КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Суперскалярные процессоры и процессоры с длинным командным словом
|
|
|
|
Современные микропроцессоры содержат десять и более обрабатывающих устройств, каждое из которых представляет собой конвейер. В случае эффективной загрузки параллельно функционирующих устройств возможно получение в одном такте нескольких результатов операций, представленных скалярами: целочисленными операндами или операндами с плавающей точкой.
Эффективная загрузка параллельно функционирующих конвейеров обеспечивается либо аппаратурой процессора, либо компилятором, на вход которого поступают программы на традиционном последовательном языке программирования, либо совместно аппаратурой и компилятором.
В компиляторах используется изощренная техника извлечения параллелизма из последовательных программ. Аппаратура микропроцессоров ориентирована па выделение более простых форм параллелизма, в том числе естественного.
Есть два крайних подхода, при возможных промежуточных, к отображению присущего микропроцессору внутреннего параллелизма обработки данных на архитектурном уровне в системе команд. Первый подход более консервативен и состоит в том, что никакого указания на параллельную обработку внутри процессора система команд не содержит. Такие процессоры относятся к классу суперскалярных. Такое название, с одной стороны, отличает эти процессоры от векторных процессоров, а с другой стороны, подчеркивает присущий этим процессорам внутренний параллелизм, обеспечивающий получение в одном такте нескольких скалярных результатов.
Второй подход, напротив, полностью открывает пользователю все возможности параллельной обработки. В специально отведенных полях команды каждому из параллельно работающих обрабатывающих устройств предписывается действие, которое устройство должно совершить. Такие процессоры называются процессорами с длинным командным словом (VLIW). Предполагается, что существуют компиляторы с языков высокого уровня, которые готовят программы для загрузки их в микропроцессоры.
|
|
|
Суперскалярные и VLIW-процессоры принадлежат классу архитектур, которые используют параллелизм уровня команд (ILP).
Зависимости между командами, препятствующие их параллельному исполнению
В соответствии с моделью последовательного программирования программы пишутся в предположении, что команды будут выполнены в том же порядке, в каком они представлены в программе. Однако с целью достижения большей эффективности современные процессоры пытаются выполнять несколько команд одновременно и, в некоторых случаях, в порядке, отличном от их исходной последовательности в программе. Это переупорядочение может быть выполнено в трансляторе и (или) в аппаратных средствах во время выполнения.
ILP-процессоры и компиляторы обычно преобразуют полностью упорядоченное множество команд исходной программы в частично упорядоченное множество, структурированное зависимостями по данным и управлению. Зависимости по управлению (которые проявляются как переходы по условию) представляют главное препятствие высокопараллельному выполнению потому, что эти зависимости должны быть установлены прежде, чем будут выполнены все последующие команды.
Текст последовательной программы, представленной на языке высокого уровня, компилируется в машинный код, отражающий статическую структуру программы, т. е. упорядоченное множество команд (инструкций) в памяти компьютера. Процесс выполнения программы с конкретными наборами входных данных может быть представлен динамической структурой программы, т. е. множеством последовательностей команд в порядке их исполнения.
|
|
|
Повысить степень параллелизма программы можно, изменяя соответствующим образом ее статическую или динамическую структуру. Поскольку статическая структура программы однозначно соответствует ее исходному тексту (в предположении неизменности компилятора), то изменение статической структуры сводится к изменению исходного кода, что, в общем случае, не всегда возможно. Динамическая же структура программы может быть изменена при неизменной статической структуре. И главной целью такого изменения должно быть повышение степени параллельного исполнения команд.
Допустимые границы преобразования динамической структуры программы задают существующие на множестве инструкций отношения: зависимость по управлению и зависимость по данным. При описании архитектур суперскалярных процессоров используется модель окна исполнения. При исполнении программы микропроцессор как бы продвигает по статической структуре программы окно исполнения, тем самым ограничивая совокупность команд, которые рассматриваются на предмет наличия между ними зависимостей по данным и управлению. Команды в окне могут исполняться параллельно, если между ними нет зависимости.
Для устранения зависимостей, вызванных командами переходов, используется метод предсказания, позволяющий извлекать и условно исполнять команды предсказанного перехода. Если позднее обнаруживается, что предсказание было сделано верно, результаты условно исполненных команд принимаются. Если предсказание было ошибочным, состояние процессора восстанавливается на момент принятия решения о выполнении перехода.
Команды, помещенные в окно исполнения, могут быть зависимы по данным. Эти зависимости обусловлены использованием одних и тех же ресурсов памяти (регистров, ячеек памяти) в разных командах. Поэтому для правильного исполнения программы необходимо использование этих ресурсов в предписываемом программой порядке.
Все виды зависимостей по данным могут быть классифицированы по типу ассоциаций: RAR – "чтение после чтения", WAR – "запись после чтения" и WAW – "запись после записи", RAW – "чтение после записи".
Пример различных зависимостей команд по данным показан на рис. I.15.
|
|
|
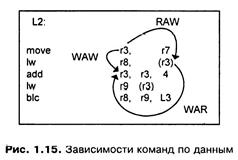
Некоторые из зависимостей по данным могут быть устранены. RAR, по сути дела, соответствует отсутствию зависимостей, поскольку в данном случае порядок выполнения команд не имеет значения. Действительной зависимостью является только "чтение после записи" (RAW), т. к. необходимо прочитать предварительно записанные новые данные, а не старые.
Лишние зависимости по данным появляются в результате "записи после чтения" (WAR) и "записи после записи" (WAW). Зависимость WAR состоит в том, что команда должна записать новое значение в ячейку памяти или регистр, из которых должно быть произведено чтение. Лишние зависимости  появляются по нескольким причинам: неоптимизированный программный код, ограничение количества регистров, стремление к экономии памяти, наличие программных циклов. Важно отметить, что запись может быть произведена в любой свободный ресурс, а не только тот, который указан в программе.
появляются по нескольким причинам: неоптимизированный программный код, ограничение количества регистров, стремление к экономии памяти, наличие программных циклов. Важно отметить, что запись может быть произведена в любой свободный ресурс, а не только тот, который указан в программе.
После удаления лишних зависимостей по управлению и данным команды могут исполняться параллельно. Формирование расписания параллельного выполнения команд возлагается на аппаратные средства микропроцессора. Это расписание учитывает существующие зависимости между командами и имеющиеся функциональные модули процессора.
В современных микропроцессорах широко используется принцип конвейерного выполнения отдельных элементарных операций. Конвейеризация внутренних процессов позволяет получать результат в каждом процессорном такте.
Структурный параллелизм микропроцессоров с разнесенной архитектурой
Стремление использовать присущий большинству программ естественный параллелизм вычисления целочисленных адресных выражений и собственно обработки данных в формате с плавающей точкой привело к появлению разнесенных архитектур (decoupled architecture) [11].
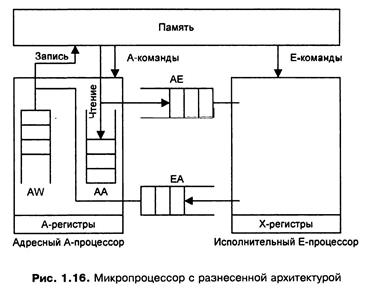
В первом приближении микропроцессор с разнесенной архитектурой, как показано на рис. 1.16, состоит из двух связанных подпроцессоров, каждый из которых управляется собственным потоком команд.
|
|
|
Условно эти подпроцессоры называются адресным А-процессором и исполнительным Е-процессором. А- и Е-процессоры имеют собственные наборы регистров АО, Al,... и ХО, XI,... соответственно и наборы команд. А-процессор выполняет все адресные вычисления и формирует обращения к памяти по чтению и записи, он является обыкновенным целочисленным процессором, поэтому способен осуществлять произвольные целочисленные преобразования, не связанные с вычислением адресов. Е-процессор реализует вычисления с плавающей точкой.
Данные, извлекаемые из памяти, используются либо в А-процессоре, будучи помещенными в FIFO-очередь АА, либо помещаются в FIFO-очередь, называемую АЕ-очередью, для отсылки в Е-процессор. Когда Е-процессору требуются данные из памяти, он берет их из очереди АЕ. Если очередь пуста, Е-процессор задерживается до поступления данных, что решает вопросы синхронизации работы А- и Е-процессоров. Если Е-процессор выработал данные, которые должны быть отправлены в память, то он помещает их в FIFO-очередь ЕА.
При записи данных в память после вычисления адреса А-процессор сразу отправляет адрес в FIFO-очередь AW адресов записи в память, не дожидаясь, пока данные поступят в очередь ЕА. А-процессор группирует пары, выбирая первые элементы очередей ЕА и AW и отправляя эти пары в память. Естественно, если одна из очередей или обе пусты, то отсылка в память приостанавливается.
При чтении данных А-процессор отправляет адреса в память с указанием очередей АА пли АЕ, в которые должны быть считаны данные из памяти.
Разнесенная архитектура позволяет достигать при скалярной обработке производительности, характерной для векторных процессоров, за счет предвыборки данных из памяти и автоматической развертки нескольких последовательных витков цикла в А-процессоре. Проблемы расщепления программы на программы для А- и Е-процессоров решаются на уровне компилятора или специальным блоком-расщепителем.
Предварительная выборка команд и предсказание переходов
Основная идея, определяющая развитие суперскалярных микропроцессоров [12], состоит в построении микропроцессоров с как можно большим количеством функциональных устройств при сохранении традиционных последовательных программ. Это означает, что компиляторы и аппаратура микропроцессора сами, без вмешательства программиста, обеспечивают загрузку параллельно работающих функциональных устройств микропроцессора.
Типовая архитектура суперскалярного микропроцессора представлена на рис. 1.17.
В число основных блоков суперскалярного микропроцессора входят: блок выборки команд и предсказания переходов, блок декодирования команд, анализа зависимостей между командами, переименования и диспетчеризации, блоки регистров и обрабатывающих устройств с плавающей и фиксированной точками, блок управления памятью, а также блок упорядочения выполненных команд.
Поскольку при суперскалярной обработке необходимо извлекать из памяти несколько команд за один такт для загрузки параллельно работающих функциональных модулей, повышенные требования предъявляются к пропускной способности интерфейса микропроцессор-память. В современных микропроцессорах применяются многоуровневые раздельные типы кэш-памяти данных и команд.

Рис. 1.17. Архитектура суперскалярного микропроцессора
Серьезную проблему для эффективной загрузки функциональных устройств представляют команды ветвления. Если требуется осуществить смену значения счетчика команд, то необходим, по крайней мере, один такт для распознавания команды ветвления, модификации счетчика команд и выборки команды по заданному значению счетчика команд. Эти задержки вызывают пустые такты в конвейерах процессора.
Для предотвращения появления пустых тактов возможно использование "отложенных переходов", когда одна или несколько команд после команды ветвления выполняются безусловно.
Более сложные решения используют:
ü предсказание переходов;
ü выполнение с изменением порядка следования команд;
ü условное (предикативное) исполнение.
При предсказании переходов, не дожидаясь определения команды, на которую должен быть сделан переход, начинается выборка и исполнение команд по предсказанному направлению перехода или условное исполнение команд. В случае ошибки предсказания необходимо уничтожить вес результаты работы неверно выбранных команд. Количество потерянных при этом тактов процессора зависит от глубины конвейеров функциональных устройств и их числа. В современных микропроцессорах число теряемых в результате неверного предсказания тактов может быть несколько сотен. Кроме того, объем аппаратных средств, используемых для устранения последствий неправильных предсказаний, достаточно велик и может негативно влиять на повышение тактовой частоты микропроцессора.
Изменение порядка следования команд имеет целью загрузить работой простаивающие функциональные устройства при выхватывании из потока тех команд, для которых имеются готовые операнды и свободные устройства для их исполнения. Однако при этом должны исследоваться зависимости между командами по регистровым и другим используемым ресурсам. Определение отсутствия зависимости должно делаться быстро, т. к. иначе теряется смысл изменения порядка выполнения команд.
Для оптимизации исполняемого программного кода может быть применена кэш-память трасс [13]. Эта память отображает команды, выбираемые из кэш-памяти команд микропроцессора, в физически непрерывную область памяти команд. Поток команд, заполняющих кэш-память трасс, подвергается оптимизации с целью повышения эффективности исполнения уже выполненной трассы команд при повторных ее выборках. Трасса оптимизируется на фойе исполнения ее команд процессором.
Для уменьшения потерь процессорных тактов, связанных с промахами при обращении к кэш-памяти в случае выполнения команд ветвления, в состав системы кэширования вводятся средства предсказания переходов, основное назначение которых – повысить вероятность наличия в кэш-памяти требуемой команды.
Исполнение условных переходов состоит из следующих этапов:
ü распознавание команды условного перехода;
ü проверка выполнения условия перехода;
ü вычисление адреса перехода;
ü передача управления в случае перехода.
На каждом этапе используются специальные приемы повышения производительности.
Этап 1. Для быстрого декодирования используются либо дополнительные биты в поле команды, либо преддекодирование команд при выборе из кэш-памяти команд.
Этап 2. Часто, когда команда уже выбрана из кэш-памяти, условие перехода еще не вычислено. Чтобы не задерживать поток команд, в данном случае используется предсказание перехода по одной из нескольких возможных схем. Некоторые предсказатели используют статическую информацию из двоичного кода программы или специально выработанную компилятором. Например, определенные коды операций чаще вырабатывают ветвление, чем другие коды, или ветвление более вероятно (при организации циклов), или компилятор может устанавливать флаг, указывающий направления перехода. Может также использоваться статистическая информация, полученная при трассировке программы.
Другие предсказатели используют динамически формируемую информацию в процессе исполнения программы. Обычно это информация, касающаяся истории выполнения данного ветвления, сохраняемая в таблице ветвлений или в таблице предсказаний ветвлений. Таблица предсказания ветвлений организуется по ассоциативному принципу, подобно кэш-памяти, ее элементы доступны по адресу команды, ветвление которой предсказывается. В некоторых реализациях элемент таблицы предсказания ветвления является счетчиком, значение которого увеличивается при правильном предсказании и уменьшается при неправильном. При этом значение счетчика определяет преобладающее направление ветвлений.
В момент определения действительного значения условия ветвления вносится изменение в историю ветвления. Если предсказание было неверным, то должна инициироваться выборка правильных команд. Результаты команд, которые были условно выполнены, должны быть аннулированы.
Этап 3. Для определения адреса ветвления обычно требуется выполнить целочисленное сложение, прибавляющее к текущему значению счетчика команд смещение, заданное в поле команды ветвления. И хотя это не требует дополнительных тактов для обращения к регистрам, ускорение вычисления адреса может быть достигнуто благодаря использованию буфера, содержащего ранее использованные адреса переходов.
Условное выполнение команд в VLIW-процессорах
Альтернатива суперскалярной обработке – длинное командное слово (VLIW-Very Long Instruction Word). Использование этого метода предполагает задание в командном слове совокупности параллельно выполняемых команд. Подготовкой таких программ занимается компилятор.
В рамках архитектуры IA-64 [15], разрабатываемой Intel и HP, организация длинных команд базируется на связках (bundle) команд, формируемых из трех команд и специального поля шаблона (template).
Возможные варианты связки из трех команд:
ü i1||i2||i3 – все команды i1, i2, i3 исполняются параллельно;
ü i1 & i2 || i3 – сначала команда i1, затем исполняются параллельно i2 и i3;
ü i1 || i2 & i3 – параллельно исполняются i1 и i2, после них команда i3;
ü i1 & i2 & i3 – последовательно исполняются команды i1, i2, i3.
Поле шаблона используется для управления исполнением команд связки и организации суперсвязок, формируемых из нескольких соседних связок. Шаблон указывает, какие команды связки или соседних связок могут исполняться параллельно на разных функциональных устройствах. Например, на рис. 1.18 представлена суперсвязка из восьми целочисленных команд.
| Связка команд №1 | Связка команд №2 | Связка команд №3 | |||||||||||
| т | Int 1 | Int 2 | Int 3 | т | Int 4 | Int 5 | Int 6 | т | Int 7 | Int 8 | Int 9 | ||

| |||||||||||||
| Суперсвязка из восьми команд целочисленной обработки, которые могут параллельно исполняться на разных целочисленных АЛУ | |||||||||||||
| Рис. 1.18. Суперсвязка команд | |||||||||||||
Шаблон связки создается при компиляции программы, и в него помешается вся информация по управлению параллельным выполнением команд. При этом в зависимости от числа требуемых функциональных устройств все восемь команд могут исполниться либо за один такт параллельно, либо за два такта по четыре команды за такт, либо как-то иначе.
Формат команды IA-64 включает: код команды, три 7-разрядных поля операндов, 1 приемник и 2 источника (операндами могут быть только регистры), особые поля для арифметических операций с плавающей и фиксированной точками, а также специальное 6-разрядное предикатное поле.
Эффективность загрузки функциональных устройств в процессорах с длинным или очень длинным командным словом (LIW/VLIW- long/very long instruction word) достигается за счет механизма условного (предикативного) исполнения команд и предвыборки команд.
Механизм условного исполнения команд базируется на введении в команды специального предикатного поля. Условное выполнение команд исключает необходимость использования команд условных переходов. Вместо команды перехода и двух альтернативных ветвей, одна из которых выполняется в зависимости от значения предиката команды перехода, отдельной специальной командой вычисляется тот же предикат, что и в команде перехода, и его значение сохраняется в специальном предикатном регистре. Команды одной альтернативной ветви используют значение U вычисленного предиката, а команды другой альтернативной ветви используют предикат со значением "не U". Команды обеих ветвей запускаются на исполнение, но результативное исполнение будет только у команд со значением предиката "истина". Подобные действия по замене команд перехода на команды условного выполнения носят название "преобразование if" [14] и выполняются компилятором.
Использование условных команд упрощает загрузку функциональных устройств микропроцессора, перенося проблемы формирования условных команд на стадию компиляции программ. Однако эффективная поддержка условного выполнения команд требует обеспечения следующих механизмов:
ü введения специального поля команды для указания предикатного операнда;
ü введения предикатного регистрового файла;
ü исключения результатов команд со значением предикатного операнда «ложь»;
ü выделения множества условных команд.
Одним из приемов борьбы с удлинением командного слова служит ограничение типов команд, допускающих условное исполнение только теми командами, форматы которых имеют поля для размещения предиката. Например, допускается условное исполнение только команд пересылки MOV. Для этого вводится специальный формат CMOV условной пересылки.
В разной степени условные команды используются в таких микропроцессорах, как Alpha, Advanced RISC Machines ARM, Philips TriMedia, MIPS R x000, Sun SPARC, TMS 320 С6хх и в архитектуре х86. Intel ввела команду CMOV в свои микропроцессоры Pentium Pro и Pentium II в 1995 году. Эти команды появились в микропроцессорах Sun SPARC, DEC Alpha, R x000 в 1991, 1992, 1995 годах соответственно [15].
Современные процессоры используют условные команды с различными ограничениями. Так, одни ограничиваются только условными пересылками. Другой подход реализован в микропроцессоре ARM: все команды условные и могут использовать 16 предикатов, однако не допускается вложенных предикатов условных команд.
В качестве предикатных регистров могут использоваться как специально выделенные для этого регистры, так и регистры общего назначения. В последнем случае, вообще говоря, может возникнуть проблема недостатка регистров. Кроме того, значения предикатных регистров должны считываться наряду с другими операндами программы, что ведет к увеличению числа портов регистрового файла. Поэтому введение отдельного предикатного файла вполне оправдано.
Конечно, предпочтительным использованием условных команд служит распараллеливание коротких альтернативных ветвей.
При выполнении циклов, организованных с применением команды перехода с заранее известной передачей управления на начальную команду, с заданным большим числом повторений (например, порядка тысячи) команд тела цикла могут без потери эффективности использоваться традиционные команды перехода. Кроме того, команды перехода необходимы для выполнения редко используемых блоков программного кода, связанных, например, с обработкой исключительных ситуаций.
Введение условных команд требует оборудования для задания предикатов и работы с ними. Но в условиях относительного избытка обрабатывающих устройств, которые все равно нет возможности загрузить непосредственно вычислениями, использование этих устройств для вычисления предикатов служит общему повышению производительности микропроцессора.
Использование условных команд вводит в микропроцессоры элементы ассоциативной обработки данных, что, вообще говоря, при развитии логики работы с предикатами может существенно повлиять на стиль разработки и исполнения программ.
В рамках архитектуры NArch, разработанной в Московском центре "СПАРК-технологий" [16-18], предлагается [18] использовать условные команды и аппаратную поддержку их исполнения. Предусматриваются специальный файл предикатных регистров и специальное функциональное устройство, позволяющее в одном такте вычислять до трех предикатов. В.совокупности с предикатами, вычисляемыми в арифметических устройствах процессора, общее число вычисляемых за один такт предикатов может достигать шести.
Декодирование команд, переименование ресурсов и диспетчеризация
Независимо от того, выбраны команды на исполнение в суперскалярном микропроцессоре или микропроцессоре с длинным командным словом, далее происходит их декодирование и подготовка ресурсов для их исполнения. На этой фазе определяются существенные зависимости (RAW) по данным между командами и преодолеваются несущественные (WAW, WAR), производится распределение команд по буферам команд функциональных устройств.
При декодировании команды создается одна или несколько упорядоченных троек, каждая из которых включает:
ü исполняемую операцию;
ü указатели на операнды;
ü указатель на место помещения результата.
Для преодоления лишних WAR- и WAW-зависимостей, возникающих в результате ограниченности логических ресурсов (ячеек памяти, регистров), используется механизм динамического отображения определяемых текстом программы логических ресурсов на физические ресурсы микропроцессора. При данном подходе с одним логическим ресурсом может быть связано несколько значений в различных физических ресурсах, каждое из которых соответствует значению логической величины в один из моментов времени последовательного выполнения программы.
Когда команда создает новое значение для логического регистра, физический ресурс, в который помещается это значение, получает имя. Последующие команды, использующие это значение, снабжаются именем физического ресурса. Данная процедура называется "переименованием регистров". Используются два основных способа переименования.
В первом физический файл регистров больше логического. При необходимости переименования из списка свободных физических регистров берется один, и ему сопоставляется соответствующее логическое имя. Если список свободных регистров пуст, диспетчеризация команд приостанавливается до момента появления свободных физических регистров.
Рассмотрим пример реализации данного способа переименования. Пусть требуется выполнить команду sub r3, r3, 5 (из значения регистра r3 вычесть константу 5 и поместить результат в регистр r3). Логические имена регистров начинаются со строчной буквы, а физические – с прописной. Пусть также в момент исполнения команды в таблице регистру r3 соответствует R1. Первым регистром в списке свободных пусть является R2. Поэтому в поле результата команды sub r3, r3, 5 регистр r3 заменяется на R2. Исполнимая команда приобретает вид sub R2, R1, 5. Любая следующая за sub команда, использующая ее результат, должна использовать в качестве операнда R2.
Остается вопрос о возвращении физических регистров в список свободных после того, как из них считаны данные в последний раз. Один из способов связывает счетчик с каждым физическим регистром. Счетчик увеличивается при каждом переименовании операнда в командах, использующих этот физический регистр. Соответственно, при использовании операнда значение счетчика уменьшается на 1. При достижении счетчиком нуля физический ресурс должен быть переведен в список свободных.
Второй способ переименования использует одинаковое число логических и физических регистров и поддерживает их однозначное соответствие. В дополнение имеется буфер с одним вхождением для каждой инициированной на исполнение команды. Этот буфер называется "переупорядочивающим", т. к. он используется также для установления порядка команд при прерываниях. Данный буфер можно рассматривать как FIFO-очередь, выполненную в виде кольцевого буфера с указателями "начало" и "конец".
Команды помещаются в конец буфера. По завершении команды ее результат заносится в заранее предписанный ей элемент очереди, независимо от места в очереди, занимаемого этим элементом. К моменту достижения командой начала буфера, если она была исполнена, ее результат помещается в регистровый файл, а сама команда удаляется. Команда, находящаяся в буфере и не исполненная в виду отсутствия значения операнда, остается в нем вплоть до получения этого значения. Одновременно может выбираться из очереди или помещаться в нее несколько команд, однако всегда соблюдается дисциплина FIFO.
Значение логического регистра может быть размещено либо в физическом регистре, либо в переупорядочивающем буфере. В момент декодирования команды значению ее результата сопоставляется соответствующая результату позиция упорядоченной тройки команды в элементе переупорядочивающего буфера, в котором размещается рассматриваемая декодированная команда, и делается отметка в таблице соответствия значений, которая указывает, что значение результата может быть найдено в соответствующем элементе буфера. Поля источников и результата команды используются для доступа к полям таблицы. Таблица показывает, что соответствующий регистр содержит требуемую величину, либо она может быть найдена в переупорядочивающем буфере. Когда переупорядочивающий буфер полон, диспетчеризация команд приостанавливается.
Рассмотрим выполнение переименования на примере команды sub r3, r3, 5. Пусть значение r3 находится или будет находиться в переупорядочивающем буфере в элементе 6. Регистр r3 как источник заменяется на соответствующее поле результата элемента 6 буфера. Команда sub помещается в конец переупорядочивающего буфера, например в элемент 7. Этот номер затем записывается в таблицу для использования командами – потребителями результата. Следует заметить, что переупорядочивающий буфер фактически вводит потоковую модель вычислений по готовности операндов.
Независимо от способа переименования, в суперскалярном процессоре устраняются лишние зависимости поданным.
Проблемы конфликтов при доступе к разделяемому ресурсу – ячейкам памяти, по сути, те же, что и при доступе к регистрам.
Для вычисления адреса памяти, как правило, требуется, по крайней мере, одно сложение. После вычисления адреса может понадобиться его преобразование в физический адрес, осуществляемое буфером истории трансляции адресов (TLB).
Исполнение команд
После формирования для каждой команды упорядоченных троек, состоящих из кода операции, физических операндов-источников и физического операнда-результата, а также размещения их в буферах, наступает фаза динамической проверки готовности значений операндов для исполнения команды.
В идеале команда готова к исполнению, как только готовы ее входные операнды. Однако есть ряд ограничений, связанных с доступностью физических ресурсов, таких как исполнительные устройства, коммутаторы и порты регистровых файлов (или переупорядочивающего буфера). Для организации окна исполнения используются различные методы: одной очереди, многих очередей или метод резервирующей станции.
Если имеется одна очередь, то переименование регистров не требуется, т. к. доступность значений операндов может отмечаться битом резервирования, сопоставленным каждому регистру. Регистр резервируется, когда модифицирующая его команда назначается на исполнение. И регистр освобождается, когда закапчивается исполнение команды. Если для команды ресурсы не были зарезервированы, то она приостанавливает свое исполнение.
В методе многих очередей каждая очередь организуется для команд одного типа. Например, очередь команд с плавающей точкой или очередь команд работы с памятью.
Третий метод предполагает использование резервирующей станции, состоящей из совокупности элементов, каждый из которых содержит позиции для размещения кода операции, наименования первого операнда, самого первого операнда, признака доступности первого операнда, наименования второго операнда, самого второго операнда, признака доступности второго операнда и наименования регистра результата. Когда команда завершает исполнение и вырабатывает результат, то наименование результата сравнивается с наименованиями операндов в резервирующей станции.
Если в резервирующей станции обнаруживается команда, ждущая этого результата, то данные записываются в соответствующую позицию и устанавливается признак их доступности. Когда у команды доступны все операнды, инициируется ее исполнение. Резервирующая станция следит за доступностью операндов. Когда команда при диспетчеризации попадает в резервирующую станцию, все готовые операнды из регистрового файла переписываются в поля этой команды. Когда все операнды готовы, команда исполняется. Иногда резервирующая станция содержит не сами операнды, а указатели на них 0 регистровом файле или в переупорядочивающем буфере.
Резервирующая станция представляет собой как бы процессор, управляемый потоком данных.
Завершение выполнения команды
Завершающей фазой исполнения команды является фаза изменения состояния процессора в соответствии с выполненной командой. Назначение этой фазы – сохранение последовательной модели исполнения программы при реальном параллельном выполнении отдельных команд и условном выполнении команд ветвления.
Для изменения состояния процессора применяются два основных способа, причем оба основаны на использовании двух состояний: состояния, измененного в результате операции, и состояния, требуемого для восстановления.
При первом способе сохраняется состояние процессора в наборе контрольных точек или в буфере истории вычислений, которые в случае необходимости используются для восстановления состояния.
Второй способ предполагает рассмотрение логического (архитектурного) и физического состояния процессора. Физическое состояние изменяется немедленно по завершении очередной команды. Архитектурное состояние изменяется тогда, когда ясен результат условно выполненных команд. Для реализации этого способа используется переупорядочивающий буфер: результаты из буфера отправляются в файл архитектурных регистров и в память.
В переупорядочивающем буфере для каждой команды содержится соответствующее ей значение счетчика команд и значения других регистров, которые необходимы для корректного обслуживания прерываний.
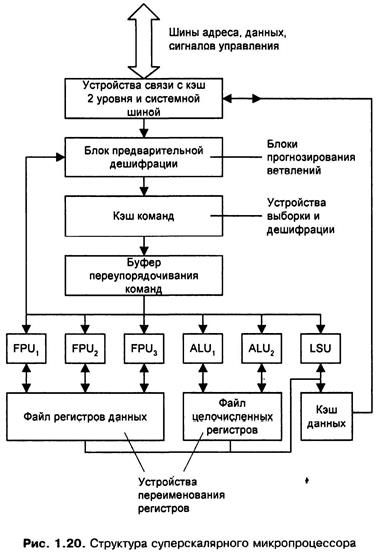
На рис. 1.20 показаны основные компоненты суперскалярного микропроцессора: функциональные модули: выполнения операций с плавающей (FPU) и фиксированной (ALU) точкой, устройство загрузки/сохранения, файлы регистров, раздельная кэш-память команд и данных, а также вспомогательные модули, обеспечивающие динамическое планирование вычислительного процесса, устройство связи с кэш-памятью второго уровня, блок переупорядочивания команд и блок предварительной дешифрации.
Направления развития архитектуры процессоров с параллелизмом уровня команд
Как уже отмечалось, в суперскалярных процессорах предпринимается попытка в рамках модели последовательных программ реализовать параллельное исполнение команд этих программ. После извлечения последовательного потока команд между командами устанавливаются только действительно необходимые зависимости по данным. При этом сохраняется достаточно информации о порядке следования команд в исходной программе, чтобы сохранить их порядок при наступлении прерывания.
Типичный суперскалярный процессор выбирает команды и исследует их по мере выполнения. Исследование проводится с целью выявления и обработки команд перехода, идентификации типа команды для ее дальнейшего направления на соответствующий исполнительный блок или в буфер памяти. Выполняются также некоторые действия для смягчения зависимостей по данным, например, переименование регистров. VLIW-процессор возлагает на компилятор статическую реализацию тех функций, которые в суперскалярном процессоре выполняются динамически.
По крайней мере, два обстоятельства ограничивают эффективность использования суперскалярных архитектур. Во-первых, есть ограничения на степень параллелизма на уровне команд, даже если применяется самая совершенная техника суперскалярных вычислений. Во-вторых, сложность суперскалярного процессора возрастает, как количество параллельно исполняемых команд, и даже быстрее.
Природа этих ограничений состоит в том, что в программах существуют условные переходы, при условном выполнении которых, в случае их вложенности, резко возрастают требования к ресурсам, что ограничивает количество исполняемых команд. Кроме того, размер окна исполнения (число активных команд, которые могут исполняться параллельно) ограничивает присущий программе параллелизм, т. к. не рассматривается параллельное исполнение команд, находящихся на расстоянии, превышающем размер окна.
Вероятнее всего, что пределом распараллеливания при суперскалярной обработке является запуск одновременно на исполнение в каждом такте 7- 8 команд.
Альтернатива суперскалярной обработке – длинное командное слово (VLIW). Достоинства WLIW заключаются в следующем. Во-первых, компилятор может более эффективно исследовать зависимости между командами и выбирать параллельно исполняемые команды, чем это делает аппаратура суперскалярного процессора, ограниченная размером окна исполнения.
Во-вторых, VLIW-процессор имеет более простое устройство управления и потенциально может иметь более высокую тактовую частоту.
Однако у VLIW-процессоров есть серьезный фактор, снижающий их производительность. Это команды ветвления, зависящие от данных, значения которых становятся известны только в динамике вычислений. Окно исполнения VLIW-процессора не может быть очень большим ввиду отсутствия у компилятора информации о зависимостях формируемых динамически, в процессе выполнения. Этот недостаток препятствует возможности переупорядочивания операций в VLIW-процессоре. Например, статически не может быть гарантировано правильное выполнение операции загрузки в вызываемой функции параллельно с операцией запоминания в вызывающей функции (особенно, если вызываемая функция определена динамически). Кроме того, VLIW-реализация требует большого размера памяти имен, многовходовых регистровых файлов, большого числа перекрестных связей. Возможен также останов, когда во время выполнения возникла ситуация, отличающаяся от состояния в момент генерации плана выполнения (например, во время выполнения произошло неудачное обращение в кэш).
Суперскалярные микропроцессоры и процессоры с длинным командным словом являются современными продуктами микроэлектроники, и их производительность постоянно растет, но при использовании этих процессоров необходимо тщательно исследовать архитектурные приемы получения высокой производительности и проверять адекватность этих приемов проблемной области, для решения задач которой создается вычислительная система.
Дальнейшее повышение производительности микропроцессоров связывается в настоящее время со статическим и динамическим анализом кода с целью выявления параллелизма уровня программных 
 сегментов с использованием информации, прёдоставляемой компилятором языка высокого уровня. Исследования в данном направлении привели к разработке мультитредовой архитектуры процессоров, которые являются дальнейшим развитием суперскалярной архитектуры.
сегментов с использованием информации, прёдоставляемой компилятором языка высокого уровня. Исследования в данном направлении привели к разработке мультитредовой архитектуры процессоров, которые являются дальнейшим развитием суперскалярной архитектуры.
В настоящее время работы в данном направлении находится на стадии теоретического исследования и имитационного моделирования. Однако уже появился первый мультитредовый микропроцессор фирмы Intel. Процессоры, в полной мере использующие все преимущества, предоставляемые мультитредовой архитектурой, разрабатываются фирмами IBM и SUN. Поэтому основные моменты, связанные с дайной архитектурой, будут рассмотрены достаточно подробно в разд. 1.4.
Другим возможным подходом служит. Переход к мультипроцессорному исполнению на однокристальных вычислительных системах. В этом случае речь идет о распараллеливающих компиляторах с языков высокого уровня.
|
|
|
|
|
Дата добавления: 2015-06-25; Просмотров: 2242; Нарушение авторских прав?; Мы поможем в написании вашей работы!