КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Команда MEANS - сравнение характеристик числовой переменной по группам
|
|
|
|
Двухвыборочный t-тест для связанных выборок (Paired sample T-TEST)
Если на одних и тех же объектах дважды измеряется некоторое свойство, то проверка значимости различия средних по измеренным переменным - для этого теста. Пример задания команды:
T-TEST PAIRS= x WITH y (PAIRED) /CRITERIA=CIN(.95).
Переменные X и Y могут быть характеристиками мужа и жены при исследовании семей; по данным RLMS - измерениями, связанными с потреблением напитков в 1996 и 1998 году и т.п. Поэтому данная процедура полезна для анализа панельных данных.
Почему же здесь нельзя воспользоваться таким же анализом, как и для двух несвязанных выборок, считая, что имеются две выборки одинакового объема?
Проверка значимости различия матожиданий X и Y эквивалентна проверке гипотезы о равенстве нулю математического ожидания разности X-Y. Дисперсия разности X-Y равна D(X-Y)=D(X)+D(Y)-2cov(X,Y). Отсюда точность оценки матожидани Х-Y связана с ковариацией X и Y.
Поэтому наряду с соответствующей статистикой в выдачу по этому тесту входит и коэффициент корреляции этих переменных и наблюдаемая значимость.
Для примера взгляните на выдачу, в которой сравниваются вес 1995 и 1996 г. женщин от 30 до 40 лет (в 1995), таблицы 4.5-7, данные RLMS.
Таблица 4.5. T-тест на связанных выборках, описательные статистики
| Mean | N | Std. Deviation | Std. Error Mean | |
| AM1 Вес 1995 | 67.59 | 13.72 | 0.49 | |
| BM1 Вес 1996 | 68.12 | 14.22 | 0.50 |
Таблица 4.6. T-тест на связанных выборках, корреляции
| N | Correlation | Sig. | |
| AM1 Вес 1995 & BM1 Вес 1996 | 0.914 | 0.0000 |
Таблица 4.7. T-тест на связанных выборках, сравнение средних
| Paired Differences Mean | Std. Deviation | Std. Error Mean | 95% Confidence Interval of the Difference | t | Df | Sig. (2-tailed) | ||
| Lower | Upper | |||||||
| AM1 Вес 1995 & BM1 Вес 1996 | -0.53 | 5.81 | 0.21 | -0.93 | -0.12 | -2.547 | 0.011 |
Женщины в среднем набрали по полкилограмма веса и этот прирост статистически значим. Значим и коэффициент корреляции - вес в целом имеет свойство сохраняться.
|
|
|
Процедура вычисляет одномерные статистики в группах - все описательные статистики, которые вычислялись командами Descriptives и Frequencies, а также гармоническое среднее, среднее геометрическое, проценты сумм значений переменных в группах и др. - всего 20 характеристик. Поэтому имя команды Means (Средние) сохранилось лишь исторически, пришло из ранних версий SPSS, где действительно ее назначением было сравнение средних. В диалоговом окне для назначения статистик используется кнопка "Options". Проводится также одномерный дисперсионный анализ.
MEANS TABLES=v14 BY v11 BY v8 /CELLS MEAN STDDEV MEDIAN COUNT /STATISTICS ANOVA.
В команде указывается список зависимых переменных, BY и список переменных, определяющих группы. Каждое дополнительное слово BY порождает следующий нижний уровень группирования, в диалоговом режиме слову BY соответствует кнопка NEXT.
Таблица 4.8. Среднемессячный душевой доход в семье
| V11 Cостояние в браке | V8 Пол | Mean | Std. Deviation | Median | N |
| 1 женат | 1 муж. | 228.4 | 152.9 | ||
| 2 жен. | 225.7 | 140.8 | |||
| Total | 227.1 | 147.2 | |||
| 2 вдовец | 1 муж. | 276.0 | 111.0 | ||
| 2 жен. | 192.8 | 112.7 | |||
| Total | 209.4 | 115.1 | |||
| 3 разведен | 1 муж. | 331.9 | 230.0 | ||
| 2 жен. | 195.9 | 86.1 | |||
| Total | 249.0 | 169.7 | |||
| 4 не был | 1 муж. | 263.3 | 223.0 | ||
| 2 жен. | 212.2 | 118.6 | |||
| Total | 240.2 | 183.9 | |||
| Total | 1 муж. | 238.4 | 167.8 | ||
| 2 жен. | 219.9 | 133.4 | |||
| Total | 229.3 | 152.0 |
Анализ результатов позволяет сделать следующие выводы. Самый высокий среднемесячный доход (332 руб.) имеют разведенные мужчины, при этом он значительно превосходит среднемесячный доход, полученный всеми разведенными (249 руб.) и всеми мужчинами (238 руб.). На втором месте по доходам находится вдовцы (276 руб.), но их всего 5 человек, поэтому цифра ненадежна. Среди женщин наиболее высокие среднемесячные доходы (226 руб.) у состоящих в браке, что почти равно доходам женатых мужчин. Это естественно - ведь это же душевой доход в семье.
|
|
|
Мы можем сколько угодно описывать эту таблицу, но описание не будет доказательством какой-либо истины, пока оно не подтверждено статистическим выводом. Такая таблица может быть источником гипотез о взаимосвязи, которые в дальнейшем следует проверить.
Одномерноый дисперсионный анализ здесь проводится только по переменным первого уровня задания групп.
Напомним, что суть этого анализа состоит в вычислениии межгруппового квадратичныого разброса зависимой переменной SSв (Between groups) и внутригруппового разброса, обозначается SSw (Within groups). Величина SSв характеризует, насколько сильно отклонились от общего среднего средние между группами, а SSw - отклонения от центров групп. Статистика 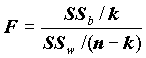 в условиях гипотезы равенства средних и дисперсий распределения при нормальном распределении X в группах имеет распределение Фишера. F представляет собой в определенном смысле расстояние наблюдаемой от таблицы, в которой нет никаких зависимостей - средние в группах совпадают. Чем больше F, тем существеннее зависимость, однако сама по себе величина F ни о чем не говорит. Ответ на вопрос дает, как обычно, величина наблюдаемой значимости F - критерия: SIGNIFICANCE - вероятность случайно получить значение F, большее выборочного SIG=P{F>Fвыб}.
в условиях гипотезы равенства средних и дисперсий распределения при нормальном распределении X в группах имеет распределение Фишера. F представляет собой в определенном смысле расстояние наблюдаемой от таблицы, в которой нет никаких зависимостей - средние в группах совпадают. Чем больше F, тем существеннее зависимость, однако сама по себе величина F ни о чем не говорит. Ответ на вопрос дает, как обычно, величина наблюдаемой значимости F - критерия: SIGNIFICANCE - вероятность случайно получить значение F, большее выборочного SIG=P{F>Fвыб}.
Еще раз обратим внимание на то, что в таком анализе используется предположение о нормальности распределения зависимой переменной. Не следует проводить непосредственно дисперсионный анализ переменных с существенно отличающимся от нормального распределением. Например, переменную "душевой доход"
В таблице4.9. приведена выдача одномерного дисперсионного анализа после выполнения команды
MEANS TABLES=lnv14m BY v11 BY v8 /STATISTICS ANOVA.
Наблюдаемый уровень значимости 0.707 свидетельствуе о том, что на наших данных указанным методом связь не обнаруживается.
Таблица 4.9. Результаты однофакторного дисперсионного анализа
| Sum of Squares | df | Mean Square | F | Sig. | ||
| LNV14M Логарифм душевого дохода * V11 Cостояние в браке | Between Groups | 0.40 | 0.13 | 0.465 | 0.707 | |
| Within Groups | 188.51 | 0.29 | ||||
| Total | 188.92 |
|
|
|
|
|
|
|
|
Дата добавления: 2014-12-27; Просмотров: 399; Нарушение авторских прав?; Мы поможем в написании вашей работы!