КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Линия моделирования и базы данных
|
|
|
|
Изучаемые вопросы:
ª Признаки компьютерной информационной модели.
ª Является ли база данных информационной моделью.
ª Задачи, решаемые на готовой базе данных.
ª Проектирование базы данных (БД) — задача для углубленного курса.
Общая схема этапов решения практической задачи на ЭВМ методами информационного моделирования выглядит следующим образом (рис. 10.1):
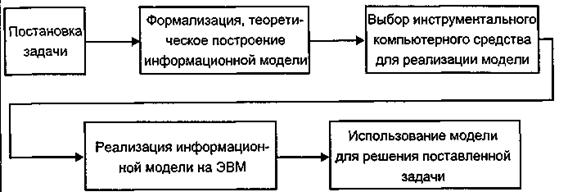
Рис. 10.1. Этапы решения задачи
Два первых этапа относятся к предметной области решаемой I задачи. На третьем этапе происходит выбор подходящего инструментального средства в составе программного обеспечения ЭВМ для реализации модели. Такими средствами могут быть: электронные таблицы, СУБД, системы программирования, математические пакеты, специализированные системы моделирования общего назначения или ориентированные на данную предметную область. В базовом курсе информатики изучаются первые три из ] перечисленных программных средств.
Основные признаки компьютерной информационной модели:
• наличие реального объекта моделирования;
• отражение ограниченного множества свойств объекта по принципу целесообразности;
• реализация модели с помощью определенных компьютерных средств;
• возможность манипулирования моделью, активного ее использования.
Ответ на вопрос: «является ли база данных информационной моделью?» будем искать, исходя их сформулированных выше критериев.
Первый критерий: наличие предметной области, некоторого реального объекта (системы), к которым относится БД, практически всегда выполняется. Например, если в БД содержатся сведения о книгах в библиотеке, значит объектом моделирования является книжный фонд библиотеки. Если БД содержит анкетные данные сотрудников предприятия, значит она моделирует кадровый состав этого предприятия. Если в БД хранятся сведения о результатах сдачи экзаменов абитуриентами в институт, следовательно, она моделирует процесс вступительных экзаменов и т.п.
|
|
|
Удовлетворение второму критерию также несложно обосновать. Каждый из моделируемых объектов (как перечисленные выше, так и любые другие) обладает гораздо большим числом свойств, характеристик, атрибутов, чем те, что отражены в БД. Отбор атрибутов, включаемых в БД, происходит в процессе проектирования базы, когда главным критерием является критерий целесообразности, т.е. соответствия цели создания БД, требованиям к ее последующим эксплуатационным свойствам. Например, в БД книжного фонда библиотеки не имеет смысла вносить такие характеристики книги, как ее вес, адрес типографии, где была напечатана книга, годы жизни автора и пр.
Третий критерий, очевидно, выполняется, поскольку речь идет о компьютерной базе данных, созданной в среде некоторой СУБД.
База данных — не «мертвое хранилище» информации. Она создается для постоянного, активного использования хранящейся в ней информации. Прикладные программы или СУБД, обслуживающие базу данных, позволяют ее пополнять, изменять, осуществлять поиск информации, сортировку, группировку данных, получение отчетных документов и пр. Таким образом, четвертый критерий компьютерной информационной модели также справедлив для БД.
В рамках обсуждаемой темы перед учителем информатики стоят две педагогические задачи: научить использовать готовые информационные модели; научить разрабатывать информационные модели. В минимальном варианте изучения базового курса предпочтение отдается первой задаче. В таком варианте ученикам могут быть предложены задачи следующего типа: имеется готовая база данных; требуется осуществить поиск нужной информации; выполнить сортировку данных по некоторому ключу; сформировать отчет с нужной информацией. Решение этой задачи не требует вмешательства в готовую модель.
|
|
|
Другой тип задач: расширить информационное содержание базы данных. Например, имеется реляционная база данных, содержащая сведения о книгах в библиотеке:
БИБЛИОТЕКА (НОМЕР. ШИФР, АВТОР, НАЗВАНИЕ)
Требуется изменить структуру БД таким образом, чтобы из нее можно было узнать, находится ли книга в настоящее время в библиотеке, и если книга выдана, то когда и кому.
Новые цели требуют внесения изменений в модель, в структуру базы данных. Ученики должны спланировать добавление новых полей, определить их типы. Решение может быть таким: после добавления полей база данных будет иметь следующую структуру:
БИБЛИОТЕКА (НОМЕР. ШИФР, АВТОР, НАЗВАНИЕ, НАЛИЧИЕ, ЧИТАТЕЛЬ, ДАТА)
Здесь добавлены поля:
— НАЛИЧИЕ — поле логического типа; принимает значение TRUE, если книга находится в библиотеке, и значение FALSE, если выдана читателю;
— ЧИТАТЕЛЬ — поле числового (или символьного) типа; содержит номер читательского билета человека, взявшего книгу;
— ДАТА — поле типа «дата»; указывает день выдачи книги. Несмотря на все сказанное выше, не следует преувеличивать в интерпретации каждого задания на работу с базой данных, как задачи моделирования. И на минимальном уровне изучения темы можно предлагать ученикам простые задачи на разработку баз данных, решение которых очевидно. К числу таких задач, например, относится задача разработки баз данных типа записной книжки с адресами знакомых, телефонного справочника и пр.
Проектирование баз данных. Проектирование базы данных заключается в теоретическом построении информационной модели определенной структуры. Известны три основные структуры, используемые при организации данных в БД: иерархическая (деревья), сетевая и табличная (реляционная). В последнее время чаще всего создаются БД реляционного типа. Доказано, что табличная структура является универсальной и может быть применена в любом случае. В базовом курсе информатики изучаются базы данных реляционной структуры.
Если объект моделирования представляет собой достаточно сложную систему, то проектирование БД становится нетривиальной задачей. Для небольших учебных БД ошибки при проектировании не столь существенны. Но если создается большая база, в которой будут сохраняться многие тысячи записей, то ошибки при проектировании могут стоить очень дорого. Основные последствия неправильного проектирования — избыточность информации, ее противоречивость, потеря целостности, т.е. взаимосвязи между данными. В результате БД может оказаться неработоспособной и потребовать дорогостоящей переделки.
|
|
|
Теория реляционных баз данных была разработана в 1970-х гг. Е.Коддом. Он предложил технологию проектирования баз данных, в результате применения которой в полученной БД не возникает отмеченных выше недостатков (см., например, [5]). Сущность этой технологии сводится к приведению таблиц, составляющих БД, к третьей нормальной форме. Этот процесс называется нормализацией данных: сначала все данные, которые планируется включить в БД, представляются в первой нормальной форме, затем преобразуются ко второй и на последнем шаге — к третьей нормальной форме. Проиллюстрируем процесс нормализации данных на примере.
Ставится задача: создать БД, содержащую сведения о посещении пациентами поликлиники своего участкового врача. Сначала строится одна таблица, в которую заносятся фамилия пациента, его дата рождения, номер участка, к которому приписан пациент, фамилия участкового врача, дата посещения врача и установленный диагноз болезни. Ниже приведен пример такой таблицы.
Таблица 10.2
БД «Поликлиника»
| Фамилия пациента | Дата рождения | Номер участка | Фамилия врача | Дата посещения | Диагноз |
| Лосев О. И. | 20.04.65 | Петрова О. И. | 11.04.98 | грипп | |
| Орлова ЕЮ. | 25.01.47 | Андреева И. В. | 05.05.98 | ОРЗ | |
| Лосев О. И. | 20.04.65 | Петрова О. И. | 26.07.98 | бронхит | |
| Дуров М.Т. | 05.03.30 | Петрова О. И. | 14.03.98 | стенокардия | |
| Жукова Л. Г. | 30.01.70 | Петрова О. И. | 11.04.98 | ангина | |
| Орлова Е.Ю. | 25.01.47 | Андреева И. В. | 11.07.98 | гастрит | |
| Быкова А.А. | 01.04.75 | Андреева И. В. | 15.06.98 | ОРЗ | |
| Дуров М.Т. | 05.03.30 | Петрова О. И. | 26.07.98 | ОРЗ |
|
|
|
Нетрудно понять недостатки такой организации данных. Во-первых, очевидна избыточность информации: повторение даты рождения одного и того же человека, повторение фамилии врача одного и того же участка. В такой БД велика вероятность иметь недостоверные, противоречивые данные. Например, если на втором участке сменится врач, то придется просматривать всю базу и вносить изменения во все записи, относящиеся к этому участку. При этом велика вероятность что-то пропустить. После каждого нового посещения пациентом больницы потребуется снова вводить его дату рождения, номер участка, фамилию врача, т.е. информацию, уже существующую в БД.
Полученная таблица соответствует первой нормальной форме. Для устранения отмеченных недостатков требуется ее дальнейшая нормализация. Структура такой таблицы (отношения) описывается следующим образом:
ПОЛИКЛИНИКА (ФАМИЛИЯ. ДАТА_РОЖДЕНИЯ, УЧАСТОК, ВРАЧ,
ДАТА ПОСЕЩЕНИЯ. ДИАГНОЗ)
Необходимо установить ключ записей. Здесь ключ составной, который включает в себя два поля: ФАМИЛИЯ и ДАТА_ПОСЕ-ЩЕНИЯ. Каждая запись — это информация о конкретном посещении пациентом больницы. Если допустить, что в течение одного дня данный пациент может сделать только один визит к участковому врачу, то в разных записях не будет повторяться комбинация двух полей: фамилии пациента и даты посещения врача.
Согласно определению второй нормальной формы, все неключевые поля должны функционально зависеть от полного ключа. В данной таблице лишь ДИАГНОЗ определяется одновременно фамилией пациента и датой посещения. Остальные поля связаны лишь с фамилией, т. е. от даты посещения они не зависят. Для преобразования ко второй нормальной форме таблицу нужно разбить на две следующие:
ПОСЕЩЕНИЯ (ФАМИЛИЯ. ДАТА ПОСЕЩЕНИЯ. ДИАГНОЗ)
ПАЦИЕНТЫ (ФАМИЛИЯ. ДАТА_РОЖДЕНИЯ, УЧАСТОК, ВРАЧ)
В отношении ПОСЕЩЕНИЯ по-прежнему действует составной ключ из двух полей, а в отношении ПАЦИЕНТЫ — одно ключевое поле ФАМИЛИЯ.
Во втором отношении имеется так называемая транзитивная зависимость. Она отображается следующим образом:
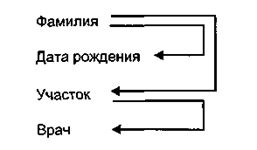
Значение поля ВРАЧ связано с фамилией пациента транзитивно через поле УЧАСТОК. В самом деле, всякий участковый врач приписан к своему участку и обслуживает больных, относящихся к данному участку.
Согласно определению третьей нормальной формы в отношении не должно быть транзитивных зависимостей. Значит требуется еще одно разбиение отношения ПАЦИЕНТЫ на два отношения.
В итоге получаем базу данных, состоящую из трех отношений:
ПОСЕЩЕНИЯ (ФАМИЛИЯ. ДАТА ПОСЕЩЕНИЯ. ДИАГНОЗ)
ПАЦИЕНТЫ (ФАМИЛИЯ. ДАТА_РОЖДЕНИЯ, УЧАСТОК)
ВРАЧИ (УЧАСТОК. ВРАЧ)
В третьем отношении ключом является номер участка, поскольку он повторяться не может. В то же время возможна ситуация, когда один врач обслуживает больше одного участка. Полученная структура БД удовлетворяет требованиям третьей нормальной формы: в таблицах все неключевые поля полностью функционально зависят от своих ключей и отсутствуют транзитивные зависимости.
Еще одним важным свойством полученной БД является то, что между тремя отношениями существует взаимосвязь через общие поля. Отношения ПОСЕЩЕНИЯ и ПАЦИЕНТЫ связаны общим полем ФАМИЛИЯ. Отношения ПАЦИЕНТЫ и ВРАЧИ связаны через поле УЧАСТОК. Для связанных таблиц существует еще одно понятие: тип связи. Возможны три варианта типа связей: «один — к —одному», «один —ко —многим», «многие —ко —многим». В нашем примере между связанными таблицами существуют связи типа «один —ко —многим», и схематически они отображаются так:
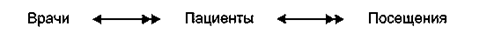
Смысл следующий: у каждого врача (на каждом участке) много пациентов; каждый пациент посещает врача множество раз.
В приведенном примере показана процедура нормализации в строгом соответствии с теорией реляционных баз данных. Понимание смысла этой процедуры очень полезно для учителя.
В школьном учебнике не представляется целесообразным подробно описывать формальную процедуру нормализации, приводить строгое определение трех нормальных форм. В учебнике [31, ч. 2] разговор на эту тему ведется на понятийном уровне. Используется нетрадиционный термин «хорошо нормализованная база данных». В этом понятии фактически заложены свойства третьей нормальной формы. Эти свойства сформулированы так: «Все поля таблицы должны отражать непосредственные характеристики (атрибуты) объекта, к которому относится запись». Ученикам предлагается следующая, в некотором смысле интуитивная, методика получения хорошо нормализованной БД. Все множество данных нужно разделить между различными объектами, к которым они относятся. На примере приведенной выше таблицы ПОЛИКЛИНИКА нужно увидеть три различных типа объектов, к которым относится данная информация: это пациенты поликлиники, врачи и посещения пациентами врачей. Соответственно строятся три таблицы, содержащие атрибуты, относящиеся к этим трем типам объектов и связанные между собой через общие поля.
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 666; Нарушение авторских прав?; Мы поможем в написании вашей работы!