КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
CELLS статистики смещения частот
|
|
|
|
CELLS
Параметр CELLS задает вывод некоторых статистик (см. ключевые слова параметра CELLS) для клеток таблицы сопряженности. " CELLS " переводится как "клетка". Если этот параметр не указан, то в клетках таблицы выводятся только абсолютные частоты.
CROSSTABS V1 BY V4 /CELLS = COUNT ROW COLUMN.
Параметры подкоманды /CELLS
COUNT - абсолютное число объектов (Nij);
ROW - проценты по строке;
COLUMN - проценты по столбцу;
TOTAL - проценты по отношению ко всей выборке;
EXPECTED - частоты (Eij=Ni.*N.j/N), ожидаемые в случае независимости переменных (N – общая сумма частот в таблице);
RESID - изменение частоты по сравнению с ожидаемым (Nij - Eij);
SRESID - стандартизованное изменение частоты по сравнению с ожидаемым (Nij - Eij)/ 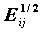 (корень из слагаемого статистики Хи-квадрат, вычисляемой для проверки гипотезы независимости);
(корень из слагаемого статистики Хи-квадрат, вычисляемой для проверки гипотезы независимости);
ASRESID - стандартизованное к нормальному распределению N(0,1) изменение частоты Zij =(Nij - Eij)/ σij;
ALL - вывод для клетки всех статистик;
Таблица 3.4. Связь "Точки зрения на иностранную помощь" и "Возможн. удовлетворить территор. требований Японии" (частоты и проценты)
| V1 точка зрения на иностранную помощь | V4 Возможность удовлетворить территориториальные требования Японии | Total | |||
| 1 отдать | 2 не надо | 3 не знаю | |||
| не нужна | Count | ||||
| % row | 12.0 | 81.7 | 6.3 | 100.0 | |
| % col | 19.6 | 27.2 | 13.9 | 24.6 | |
| огранич. | Count | ||||
| % row | 13.2 | 75.6 | 11.1 | 100.0 | |
| % col | 53.3 | 62.0 | 60.8 | 60.5 | |
| Нужна | Count | ||||
| % row | 37.0 | 43.8 | 19.2 | 100.0 | |
| % col | 25.2 | 6.1 | 17.7 | 10.3 | |
| не знаю | Count | ||||
| % row | 6.1 | 75.8 | 18.2 | 100.0 | |
| % col | 1.9 | 4.8 | 7.6 | 4.6 | |
| Total | Count | ||||
| % row | 15.0 | 73.9 | 11.1 | 100.0 | |
| % col | 100.0 | 100.0 | 100.0 | 100.0 |
Таблица 3.4 получена в результате преобразования данных и применения процедуры CROSSTABS с параметром CELLS:
|
|
|
recode v4 (1,2=1)(3=2)(4=3) into W4.
var lab W4 "Возможность удовлетворить территориториальные требования Японии".
Val lab W4 1 "отдать" 2 "не надо" "не знаю".
CROSSTABS /TABLES = v1 BY W4 /CELLS= COUNT ROW col.
Верхний процент в клетке соответствует отношению абсолютного числа объектов, попавших в эту клетку, к итоговой сумме по строке. Нижний процент соответствует отношению значения клетки к итоговой сумме по столбцу. По величине процентов, приведенных в клетках, можно сравнивать группы респондентов по распределению как по "вертикальной" переменной, так и по "горизонтальной".
В частности, анализируя первую строку матрицы (она соответствует ответам тех респондентов, которые считают, что иностранная помощь не нужна), видим, что основная часть - 81.7% этой группы респондентов против передачи островов Японии. При этом их доля среди тех, кто против передачи островов, составляет всего 27.2%; а основная часть (62.0%) противников передачи островов допускает возможность получения ограниченной иностранной помощи. В последнем столбце таблицы расположены итоги по каждой строке, которые совпадают с распределением по переменной V1. Так как до выполнения команды CROSSTABS, были объявлены неопределенные значения v1 и v4, таблица рассчитывалась без их учета, поэтому объем выборки, учтенный в таблице, составил 712 анкет из 721 имеющихся. Аналогичные данные приведены в строке TOTAL для столбцов.
Проценты в Crosstabs позволяют изучать взаимосвязь переменных, а не только структуру таблицы. В частности, сравнивая строки, можно сделать заключение, что более склонны отдать острова те, кто считает, что нужна помощь восточным регионам (37%), чем те, кто считает, что помощи не нужно. Можно взять в качестве точки отсчета распределение в целом по совокупности (15% всего готовы отдать все или часть островов в среднем по массиву).
|
|
|
Реализованные в параметре CELLS статистики позволяют провести более сложный анализ связи переменных. Например, в таблице 3.4 можно увидеть, что среди считающих, что иностранная помощь не нужна, 12% готовы отдать острова Японии, а среди считающих, что помощь нужна - их 37%. В то же время, в целом по совокупности 15% готовы передать острова. Существенны ли отличия от долей в целом по совокупности на 3% и 22%? Может ли в следующем обследовании связь оказаться противоположной? Основой для исследования смещения выборки от истинного распределения служат значения, ожидаемые в случае независимости выборки. Подпараметр EXPECTED параметра CELLS позволяет вывести в клетках абсолютные значения частот (Nij), ожидаемых в случае независимости соответствующих клетке значений переменных. Отклонение (Nij - Eij) наблюдаемой частоты от ожидаемой - более удобная величина для анализа: она достаточно наглядна, но неясно, насколько она статистически значима.
Более полезна статистика Zij =(Nij - Eij)/ σij - стандартизованное смещение частоты; Zij выдается в клетке при указании подпараметра ASRESID (Adjusted residuals). Иными словами, Zij представляет собой отклонение наблюдаемой частоты от ожидаемой, измеренное в числе стандартных отклонений. При этом стандартное отклонение вычисляется исходя из предположения, что Nij это случайная величина, имеющая гипергеометрическое распределение:

Если переменные независимы, то, при больших N, случайная величина Zij имеет нормальное распределение с параметрами (0,1). Для нее практически невероятно отклонение, большее трех стандартных отклонений, т.к. вероятность такого значения составляет менее 0.0027 (правило "трех сигм"). Поэтому, если мы получаем значение Zij, превышающее 3, то можем считать, что i -ое значение и j -ое значения X и Y связаны. На практике нередко, когда анализируетсся единственная клетка таблицы, выставляются более слабые требования. Существенными считаются односторонние отклонения, которые превышают 1,65σij - вероятность их получения составляет 5%. Таким образом, начиная с отклонения 1,65σij и большего, можно уже высказывать гипотезу о существовании связи между значениями (см. таблицу нормального распределения в любом статистическоим справочнике). Эмпирическим критерием, когда распределение Zij близким к нормальному, следует считать является соотношение для дисперсии 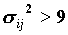 . Хотя последнее ограничение достаточно жестко.
. Хотя последнее ограничение достаточно жестко.
|
|
|
Следует заметить, что в действительности мы имеем дело с множеством статистик значимости и, при переборе их, велика вероятность случайно получить их значения, превышающие указанные пороги. Если бы клетки были независимы, при критическом значении статистики Zij, равном 1.96 (5% уровень значимости) мы в среднем в условиях независимости данных находили бы 5 "значимых" из 100 клеток таблицы, а хотя бы одну статистику, Zij >1.96 мы можем получить с вероятностью (1-0.95100)=0.! Поэтому сложившаяся практика руководствоваться отклонением 1.65 σij оберегает нас только от грубейших ошибок.
Таблица 3.5. Связь "Точки зрения на иностранную помощь" и "Возможностью удовлетворить территориальные требований Японии" (статистики смещений частот)
| V1 точка зр. на иностр. помощь | W4 Возможн. Удовлетворить территор. Требований Японии | Total | |||
| Отдать | Не надо | не знаю | |||
| не нужна | Count | ||||
| Expected Count | 26.3 | 129.3 | 19.4 | ||
| Residual | -5.3 | 13.7 | -8.4 | ||
| Adjusted Residual | -1.3 | 2.7 | -2.3 | ||
| Огранич. | Count | ||||
| Expected Count | 64.8 | 318.4 | 47.8 | ||
| Residual | -7.8 | 7.6 | 0.2 | ||
| Adjusted Residual | -1.7 | 1.3 | 0.0 | ||
| Нужна | Count | ||||
| Expected Count | 11.0 | 53.9 | 8.1 | ||
| Residual | 16.0 | -21.9 | 5.9 | ||
| Adjusted Residual | 5.5 | -6.2 | 2.3 | ||
| не знаю | Count | ||||
| Expected Count | 5.0 | 24.4 | 3.7 | ||
| Residual | -3.0 | 0.6 | 2.3 | ||
| Adjusted Residual | -1.5 | 0.3 | 1.3 |
Величина SRESID - стандартизованное изменение частоты по сравнению с ожидаемым (Nij - Eij)/ 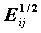 - связана с распределением Пуассона. Напомним, что распределение Пуассона - это распределение числа успехов для редко случающихся событий при большом числе испытаний. Если попадание наблюдения в клетку (i,j) считать этим редким событием, то ожидаемое значение
- связана с распределением Пуассона. Напомним, что распределение Пуассона - это распределение числа успехов для редко случающихся событий при большом числе испытаний. Если попадание наблюдения в клетку (i,j) считать этим редким событием, то ожидаемое значение 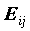 можно считать оценкой параметра распределения Пуассона. Дисперсия распределения Пуассона совпадает с его математическим ожиданием, отсюда (Nij - Eij)/ также отклонение, вычисленное в числе дисперсий. Это отклонение при больших ожидаемых частотах также асимптотически нормально.
можно считать оценкой параметра распределения Пуассона. Дисперсия распределения Пуассона совпадает с его математическим ожиданием, отсюда (Nij - Eij)/ также отклонение, вычисленное в числе дисперсий. Это отклонение при больших ожидаемых частотах также асимптотически нормально.
|
|
|
Пример. Определим зависимость между отношением к получению иностранной помощи и "Возможностью удовлетворить территориальные требований Японии":
CROSSTABS /TABLES=v1 BY W4/CELLS=COUNT expected resid asresid.
Так как в CELLS указан параметр COUNT, expected, resid и asresid, то в клетках выведены реальные и ожидаемые значения, а также абсолютная разность расчетной частоты от ожидаемой, и затем эта же разность, но в числе стандартных отклонений.
В таблице 3.5 получен ответ на поставленный в начале раздела вопрос: смещение частоты в клетке "Отдать острова" - "Нужна помощь" (residual=16) оказалось существенным, Z=5.5, в то же время смещение частоты на 5.3 в клетке "помощь не нужна - отдать" - не значимо (Z=1.3). Кроме того, в полученной значимой связи можно еще раз убедиться, рассмотрев таблицу 6 с процентными распределениями (в среднем по совокупности 15% считают, что острова можно отдать, в то время как в этой группе таковых 37%!). В то же время, судя по статистикам, хотя видна отрицательная связь значений "нужна ограниченная помощь" - "отдать острова", она не достаточно значима.
Надеемся, что нам удалось показать, что эти статистики наиболее интересны для интерпретации. К сожалению, в SPSS расчет 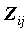 реализован без учета размеров выборки, что необходимо иметь в виду, так как для малых выборок эти вероятностные рассуждения оказываются неточными.
реализован без учета размеров выборки, что необходимо иметь в виду, так как для малых выборок эти вероятностные рассуждения оказываются неточными.
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 751; Нарушение авторских прав?; Мы поможем в написании вашей работы!