КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Ранговая корреляция
|
|
|
|
Свободные от распределения методы оценки корреляции предназначены для проверки гипотезы о некоррелируемости (независимости, отсутствии соответствия или ассоциативности) двух парных переменных, извлеченных из непрерывной двумерной совокупности.
В практике наиболее часто применяются такие ранговые меры связи, как коэффициенты ранговой корреляции Спирмена и коэффициент конкордации Кендалла.
Коэффициент ранговой корреляции r Спирмена (Spearman) является непараметрическим аналогом классического выборочного коэффициента корреляции. Рассчитывается по формуле:
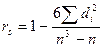 ,
,
где di – разности между рангами каждой переменной из пар значений X и Y; n – число сопоставляемых пар.
Коэффициент конкордации τ Кендела (Kendall), вычисляется как число всех пар значений одной выборки, для которых соответствующие пары значений другой выборки имеют одинаковую тенденцию (возрастание или уменьшение значений) минус число пар с противоположенной тенденцией (и с отсевом связанных, равных пар значений). Рассчет этого коэффициента производится по формуле:
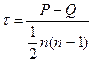 ,
,
где P – Q представляют собой разницу числа «совпадений» (Р) и числа «инверсий» (Q): совпадение, если порядок по X и Y одинаков; инверсия, если порядок различен.
§ 4.6. Таблицы частот
Таблицы частот или одновходовые таблицы представляют собой простейший метод анализа категориальных (номинальных) переменных. Часто их используют как одну из процедур разведочного анализа, чтобы просмотреть, каким образом различные группы данных распределены в выборке. Например, изучая зрительский интерес к разным видам спорта (с целью рекламы какого-либо продукта на ТВ), вы могли бы представить ответы респондентов следующей таблицей:
|
|
|
| ОСНОВНЫЕ СТАТИСТИКИ | ФУТБОЛ: "Просмотр футбола" | |||
| Категория | Частота | Кумулят. частота | Процент | Кумулят. процент |
| ВСЕГДА: Всегда интересуюсь ОБЫЧНО: Обычно интересуюсь ИНОГДА: Иногда интересуюсь НИКОГДА: Никогда интересуюсь Пропущено | 39 16 26 19 0 | 39 55 81 100 100 | 39.00000 16.00000 26.00000 19.00000 0.00000 | 39.0000 55.0000 81.0000 100.0000 100.0000 |
Таблица показывает частоты, кумулятивные (накопленные) частоты, процент, кумулятивный процент респондентов, выразивших свой интерес к просмотру футбольных матчей в следующей шкале: (1) Всегда интересуюсь, (2) Обычно интересуюсь, (3) Иногда интересуюсь или (4) Никогда не интересуюсь.
Практически каждый исследовательский проект начинается с построения таблиц частот. Например, в социологических опросах таблицы частот могут отображать число мужчин и женщин, выразивших симпатию тому или иному политическому деятелю, число респондентов из определенной этнических групп, голосовавших за того или иного кандидата и т.д. Ответы, измеренные в определенной шкале (например, в шкале: интерес к футболу) также можно прекрасно свести в таблицу частот. В медицинских исследованиях табулируют пациентов с определенными симптомами, в психологических - испытуемых с тем или иным типом профиля. В маркетинговых исследованиях - покупательский спрос на товары разного типа у разных категорий населения. Обычно, если в данных имеются группирующие переменные, то для них всегда вычисляются таблицы частот.
§ 4.7. Таблицы сопряженности
Данный метод предназначен для анализа двумерных таблиц сопряженности (кросстабуляции) двух номинальных переменных с проверкой гипотезы о независимости переменных.
Кросстабуляция - это процесс объединения двух (или нескольких) таблиц частот так, что каждая ячейка (клетка) в построенной таблице представляется единственной комбинацией значений или уровней табулированных переменных. Таким образом, кросстабуляция позволяет совместить частоты появления наблюдений на разных уровнях рассматриваемых факторов. Исследуя эти частоты, можно определить связи между табулированными переменными. Обычно табулируются категориальные (номинальные) переменные или переменные с относительно небольшим числом значений. Если вы хотите табулировать непрерывную переменную (например, доход), то вначале ее следует перекодировать, разбив диапазон изменения на небольшое число интервалов (например, доход: низкий, средний, высокий).
|
|
|
Простейшая форма кросстабуляции - это таблица сопряженности 2 x 2, в которой значения двух переменных "пересечены" (сопряжены) на разных уровнях и каждая переменная принимает только два значения, т.е. имеет два уровня (поэтому таблица называется "2 на 2"). К примеру, пусть проводится исследование, в котором мужчины и женщины опрашиваются о том, какой тип поведения в заданной ситуации они обычно предпочитают (A или B); файл данных может быть таким:
| ПОЛ | поведение | |
| наблюдение 1 наблюдение 2 наблюдение 3 наблюдение 4 наблюдение 5... | мужчина женщина женщина женщина мужчина... | A B B A B... |
Результаты кросстабуляции этих переменных выглядят следующим образом.
| поведение: A | поведение: B | ||
| ПОЛ: мужчина | 20 (40%) | 30 (60%) | 50 (50%) |
| ПОЛ: женщина | 30 (60%) | 20 (40%) | 50 (50%) |
| 50 (50%) | 50 (50%) | 100 (100%) |
Каждая ячейка таблицы содержит единственную комбинацию значений двух табулированных переменных (в строке - указана переменная Пол в столбце – тип поведения). Числа в каждой ячейке, на пересечении определенной строки и определенного столбца, показывают, сколько наблюдений соответствует данным уровням факторов. В целом таблица показывает, что женщины больше мужчин предпочитают тип реагирования A (например, подчинение), мужчины больше женщин предпочитают тип B (доминирование). Таким образом, пол и тип поведения могут быть зависимыми (и гипотезу можно проверить статистичсеки).
Значения, расположенные по краям таблицы сопряженности - это обычные таблицы частот (с одним входом) для рассматриваемых переменных. Так как эти частоты располагаются на краях таблицы, то они называются маргинальными. Маргинальные значения важны, т.к. позволяют оценить распределение частот в отдельных столбцах и строках таблицы. Например, 40% и 60% мужчин и женщин (соответственно), выбравших тип A (см. первый столбец таблицы), не могли бы показать какой-либо связи между переменными Пол и Поведение, если бы маргинальные частоты переменной Пол были также 40% и 60%. В этом случае они просто отражали бы разную долю мужчин и женщин, участвующих в опросе. Таким образом, различие в распределении частот в строках (или столбцах) отдельных переменных и в соответствующих маргинальных частотах дают информацию о связи переменных.
|
|
|
Пример показывает, что для оценки связи между табулированными переменными, необходимо сравнить маргинальные и индивидуальные частоты в таблице. Такие сравнения легче проводить, имея дело с относительными частотами или процентами.
В целях исследования отдельные строки и столбцы таблицы удобно представлять в виде графиков. Полезно также отобразить целую таблицу на отдельном графике. Таблицы с двумя входами можно изобразить на 3-мерной гистограмме. Другой способ визуализации таблиц сопряженности - построение категоризованной гистограммы, в которой каждая переменная представлена индивидуальными гистограммами на каждом уровне другой переменной. Преимущество 3М гистограммы в том, что она позволяет представить на одном графике таблицу целиком. Достоинство категоризованного графика в том, что он дает возможность точно оценить отдельные частоты в каждой ячейке.
Когда кросстабулируются только две переменные, результирующая таблица называется двувходовой. Конечно, общую идею кросстабулирования можно обобщить на большее число переменных. В примере добавим третью категориальную переменную – экстравертированный и интровертированный тип личности.
| ПОЛ | Поведение | Тип личности | |
| наблюдение 1 наблюдение 2 наблюдение 3 наблюдение 4 наблюдение 5... | мужчина женщина женщина женщина мужчина... | A B B A B... | эксраверт интроверт эксраверт экстраверт интроверт... |
Кросстабуляция этих 3-х переменных представлена в следующей таблице:
|
|
|
| интроверт | экстраверт | |||||
| A | B | A | B | |||
| Пол:мужчина | ||||||
| Пол:женщина | ||||||
Теоретически любое число переменных может быть кросстабулировано в одной многовходовой таблице. Однако на практике возникают сложности с проверкой и "пониманием" таких таблиц, даже если они содержат более четырех переменных. Рекомендуется анализировать зависимости между факторами в таких таблицах с помощью таких методов, как Логлинейный анализ или Анализ соответствий.
Статистики таблиц сопряженности
Обзор. Таблицы сопряженности позволяют измерить связи между кросстабулированными переменными. Следующая таблица отчетливо показывает сильную связь между двумя переменными: переменная Возраст (Взрослый или Ребенок) и переменная - предпочитаемое Печенье (сорт A или сорт B).
| ПЕЧЕНЬЕ: A | ПЕЧЕНЬЕ: B | ||
| ВОЗРАСТ: ВЗРОСЛЫЙ | |||
| ВОЗРАСТ: РЕБЕНОК | |||
Из таблицы видно, что все взрослые выбирают печенье A, а все дети печенье B. В данном случае, нет оснований сомневаться в надежности этого факта. Взглянув на таблицу, мало кто усомнится, что между предпочтениями детей и взрослых имеется отчетливое различие. Однако наблюдаемые на практике связи значительно слабее, и поэтому возникает вопрос: как измерить связи между табулированными переменными и оценить их надежность (статистическую значимость). Далее обсуждаются самые общие меры связи между двумя категоризованными переменными. Методы, используемые для анализа связей между более чем двумя переменными в таблицах высокого порядка, реализуются в логлинейном анализе и анализе соответствий.
Критерий хи-квадрат Пирсона. Э то наиболее простой критерий проверки значимости связи между двумя категоризованными переменными. Критерий Пирсона основывается на том, что в двухвходовой таблице ожидаемые частоты при гипотезе "между переменными нет зависимости" можно вычислить непосредственно. Представьте, что 20 мужчин и 20 женщин протестированы относительно типа поведения в заданной ситуации (A или B). Если между типом реагирования и полом нет связи, то естественно ожидать равного выбора стиля поведения (доминирование-подчинение) для каждого пола.
Значение статистики хи-квадрат и ее уровень значимости зависит от общего числа наблюдений и количества ячеек в таблице. Имеется только одно существенное ограничение использования критерия хи-квадрат (кроме очевидного предположения о случайном выборе наблюдений), которое состоит в том, что ожидаемые частоты не должны быть очень малы. Это связано с тем, что критерий хи-квадрат по своей природе проверяет вероятности в каждой ячейке; и если ожидаемые частоты в ячейках, становятся, маленькими, например, меньше 5, то эти вероятности нельзя оценить с достаточной точностью с помощью имеющихся частот.
Критерий хи-квадрат (метод максимального правдоподобия). Максимум правдоподобия хи-квадрат предназначен для проверки той же самой гипотезы относительно связей в таблицах сопряженности, что и критерий хи-квадрат Пирсона. Однако его вычисление основано на методе максимального правдоподобия. На практике статистика МП хи-квадрат очень близка по величине к обычной статистике Пирсона хи-квадрат.
Поправка Йетса. Аппроксимация статистики хи-квадрат для таблиц 2x2 с малыми числом наблюдений в ячейках может быть улучшена уменьшением абсолютного значения разностей между ожидаемыми и наблюдаемыми частотами на величину 0.5 перед возведением в квадрат (так называемая поправка Йетса). Поправка Йетса, делающая оценку более умеренной, обычно применяется в тех случаях, когда таблицы содержат только малые частоты, например, когда некоторые ожидаемые частоты становятся меньше 10.
Точный критерий Фишера. Этот критерий применим только для таблиц 2x2. Критерий основан на следующем рассуждении. Даны маргинальные частоты в таблице, предположим, что обе табулированные переменные независимы. Зададимся вопросом: какова вероятность получения наблюдаемых в таблице частот, исходя из заданных маргинальных? Оказывается, эта вероятность вычисляется точно подсчетом всех таблиц, которые можно построить, исходя из маргинальных. Таким образом, критерий Фишера вычисляет точную вероятность появления наблюдаемых частот при нулевой гипотезе (отсутствие связи между табулированными переменными).
Хи-квадрат Макнемара. Этот критерий применяется, когда частоты в таблице 2x2 представляют зависимые выборки. Например, наблюдения одних и тех же индивидуумов до и после эксперимента. В частности, вы можете подсчитывать число студентов, имеющих минимальные успехи по математике в начале и в конце семестра или предпочтение одних и тех же респондентов до и после рекламы. Вычисляются два значения хи-квадрат: A/D и B/C. A/D хи-квадрат проверяет гипотезу о том, что частоты в ячейках A и D (верхняя левая, нижняя правая) одинаковы. B/C хи-квадрат проверяет гипотезу о равенстве частот в ячейках B и C (верхняя правая, нижняя левая).
Коэффициент Фи. Фи-квадрат представляет собой меру связи между двумя переменными в таблице 2x2. Его значения изменяются от 0 (нет зависимости между переменными; хи-квадрат = 0.0) до 1 (абсолютная зависимость между двумя факторами в таблице).
Тетрахорическая корреляция. Эта статистика вычисляется (и применяется) только для таблиц сопряженности 2x2. Если таблица 2x2 может рассматриваться как результат (искусственного) разбиения значений двух непрерывных переменных на два класса, то коэффициент тетрахорической корреляции позволяет оценить зависимость между двумя этими переменными.
Коэффициент сопряженности. Коэффициент сопряженности представляет собой основанную на статистике хи-квадрат меру связи признаков в таблице сопряженности (предложенную Пирсоном). Преимущество этого коэффициента перед обычной статистикой хи-квадрат в том, что он легче интерпретируется, т.к. диапазон его изменения находится в интервале от 0 до 1 (где 0 соответствует случаю независимости признаков в таблице, а увеличение коэффициента показывает увеличение степени связи). Недостаток коэффициента сопряженности в том, что его максимальное значение "зависит" от размера таблицы. Этот коэффициент может достигать значения 1 только, если число классов не ограничено.
Интерпретация мер связи. Существенный недостаток мер связи (рассмотренных выше) связан с трудностью их интерпретации в обычных терминах вероятности или "доли объясненной вариации", как в случае коэффициента корреляции r Пирсона. Поэтому не существует одной общепринятой меры или коэффициента связи.
Статистики, основанные на рангах. Во многих задачах, возникающих на практике, мы имеем измерения лишь в порядковой шкале. Особенно это относится к измерениям в области психологии, социологии и других дисциплинах, связанных с изучением человека. Предположим, вы опросили некоторое множество респондентов с целью выяснения их отношение к некоторым видам спорта. Вы представляете измерения в шкале со следующими позициями: (1) всегда, (2) обычно, (3) иногда и (4) никогда. Очевидно, что ответ иногда интересуюсь показывает меньший интерес респондента, чем ответ обычно интересуюсь и т.д. Таким образом, можно упорядочить (ранжировать) степень интереса респондентов. Это типичный пример порядковой шкалы. Для переменных, измеренных в порядковой шкале, имеются свои типы корреляции, позволяющие оценить зависимости.
R Спирмена. Статистику R Спирмена можно интерпретировать так же, как и корреляцию Пирсона (r Пирсона) в терминах объясненной доли дисперсии (имея, однако, в виду, что статистика Спирмена вычислена по рангам). Предполагается, что переменные измерены как минимум в порядковой шкале.
Тау Кендалла. Статистика тау Кендалла эквивалентна R Спирмена при выполнении некоторых основных предположений. Также эквивалентны их мощности. Однако обычно значения R Спирмена и тау Кендалла различны, потому что они отличаются как своей внутренней логикой, так и способом вычисления. Показано соотношение между этими двумя статистиками следующим неравенством:
-1 < = 3 * Тау Кендалла - 2 * R Спирмена < = 1
Более важно то, что статистики Кендалла тау и Спирмена R имеют различную интерпретацию: в то время как статистика R Спирмена может рассматриваться как прямой аналог статистики r Пирсона, вычисленный по рангам, статистика Кендалла тау скорее основана на вероятности. Более точно, проверяется, что имеется различие между вероятностью того, что наблюдаемые данные расположены в том же самом порядке для двух величин и вероятностью того, что они расположены в другом порядке. Обычно вычисляется два варианта статистики тау Кендалла: taub и tauc. Эти меры различаются только способом обработки совпадающих рангов. В большинстве случаев их значения довольно похожи. Если возникают различия, то, по-видимому, самый безопасный способ - рассматривать наименьшее из двух значений.
Коэффициенты неопределенности. Эти коэффициенты измеряют информационную связь между факторами (строками и столбцами таблицы). Понятие информационной зависимости берет начало в теоретико-информационном подходе к анализу таблиц частот. Статистика S (Y,X) является симметричной и измеряет количество информации в переменной Y относительно переменной X или в переменной X относительно переменной Y. Статистики S(X|Y) и S(Y|X) выражают направленную зависимость.
Глава 5. Дисперсионный анализ
Цель дисперсионного анализа. Основной целью дисперсионного анализа является исследование значимости различия между средними. Это связано с тем, что при исследовании статистической значимости различия между средними двух (или нескольких) групп, мы на самом деле сравниваем (т.е. анализируем) выборочные дисперсии. Фундаментальная концепция дисперсионного анализа предложена Фишером в 1920 году. Возможно, более естественным был бы термин анализ суммы квадратов или анализ вариации, но в силу традиции употребляется термин дисперсионный анализ.
|
|
|
|
|
Дата добавления: 2014-12-26; Просмотров: 1180; Нарушение авторских прав?; Мы поможем в написании вашей работы!