изменчивости входных данных.
Экспоненциальное сглаживание
Применяется для предсказания значения на основе прогноза для предыдущего периода, скорректированного с учетом погрешностей в этом прогнозе. При анализе используется константа сглаживания a, по величине которой определяется степень влияния на прогнозы погрешностей в предыдущем прогнозе.
Примечание. Для константы сглаживания наиболее подходящими являются значения от 0,2 до 0,3. Эти значения показывают, что ошибка текущего прогноза установлена на уровне от 20 до 30 процентов ошибки предыдущего прогноза. Более высокие значения константы ускоряют отклик, но могут привести к непредсказуемым выбросам. Низкие значения константы могут привести к большим промежуткам между предсказанными значениями.
Двухвыборочный F-тест для дисперсии
Двухвыборочный F-тест применяется для сравнения дисперсий двух генеральных совокупностей.
Например, можно использовать F-тест по выборкам результатов заплыва для каждой из двух команд. Это средство предоставляет результаты сравнения нулевой гипотезы о том, что эти две выборки взяты из распределения с равными дисперсиями, с гипотезой, предполагающей, что дисперсии различны в базовом распределении.
С помощью этого средства вычисляется значение f F-статистики (или F-коэффициент). Значение f, близкое к 1, показывает, что дисперсии генеральной совокупности равны. В таблице результатов, если f < 1, "P(F <= f) одностороннее” дает возможность наблюдения значения F-статистики меньшего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение меньше 1 для выбранного уровня значимости Alpha. Если f > 1, “P(F <= f) одностороннее” дает возможность наблюдения значения F-статистики большего f при равных дисперсиях генеральной совокупности и F критическом одностороннем выдает критическое значение большее 1 для Alpha.
Анализ Фурье
Предназначается для решения задач в линейных системах и анализа периодических данных на основе метода быстрого преобразования Фурье (БПФ). Эта процедура поддерживает также обратные преобразования, при этом инвертирование преобразованных данных возвращает исходные данные.

Гистограмма
Используется для вычисления выборочных и интегральных частот попадания данных в указанные интервалы значений. При этом рассчитываются числа попаданий для заданного диапазона ячеек.
Например, необходимо выявить тип распределения успеваемости в группе из 20 студентов. Таблица гистограммы состоит из границ шкалы оценок и количеств студентов, уровень успеваемости которых находится между самой нижней границей и текущей границей. Наиболее часто повторяемый уровень является модой интервала данных.
Скользящее среднее
Скользящее среднее используется для расчета значений в прогнозируемом периоде на основе среднего значения переменной для указанного числа предшествующих периодов. Скользящее среднее, в отличие от простого среднего для всей выборки, содержит сведения о тенденциях изменения данных. Этот метод может использоваться для прогноза сбыта, запасов и других процессов. Расчет прогнозируемых значений выполняется по следующей формуле.

где:
- N — число предшествующих периодов, входящих в скользящее среднее;
- Aj — фактическое значение в момент времени j;
- Fj — прогнозируемое значение в момент времени j.
Генерация случайных чисел
Используется для заполнения диапазона случайными числами, извлеченными из одного или нескольких распределений. С помощью данной процедуры можно моделировать объекты, имеющие случайную природу, по известному распределению вероятностей.
Например, можно использовать нормальное распределение для моделирования совокупности данных по росту индивидуумов, или использовать распределение Бернулли для двух вероятных исходов, чтобы описать совокупность результатов бросания монеты.
Ранг и персентиль
Используется для вывода таблицы, содержащей порядковый и процентный ранги для каждого значения в наборе данных. Данная процедура может быть применена для анализа относительного взаиморасположения данных в наборе. Она использует функции РАНГ и ПРОЦЕНТРАНГ. РАНГ не работает со связанными значениями. Если требуется учитывать связанные значения, можно воспользоваться функцией РАНГ вместе с коэффициентом изменения, описанным в файле справки для функции РАНГ.
Регрессия
Линейный регрессионный анализ заключается в подборе графика для набора наблюдений с помощью метода наименьших квадратов. Регрессия используется для анализа воздействия на отдельную зависимую переменную значений одной или более независимых переменных.
Например, на спортивные качества атлета влияют несколько факторов, включая возраст, рост и вес. Регрессия пропорционально распределяет меру качества по этим трем факторам на основе его спортивных результатов. Результаты регрессии впоследствии могут быть использованы для предсказания качеств нового, непроверенного атлета.
Регрессия использует функцию ЛИНЕЙН.
Выборка
Создает выборку из генеральной совокупности, рассматривая входной диапазон как генеральную совокупность. Если совокупность слишком велика для обработки или построения диаграммы, можно использовать представительную выборку. Кроме того, если предполагается периодичность входных данных, то можно создать выборку, содержащую значения только из отдельной части цикла.
Например, если входной диапазон содержит данные для квартальных продаж, создание выборки с периодом 4 разместит в выходном диапазоне значения продаж из одного и того же квартала.
T-тест
Двухвыборочный t-тест проверяет равенство средних значений генеральной совокупности по каждой выборке. Эти три средства допускают следующие условия: равные дисперсии генерального распределения, дисперсии генеральной совокупности не равны, а также представление двух выборок до и после наблюдения по одному и тому же субъекту.
Для всех трех средств, перечисленных ниже, значение t-статистики t вычисляется и отображается как "t-статистика" в выводимой таблице. В зависимости от данных, это значение t может быть отрицательным или неотрицательным. Если предположить, что средние генеральной совокупности равны, при t < 0 “P(T <= t) одностороннее” дает вероятность того, что наблюдаемое значение t-статистики будет более отрицательным, чем t. При t >=0 “P(T <= t) одностороннее” делает возможным наблюдение значения t-статистики, которое будет более положительным чем t. “t критическое одностороннее” выдает пороговое значение, так что вероятность наблюдения значения t-статистики большего или равного “t критическое одностороннее” равно Alpha.
“P(T <= t) двустороннее” дает вероятность наблюдения значения t-статистики по абсолютному значению большего чем t. “P критическое двустороннее” выдает пороговое значение, так что значение вероятности наблюдения значения t- статистики по абсолютному значению большего “P критическое двустороннее” равно Alpha.
Двухвыборочный t-тест с одинаковыми дисперсиями. Двухвыборочный t-тест Стьюдента служит для проверки гипотезы о равенстве средних для двух выборок. Эта форма t-теста предполагает совпадение значений дисперсии генеральных совокупностей и обычно называется гомоскедастическим t-тестом.
Двухвыборочный t-тест с разными дисперсиями. Двухвыборочный t-тест Стьюдента используется для проверки гипотезы о равенстве средних для двух выборок данных из разных генеральных совокупностей. Эта форма t-теста предполагает несовпадение дисперсий генеральных совокупностей и обычно называется гетероскедастическим t-тестом. Если тестируется одна и та же генеральная совокупность, используйте парный тест.
Для определения тестовой величины t используется следующая формула.
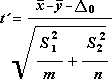
Следующая формула используется для вычисления степени свободы df. Так как результат вычисления обычно не бывает целым числом, значение df округляется до целого для получения порогового значения из t-таблицы. Функция Excel ТТЕСТ по возможности использует вычисленные значения без округления для вычисления значения ТТЕСТ с нецелым значением df. Из-за разницы подходов к определению степеней свободы, результаты функций ТТЕСТ и t-тест будут различаться в случае с разными дисперсиями.
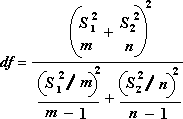
Парный двухвыборочный t-тест для средних. Парный двухвыборочный t-тест Стьюдента используется для проверки гипотезы о различии средних для двух выборок данных. В нем не предполагается равенство дисперсий генеральных совокупностей, из которых выбраны данные. Парный тест используется, когда имеется естественная парность наблюдений в выборках, например, когда генеральная совокупность тестируется дважды — до и после эксперимента.
Примечание. Одним из результатов теста является совокупная дисперсия (совокупная мера распределения данных вокруг среднего значения), вычисляемая по следующей формуле.
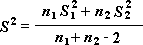
Z-тест
78. Графическое представление данных.
79. Анализ «что-если?».
| Анализ "что-если" MS Excel Неотъемлемой процедурой обработки статистической, финансово-экономической информации, результатов опытов является многократное повторение расчетов по одним и тем же формулам для серий изменяющихся значений. При обработке такой информации в среде электронных таблиц Excel обычно используется операция копирования формул с учетом относительной и абсолютной адресации ячеек рабочей книги. Современные информационные технологии нацелены на повышение эффективности обработки данных, и Excel имеет такие эффективные средства. Одним из них являются ТАБЛИЦЫ ПОДСТАНОВКИ (ДАННЫХ). Оценивая результаты экономических задач нередко приходится продумывать вопрос: как поведет себя полученный результат, если изменятся исходные данные, т.е. «А что произойдет, если…?». Разрешение этих вопросов – цель анализа чувствительности системы, проекта. Наиболее распространенный метод анализа чувствительности – имитационное моделирование. Таблицы подстановки служат хорошим инструментом для его проведения. При решении различных задач часто приходится заниматься проблемой подбора одного значения путем изменения другого. Для этой цели весьма эффективно средство Excel ПОДБОР ПАРАМЕТРА. Таблицы подстановки данных (ТД) Таблица подстановки (данных) представляет собой диапазон ячеек, в которых можно получить различные варианты вычислений по одной и той же формуле, но для различных входных данных. Они дают возможность быстрого получения вариантов результатов для одной или двух серий изменяющихся значений, влияющих на результат, а также позволяют на одном листе просмотреть и сравнить варианты этих результатов. Таким образом, применение таблиц данных избавляет нас от многократного копирования формул. Таблицы подстановки данных Excel могут содержать одну или две подстановочных переменных, т.е. могут быть векторнымиили матричнымисоответственно. С помощью таблиц данных с двумя переменными можно, например, оценить влияние цены и объема продаж на полученную прибыль. Инструмент ТАБЛИЦЫ ПОДСТАНОВКИ ДАННЫХ для MS Excel 2003 вызывается из меню ДАННЫЕ. Вызов ТАБЛИЦЫ ДАННЫХ для MS Excel 2007 производится на закладке ДАННЫЕ из меню Анализ "что-если" | |
|
80. Списки и их использование для анализа табличных данных.
Табличный процессор MS Excel дает в руки пользователя мощные средства анализа данных, если таблица, где они хранятся, организована особым образом, называемым списком. Список – способ хранения данных в таблице, совокупность поименованных строк, содержащих однородные данные (набор строк таблицы, содержащий связанные данные).
Существует ряд требований, которым должны отвечать списки:
- на листе рабочей книги может размещаться только один список;
- если на этом листе размещаются данные, не входящие в список, то их должны отделять от списка не менее одного пустого столбца и одной пустой строки;
- первая строка списка должна содержать заголовки столбцов;
- оформление заголовков столбцов должно отличаться от данных, для этого используется их выделение с помощью шрифта, выравнивания, форматов и рамок;
- во всех ячейках столбца размещаются однотипные данные, при этом используется один формат;
- перед содержимым ячейки не должно быть пробелов;
- для поиска записи, подлежащей удалению или изменению, следует нажать кнопку Критерии и ввести в соответствующие поля условия поиска. Затем с помощью кнопок Далее и Назад найти записи, соответствующие этим условиям. Для поиска необходимых данных можно, так же как и в текстовом процессоре MS Word, использовать команду Редактирование/ Найти (рис. 1).
81. Сортировка, фильтры, сводные таблицы.
Сортировка данных является встроенной частью анализа данных. Может потребоваться расположить в алфавитном порядке фамилии в списке, составить перечень объемов запасов продуктов от максимального до минимального, а также задать порядок строк в зависимости от цвета или значка. Сортировка данных помогает быстро придавать данным удобную форму и лучше понимать их, организовывать и находить необходимую информацию, и в итоге принимать более эффективные решения.
Примечание. Для поиска верхних и нижних значений в диапазоне ячеек или таблице, например, верхних 10 категорий или нижних 5 сумм продаж, используйте «Автофильтр» или условное форматирование. Дополнительные сведения см. в разделах Фильтрация данных в диапазоне или таблице и Добавление, изменение и удаление условных форматов.
Предполагаемое действие:
- Сведения о сортировке
- Сортировка текстовых значений
- Сортировка числа
- Сортировка значений даты и времени
- Сортировка по цвету ячеек, цвету шрифта или значку
- Сортировка по настраиваемым спискам
- Сортировка строк
- Сортировка по нескольким столбцам или строкам
- Сортировка одного столбца в диапазоне ячеек без влияния на другие столбцы
- Узнать подробнее об основных особенностях сортировки
Можно выполнять сортировку данных по тексту (от А к Я или от Я к А), числам (от наименьших к наибольшим или от наибольших к наименьшим), а также датам и времени (от старых к новым или от новых к старым) в нескольких столбцах. Можно также выполнять сортировку по настраиваемым спискам (таким как состоящий из элементов «Большой», «Средний» и «Маленький») или по формату, включая цвет ячеек, цвет шрифта, а также по значкам. Большинство сортировок применяются к столбцам, но возможно также применить сортировку к строкам.
Критерии сортировки сохраняются вместе с книгой, предоставляя возможность повторного применения сортировки каждый раз при открытии книги в таблице Excel, но не к диапазону ячеек. Если необходимо сохранить параметры сортировки для периодического повторного применения при открытии книги, рекомендуется использовать таблицу. Это особенно важно при сортировке по нескольким столбцам или сортировке, составление которой занимает много времени.
 К началу страницы
К началу страницы
|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 519; Нарушение авторских прав?; Мы поможем в написании вашей работы!