КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Информатизация судебной системы 4 страница
|
|
|
|
В почерковедческой экспертизе применяются следующие основные понятия.
Наклон почерка зависит от направления сгибательных движений при выполнении прямолинейных элементов. По наклону почерк бывает: прямой, право- и левонаклонный.

Рис. 27. Наклон почерка: А — прямой; Б — правонаклонный; В — левонаклонный

Рис. 28. Связность почерка: А — высокосвязный; Б — средний по степени связности; В — отрывистый
Нажим почерка выражает его интенсивность и размещение нажимов в процессе письма. Выработанность почерка отражает навык письма, осуществляемого в быстром темпе (скоропись). Связнность — способность пишущего выполнять непрерывным движением большее или меньшее количество элементов письменных знаков без отрыва пишущего прибора от бумаги. Сложность почерка тесно связана со степенью его выработанности; упрощение или усложнение письменных знаков и их связей по сравнению с принятыми нормами.
Дактилоскопическая экспертиза заключается в исследовании следов папиллярных узоров для установления фактов, связанных с образованием этих следов.
Основным объектом исследования в дактилоскопии является папиллярный узор пальцев рук (см. рис. 29).

Рис. 29. Папиллярный узор

Рис. 30. Типы папиллярных узоров
Папиллярные узоры делятся на три основных типа: завитковые (круговые), петлевые и дуговые.
Детали папиллярного узора — различные виды начала и окончания папиллярной линии, ее перерывы, резкие аномалии ее длины (обрывок, точка) и ширины (тонкие линии), раздвоение линий (вилы), комбинации раздвоений и аномалий длины (глазки, мостики, крючки).
Математические расчеты показывают, что полный и четкий отпечаток пальцев может повториться только один раз на 1030 или 1050 отпечатков.
|
|
|
Сочетание небольшого количества деталей настолько индивидуализирует узор, что для отождествления достаточно 7—10 деталей, хотя в полном узоре пальца их число достигает 120—150.
В последние годы формируется дерматоглифика — учение о кожных узорах. Представители данного направления разрабатывают способы использования данных дактилоскопии для решения следующих задач:
определение пола,
определение роста,
определение возраста,
определение дополнительных (приобретенных) статистических особенностей,
восстановление папиллярного узора и др.
§ 3. Математические основы криминалистической идентификации
Главной задачей судебно-экспертного исследования является идентификация криминалистических объектов.
В процессе криминалистической идентификации речь идет об объектах двоякого рода:
1) о следах (признаках), обнаруженных на месте преступления,
2) об образцах, полученных от подозреваемого лица (лиц).
Идентификации могут подлежать любые материальные предметы и явления, их роды и виды, количества и качества, человеческая личность в целом, ее отдельные признаки, физические свойства.
Процесс идентификации заканчивается установлением: факта тождества; факта отсутствия тождества сравниваемых объектов.
Вывод о тождестве опирается на идентификационный комплекс признаков — совокупность индивидуально-определенных, устойчивых признаков, неповторимых (или обладающих редкой встречаемостью), по их соотношению, местоположению, взаиморасположению и т. п.
Между двумя объектами установлено отношение тождества, если:
1. Между множеством признаков первого объекта и множеством признаков второго объекта имеется взаимно-однозначное соответствие.
2. Отсутствует существенное различие между первым и вторым объектами.
3. Соответствие между двумя объектами опирается на уверенность в том, что оно не является следствием случайного стечения обстоятельств.
|
|
|
Отношение тождества может быть представлено в следующем виде:
Q 1 º Q 2
Q 1 — первый объект;
Q 2 — второй объект;
º — знак тождества.
Графически отношение тождества двух объектов представлено на рис. 31.
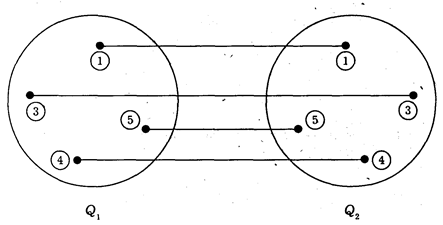
Рис. 31. Взаимно-однозначное соответствие двух объектов
Процесс идентификации опирается на два принципа:
принцип единственности выделенного объекта;
принцип оптимальности выделения такого объекта.
Наиболее характерной чертой идентификации является выделение единственного объекта из множества других объектов. Если такой объект выделен и степени его встречаемости дана приемлемая оценка, т. е. вероятность появления второго такого объекта практически ничтожна, то можно считать, что процесс идентификации достиг своего результата.*
* То есть совпадение деталей двух объектов не может быть случайным.
Например, вероятностная оценка комплекса признаков может составлять дроби:

Если эти частоты (вероятности) приемлемы в конкретных условиях, то они могут служить объективным критерием установления тождества. Очевидно, что чем дробь меньше, чем ее идентификационное значение больше, тем реже встречается выделенная совокупность признаков.
Процесс идентификации осуществляется путем постепенного сужения объема генеральной совокупности.
Пусть в качестве такой совокупности будет 100 млн. граждан, умеющих писать по-русски. Тогда по данному признаку можно выделить группу в 106 человек, каждый из которых может быть исполнителем исследуемой рукописи и т. д. Нельзя сказать априори, сколько признаков необходимо использовать при решении задачи идентификации. Все зависит от идентификационной значимости каждого признака и их комплекса.
Особо значимо нахождение таких признаков, которые встречаются крайне редко, т. е. имеют очень низкую вероятность появления. Так, метод генной идентификации основан на том, что строение молекул ДНК — носителей генетической информации — у всех существ одного вида одинаково, но некоторые зоны, разбросанные вдоль всей молекулы, повторяются у каждого в разной последовательности и сочетаниях. Вероятность совпадения таких участков у двух людей 1:30 млрд., т. е. практически нулевая. Генный "отпечаток" имеется в любой клетке, появляется возможность его использования для идентификации личности.
|
|
|
Однако и события, обладающие очень малой вероятностью, осуществляются вполне закономерно. Маловероятные события при многократно повторяемом явлении приобретают вполне устойчивую определенность, хотя и происходят в одном случае из многих миллионов.*
* Так, с точки зрения теории вероятностей возникновение жизни на Земле представляется необычайно редким событием. Тем не менее оно произошло.
Если взять два независимых друг от друга признака, то в совокупности они будут обладать большей идентифицирующей способностью.
Это требует применения теоремы умножения вероятностей.
Обозначим буквами А, В, С случайные события — появление признаков определенного рода. Например:
А —появление первого взятого признака;
В — появление второго признака;
С — появление третьего признака.
Тогда идентифицирующий комплекс может быть представлен в виде произведения случайных событий:
Q = A • В • С.
Если эти признаки независимы, то для определения вероятности их совокупности необходимо перемножить вероятности, относящиеся к каждому признаку, по формуле:
Р (Q) = Р(А) • Р (В) • Р(С),
где символ Р обозначает вероятность появления каждого признака.
Вероятности Рi встречаемости признака А соответствует идентификационная значимость (информативность признака):
J i = – lg Pi.
Принцип оптимальности процесса идентификации заключается в том, что используется критерий достаточности выделения определенного числа признаков.
В этих целях воспользуемся величинами
N — генеральная совокупность признаков.
1 /N — величина обратная размеру генеральной совокупности.
Примеры величины N:
число всех жителей данной страны,
число всех жителей данной страны, пишущих на определенном алфавите,
число пишущих машинок в определенном городе,
число единиц огнестрельного оружия определенного вида и т.д.
Величина 1 /N должна быть учтена при установлении тождества. Основная идентификационная формула приобретает вид:
|
|
|
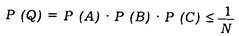 (1)
(1)
Другими словами, вероятность появления комплекса признаков должна быть меньше (или равна) величины 1/ N.
Величина 1 /N показывает, каков предел величины Р(Q). Если Р(Q) < 1 /N, то дальнейшее уменьшение величины Р(Q) нецелесообразно.
Процесс идентификации протекает лучше, когда величина N относительно невелика. Соответственно небольшой является и величина 1 /N.
Например, если N = 10 000, то вероятность встретить в генеральной совокупности выделенный объект не столь велика. При этом выделение одного-единственного объекта существенно облегчено. Если величина N растет, то необходимо понижать величину дроби Р(Q).
При нарушении неравенства (I):
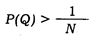
идентификационное значение установленных признаков падает. Возрастает вероятность того, что может появиться второй признак, обладающий выделенным набором.
При анализе возникшей ситуации целесообразно брать величины, обратные используемым вероятностям.
Рассмотрим пример.
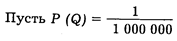
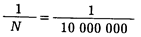
Обратными величинами в данном случае будут Q * = 106 и N * = 107.
Один выделенный признак будет приходиться среднестатистически на 106 признаков. Но наша генеральная совокупность в 10 раз больше. Следовательно, вероятность встретить второй объект возрастает в 10 раз.
В процессе применения математических методов в криминалистике и судебной экспертизе принципиальное значение имеет установленный теорией вероятностей принцип практической уверенности.
В силу этого принципа событие, имеющее очень низкую вероятность, считается недостоверным (т. е. его значение приравнивается к 0).
Если вероятность события А в данном опыте весьма мала, то можно быть практически уверенным в том, что при однократном выполнении опыта событие А не произойдет.
Принцип практической уверенности не может быть доказан математическими средствами. Он подтверждается всем опытом человечества. При оценке надежности заключения эксперта о тождестве объекта в расчет берется вся совокупность обстоятельств уголовного дела.
Описанный аппарат обладает большой степенью общности и позволяет решить задачу идентификации для объектов различной природы (например, профилограмм в трасологии, спектрограмм и осциллограмм в физико-химических исследованиях, вообще для произвольных одномерных графических образов).
Процесс криминалистической идентификации, в том числе личности по почерку, является творческим, сложным мыслительным процессом. Эксперт-криминалист изучает все признаки сравниваемых объектов. Он изучает все особенности, выявляет их сущность, взаимосвязь и зависимость от различных факторов, всю совокупность качественных и количественных признаков.
§ 4. Математические методы установления групповой принадлежности объектов
В судебно-экспертных исследованиях установление групповой принадлежности нередко выступает в качестве самостоятельной экспертной задачи. Групповая принадлежность — это принадлежность некоторого объекта Х к одному из подмножеств множества М0:
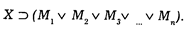
С позиций теории вероятностей данная задача может рассматриваться как вариант проверки статистических гипотез. Надо проверить гипотезы:
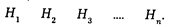
В данном случае символ Нi означает статистическую гипотезу о принадлежности исследуемого криминалистического объекта к группе со значком " i ".
Например, это принадлежность автора рукописи к мужскому или женскому полу, той или иной возрастной, образовательной группе; принадлежность исследуемых химических материалов к тому или иному типу вещества; принадлежность исследуемого вещества к одной из марок бензина.
В. И. Пашкова разработала методику определения половой принадлежности человека по черепу. В результате исследования 682 мужских и женских черепов она получила функции распределения для 25 измерительных признаков и предложила доступную для всех методику оценки с помощью пяти характеристических интервалов (1958).
Возможность установления групповой принадлежности основывается на факте, что той или другой группе объектов свойственно наличие комплекса специфических признаков. Критерием распознавания группы является высокая вероятность одновременного проявления совокупности признаков в одной группе и практическая невозможность проявления этой совокупности в какой-либо другой группе.
В данном случае криминалистическую ценность имеют такие признаки, которые наиболее вероятны.*
* Этим задачи определения групповой принадлежности отличаются от обычной идентификационной задачи, где имеют значение как раз наиболее редко встречающиеся признаки и их вероятности.
В простых случаях в качестве показателя групповой принадлежности можно использовать отношение произведений условных вероятностей в группах:
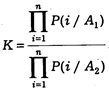
В этом выражении приняты следующие обозначения: Р (i/A 1 ) — вероятность i -го признака в группе А1 (например, в группе мужчин);
Р (i/A 2 ) — вероятность i -го признака в группе женщин.
Если К > 1, то почерк принадлежит лицу мужского пола.
Если К < 1, то почерк принадлежит лицу женского пола.
С другой стороны, должны быть учтены и такие признаки, которые встречаются редко и малохарактерны для данной группы объектов.
С задачей определения групповой принадлежности соприкасается и такая задача, как дифференциация объектов.
Основная сущность криминалистической дифференциации заключается не только в том, что при исследовании используются различия. Более важно то, что при дифференциации обязательно должна решаться дихотомическая задача, т. е. отнесение исследуемого объекта к одному из двух классов.
3. И. Кирсанов с другими криминалистами выполнили статистические исследования, цель которых —установление зависимости относительной частоты встречаемости некоторых признаков почерка от пола, возраста, образования.
Анализ практики применения специалистами-почерковедами методик дифференциации рукописей на мужские и женские показал относительно высокую надежность результатов проводимых исследований. Научно-криминалистическим центром МВД проведены исследования признаков почерка в прописных буквах русской скорописи. Анализ статистических данных распределения признаков почерка осуществлялся на 800 образцах рукописей с использованием ЭВМ "Искра-226" и ЕС-1055. Исследовательская работа, связанная с поиском критериев разграничения мужских и женских рукописей, основывалась на вероятностно-статистическом анализе признаков почерка. Для решения указанной задачи был применен аппарат теории распознавания образов, а именно — способ оптимальной двоичной дискриминации классов.
Предлагаемый метод:
ориентирован на использование различных элементов рукописи средневыработанного и высоковыработанного почерка (прописные и строчные буквы);
предусматривает различные варианты применения — от ручной технологии построения заключений до автоматизированной;
позволяет проводить количественную оценку качества принимаемого решения о поле исполнителя рукописи с учетом индивидуальных особенностей.
Правило принятия решения для дискриминатора, оптимального по критерию минимума средней вероятности ошибки, имеет вид:
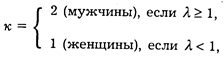
где l — отношение правдоподобия
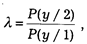
где Р(у/ 2 ), Р(у/ 1 ) — оценки условных вероятностей появления вектора значений признаков у для объектов, принадлежащих второму и первому классу.
Во ВНИИ МВД РФ было выполнено исследование, позволяющее определять пол человека по эпителиальным клеткам волос.
Литература
Автоматизированные рабочие места и компьютерные системы органов внутренних дел. М., 1993.
Белкин Р. С. Криминалистическая энциклопедия. М., 1997.
Буринский Е. Ф. Судебная экспертиза документов. СПб., 1903.
Викарук А. Я., Гегечкори Л. А. Математические аспекты экспертно-криминалистической идентификации // Правовая информатика. Вып. 3. 1998.
Вероятностно-статистические методы в почерковедческих исследованиях. М., 1974.
Грановский Г. Л. Основы трасологии. М., 1974.
Жарков Е. А., Булдарев Е. К., Ковшов В. К. Установление количественных критериев криминалистической идентификации. М., 1985.
Кирсанов З. И., Рогозин А. П. Методика распознавания по почерку возраста и пола исполнителя рукописи // Вероятностно-статистические методы почерковедческих исследований. М., 1976.
Кирсанов В. И., Рогозин А. П. Распознавание пола и возраста исполнителя рукописи по почерку // Правовая кибернетика. М., 1973.
Кирсанов З. И. Математические методы в криминалистике // Вопросы кибернетики и права. М., 1967.
Методика определения пола исполнителя кратких рукописных текстов. М., 1990.
Пашкова В. И. Определение пола и возраста по черепу. Ставрополь, 1958.
Полевой Н. С. Криминалистическая кибернетика. М., 1989.
Пошкявичюс В. А. Возможности дифференциации рукописных знаков методом проверки статистических гипотез с использованием ЭВМ // Проблемы правовой кибернетики. М., 1968.
Применение теории вероятностей и математической статистики в судебной экспертизе: Материалы научной конференции 5—6 июня 1963 г. М., 1964.
Растрагин Л. А. Об идентификаций плоских изображений пространственных объектов // Вопросы кибернетики и права. М., 1967.
Статистическая дактилоскопия. Вопросы методологии / Под ред. Л. Г. Эджубова. М., 1999.
Собко Г. М. Основы применения математических методов в судебно-почерковедческих исследованиях. М., 1980.
Собко Г. М. Применение формализованных языков для описания почерковых объектов (подписей, кратких записей) в идентификационных исследованиях (научно-методические рекомендации). М., 1978.
Стечнова Т. В., Печерский В. Л., Князенков С. Н. Волосы головы как объект судебно-биологической экспертизы. М., 1990.
Эджубов Л. Г. Использование кибернетики и ЭВМ в криминалистике и судебной экспертизе // Кибернетика и право. М., 1970.
Эджубов Л. Г. Некоторые криминалистические проблемы автоматизации судебно-экспертных исследований // Правовая кибернетика. М., 1977.
Эджубов Л. Г. Структурный анализ папиллярного узора и пути определения объема дактилоскопической информации. Проблемы правовой кибернетики // Материалы симпозиума. М., 1968.
Эджубов Л. Г., Брудовский Б. С. О критерии дактилоскопического тождества // Правовая кибернетика. М., 1973.
Хвыля-Олинтер В. И. Математическая модель дактилоскопического изображения // Информ. бюлл. Вып. 11. М., 1990.
Глава 10. Социологическая информация
§ 1. Математическая фирма представления эмпирических данных
Социологическая (социально-правовая) информация — это информация, которая получается в результате организации и проведения правовых социологических исследований.*
Главы десятая и одиннадцатая написаны совместно с кандидатом технических наук, доцентом МГИМО МИД РФ Л. Д. Гавриловой.
* Социология права — часть общей теории права, в задачу которой входит изучение социальной эффективности и социальной обусловленности права.
Цели этих исследований могут быть сформулированы следующим образом:
1) выявление на базе опроса экспертов (юристов, экономистов, социологов, демографов, экологов, представителей технических специальностей и др.) всего круга общественных отношений, которые должны регулироваться данным актом;
2) выявление всех субъектов права, интересов, потребностей и статусов, которые могут быть затронуты законопроектом;
3) анализ потенциальной активности подготавливаемого акта на базе учета иных социальных регуляторов, которые вместе с данным актом будут воздействовать на регулируемые отношения и процессы;
4) предварительный анализ эффективности юридических процедур, которые должны быть включены в законопроект и призваны обеспечить и гарантировать точное применение его норм и принципов;
5) социологический и юридический анализ возможных отклонений от требований данного акта, возможных правонарушений и методов их предупреждения, анализ мер юридической ответственности за нарушение требований акта.
Аксиоматический подход выражается во введении некоторых точных математических определений признаков и свойств первичной количественной информации и использовании математических моделей ее представления.
В социально-правовом исследовании имеется конечное множество социальных объектов, подлежащих изучению. Это множество (оно может быть довольно большим) представляет собой генеральную совокупность. Обозначим его буквой N:
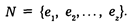
Находящиеся в фигурных скобках буквы обозначают конкретные объекты социологического анализа.
Из этого множества по определенным правилам выборочного метода (см. ниже) отбирается для непосредственного исследования некоторое подмножество М:
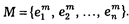
При этом: 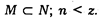
Подмножество М и является непосредственным объектом социологического исследования.
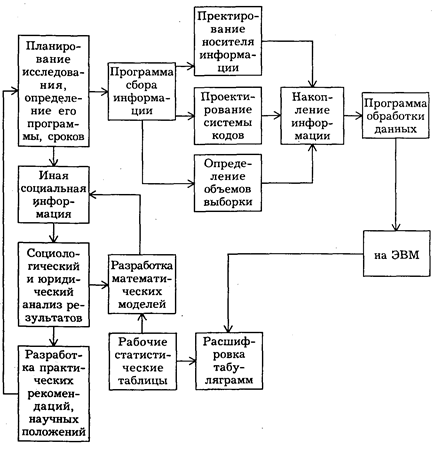
Рис. 32. Основные этапы правового конкретно-социологического исследования с применением ЭВМ и математических методов
Каждый элемент полученной совокупности обладает значительным числом свойств. Из них необходимо выделить те, которые представляют интерес для целей данного социально-правового исследования.
Выделенное свойство единицы (объекта) социологического наблюдения на математическом языке называется признаком (или параметром, показателем).
Признаки могут быть либо количественными (возраст, образование, размер территории региона, численность населения и т. д.), либо качественными (пол, место жительства, юридическая квалификация действия, ориентация на правовые ценности и т. д.).
Каждый объект социологического анализа характеризуется набором признаков:
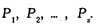
В содержании понятия "признак" необходимо выделить такой важный аспект, как его значение. Например, "образование" — это признак (показатель). "Начальное", "среднее", "высшее" — значения данного признака. Значения признака называют также его уровнями (или градациями).
Выделим из множества всех признаков некоторый признак Р. Он может принимать значения: p i 1, р i 2,..., р im:
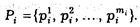
Каждый объект социологического наблюдения характеризуется упорядоченным набором значений признаков:
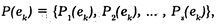
где еk — выделенный объект исследования; Рi (еk) — значение признака Рi, соответствующее объекту еk; s — общее число признаков, подлежащих изучению.
Значения каждого, признака порождают разбиение исследуемой совокупности объектов на тi классов, где тi — число значений выделенного признака Рi.
Вектор-строкой называется упорядоченная система чисел, записанных в виде одной строки. Вектор-строка имеет следующий вид:
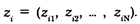
Строки матрицы эмпирических данных соответствуют отдельным социологическим объектам. Каждый объект описывается набором конкретных значений параметров.
Пусть в качестве объектов социологического наблюдения выступают отдельные индивиды. Тогда для произвольно взятого индивида вектор-строка будет содержать набор его количественных и качественных признаков в их конкретных значениях:

где цифры условно обозначают следующие значения признаков: 1 — женщина; 32 — возраст; 3 — законченное высшее образование; 80 — доход в рублях на одного члена семьи; 2 — средний уровень социально-правовой активности.
Каждый столбец матрицы эмпирических данных удобно рассматривать как вектор. Его можно назвать вектор-столбцом наблюдений:
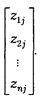
Вектор-столбец можно интерпретировать как совокупность значений какого-либо признака, отнесенных к разным объектам социологического наблюдения. Так, это может быть совокупность ответов разных респодентов на один и тот же вопрос социологической анкеты.
В форме вектор-столбца могут быть представлены и некоторые другие данные эмпирического исследования. Так, возраст индивидов является признаком, который принимает конкретные числовые значения: 50, 25 лет, 31 год, 40 лет. Вектор-столбец в данном случае имеет следующий вид:
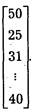
Основной массив социологической информации, характеризующей правовые объекты, содержит так называемые качественные признаки.
В правовом конкретно-социологическом исследовании возможно использование и таких показателей, которые заведомо обладают количественной мерой. Количественным признаком может служить, например, возраст индивидов, доход на одного члена семьи, уровень урбанизации, который действует на многие социально-правовые процессы и явления (правосознание, информированность, правонарушения и т. д.).
Количественными являются многие характеристики административно-территориального устройства: размер территории, численность населения, численность аппарата управления и т. д. При создании программы для ЭВМ целесообразно также предусмотреть обработку признаков, выраженных количественно.
Среднее значение для п наблюденных значений количественного параметра zj определяется так:
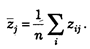
Частное значение zij называется наблюденным (выборочным) значением и соответствует измерению при произвольном начале координат и произвольных единицах измерения.
Для удобства математико-статистического анализа принято приводить количественные признаки к стандартному виду — центрировать и нормировать их.
Центрированное значение i -го признака j- го объекта равно разности между конкретным значением признака z'ij и средним по всем объектам значением этого признака 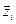 :
:
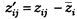
Центрирование признака означает перенос начала координат в точку, соответствующую среднему его значению.
Нормирование признака имеет целью представить его в некоторых безразмерных единицах, характеризующих относительное значение признака. Наиболее часто каждое значение признака относят к его эмпирическому среднеквадратичному отклонению  (по всем объектам):
(по всем объектам):
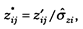
где

|
|
|
|
|
Дата добавления: 2015-04-25; Просмотров: 793; Нарушение авторских прав?; Мы поможем в написании вашей работы!