КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Принцип практической невозможности. Уровни значимости и достоверности
В традиционной математической статистике проверка тех или иных гипотез о случайных величинах и событиях основана на принципе так называемой практической невозможности. Заключается этот принцип в следующем. Задается некоторая, обычно весьма малая вероятность α (например, α=0,1; α=0,05; α=0,01 и т.д.), именуемая уровнем значимости. При этом случайные события, вероятность которых меньше или равна α, считаются практически невозможными. Иначе говоря, уровень значимости – это вероятность того, что мы сочли различия существенными, а они на самом деле случайны.
Для того, чтобы нагляднее представить роль уровня значимости в оценке неслучайности события, можно считать, что уровень значимости, выраженный в процентах (α·100%), показывает, сколько раз в среднем в 100 случаях мы рискуем ошибиться, объявив изучаемое событие неслучайным. Так, уровень значимости α=0,05, т.е. 5%-ый уровень значимости, допускает ошибку в среднем в 5 случаях из 100.
Рассмотрим величину θ = 1 – α. Очевидно, что θ·100% показывает, сколько раз в среднем в 100 случаях будет справедлив вывод о неслучайности события, поэтому величина θ называется уровнем достоверности.
При более высоком, чем 5%-ый, уровне значимости (например, 10%-м) большее число событий нельзя рассматривать как случайные. Однако достоверность такого вывода ниже (90% против 95%). Наоборот, более низкий уровень значимости (например, 1%-ый) приводит к более осторожным, но и более достоверным (уровень достоверности 99%) выводам.
Из этого следует вывод, выбор определенного уровня значимости, выше которого результаты отвергаются как ложные, является достаточно произвольным. На практике окончательное решение обычно зависит от того, был ли результат предсказан априори (т.е. до проведения опыта) или обнаружен апостериорно в результате многих анализов и сравнений, выполненных с множеством данных, а также на традиции, имеющейся в данной области исследований. Обычно во многих областях результат p 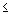 .05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p .01 обычно рассматриваются как статистически значимые, а результаты с уровнем p .005 или p . 001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
.05 является приемлемой границей статистической значимости, однако следует помнить, что этот уровень все еще включает довольно большую вероятность ошибки (5%). Результаты, значимые на уровне p .01 обычно рассматриваются как статистически значимые, а результаты с уровнем p .005 или p . 001 как высоко значимые. Однако следует понимать, что данная классификация уровней значимости достаточно произвольна и является всего лишь неформальным соглашением, принятым на основе практического опыта в той или иной области исследования.
Существует вполне определенная взаимосвязь между уровнем статистической значимости и количеством выполненных измерений. Понятно, что чем больше число замеров вы проведете с совокупностью собранных данных, тем большее число значимых (на выбранном уровне) результатов будет обнаружено чисто случайно. Например, если вы вычисляете корреляции между 10 переменными (имеете 45 различных коэффициентов корреляции), то можно ожидать, что примерно два коэффициента корреляции (один на каждые 20) чисто случайно окажутся значимыми на уровне p .05, даже если переменные совершенно случайны и некоррелированы в популяции. Некоторые статистические методы, включающие много сравнений, и, таким образом, имеющие хороший шанс повторить такого рода ошибки, производят специальную корректировку или поправку на общее число сравнений. Тем не менее, многие статистические методы (особенно простые методы разведочного анализа данных) не предлагают какого-либо способа решения данной проблемы. Поэтому исследователь должен с осторожностью оценивать надежность неожиданных результатов.
Помимо количества выполненных анализов на уровень значимости влияет и объем выборки. Если наблюдений мало, то соответственно имеется мало возможных комбинаций значений этих переменных и таким образом, вероятность случайного обнаружения комбинации значений, показывающих сильную зависимость, относительно велика. Рассмотрим следующий пример. Если вы исследуете зависимость двух переменных (Пол: мужчина/женщина и WCC: высокий/низкий) и имеете только 4 субъекта в выборке (2 мужчины и 2 женщины), то вероятность того, что чисто случайно вы найдете 100% зависимость между двумя переменными равна 1/8. Более точно, вероятность того, что оба мужчины имеют высокий WCC, а обе женщины - низкий WCC, или наоборот, - равна 1/8. Теперь рассмотрим вероятность подобного совпадения для 100 субъектов; легко видеть, что эта вероятность равна практически нулю. Пример: "отношение числа новорожденных мальчиков к числу новорожденных девочек" Рассмотрим пример, заимствованный из Nisbett, et al., 1987. Имеются 2 больницы. Предположим, что в первой из них ежедневно рождается 120 детей, во второй только 12. В среднем отношение числа мальчиков, рождающихся в каждой больнице, к числу девочек 50/50. Однажды девочек родилось вдвое больше, чем мальчиков. Спрашивается, для какой больницы данное событие более вероятно? Ответ очевиден для статистика, однако, он не столь очевиден неискушенному. Конечно, такое событие гораздо более вероятно для маленькой больницы. Объяснение этого факта состоит в том, что вероятность случайного отклонения (от среднего) возрастает с уменьшением объема выборки.
|
|
Дата добавления: 2014-12-26; Просмотров: 845; Нарушение авторских прав?; Мы поможем в написании вашей работы!