КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Понятие о методе максимального правдоподобия
|
|
|
|
Метод максимального правдоподобия позволяет получать математические модели, характеризующие существенные свойства изучаемых процессов в виде функции правдоподобия (1.8) с оценкой параметра h по результатам экспериментальных измерений показателя Y.
Для этого необходимо:
* Априори установить характер закона распределения значений величины Y.
* Спланировать эксперимент и провести n опытов, в результате которых должна быть получена выборка y1,..., yn значений случайной величины Y.
* Определить функцию правдоподобия l{h/ y1,..., yn } и оценить параметр h (в общем случае может быть множество параметров q1,..., qm).
* На основании полученной оценки h^, или (q1^,..., qm^) сделать выводы относительно исследуемого показателя Y.
Пример 1. Предположим, что каждый из m стрелявших из пистолета произвел n выстрелов, стреляя по отдельной мишени. Затем наугад выбрана одна из мишеней. При этом в ней было обнаружено r попаданий. О каждом стрелке нам известно, что он способен попасть в мишень при одном выстреле с вероятностью
pj , jÎ {1,...,m}.
Необходимо сделать правдоподобное предположение о том, кому из стрелявших вероятнее всего принадлежит выбранная мишень. Очевидно в качестве показателя Y, характеризующего процесс попадания в мишень одним стрелявшим с номером j при n выстрелах, может быть вероятность Pj(rn) попасть r раз в мишень для j-го стрелка при n выстрелах. Эта вероятность, как известно, распределена по закону Бернулли:
P(r,n, pj) = Crn prj(1-pj)n-r. (1.9)
Параметр p^j, максимизирующий вероятность P(r, n, pj), позволяет сделать вывод о том, что выбранная мишень с r пробоинами с наибольшей вероятностью принадлежит стрелявшему под номером j, который имеет способность (вероятность) pj попадать в мишень при одном выстреле наиболее близкую к оценке p^j. Для оценки p^j составляем функцию правдоподобия
|
|
|
l{pj, r, n}=prj(1-pj)n-r. Данная функция достигает максимума при p^j = r/n [15]. Следовательно, наиболее вероятно, что выбранная мишень принадлежит стрелявшему под номером j, соответствующему оценке p^j=r/n.
Пример 2. Предположим, что задача состоит в том, чтобы оценить вес некоторого предмета посредством взвешивания его на n различных весах приблизительно одинаковой точности. В результате получается выборка у1, y2,..., yn значений оцениваемого показателя Y, характеризующего вес данного предмета. Y является случайной величиной, распределенной по нормальному закону:
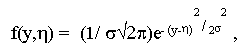 (1.10)
(1.10)
где h - математическое ожидание величины Y, а s2 - дисперсия этой величины. Так как по определению s2 характеризует разброс значений yi относительно математического ожидания h, то величина s2 не влияет на положение максимума параметра h. Поэтому для упрощения вычислений можно положить s2 = 1. Тогда выражение (1.10) приобретает вид:
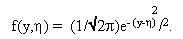
Отсюда формула правдоподобия параметра h имеет вид:
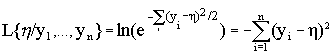 (1.11)
(1.11)
(При определении функции правдоподобия постоянные коэффициенты можно опустить) Функция (1.11) достигает максимума при таком значении h, для которого сумма
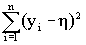 принимает минимальное значение. Этот факт был использован для разработки широко известного метода оценки параметров математической модели изучаемого процесса, называемого “ методом наименьших квадратов ”.
принимает минимальное значение. Этот факт был использован для разработки широко известного метода оценки параметров математической модели изучаемого процесса, называемого “ методом наименьших квадратов ”.
При исследовании сложных систем показатель Y изучаемого свойства может быть функцией от многих факторов x1,..., xn и представлять собой случайную функцию Y = f(x1,..., xn, q1,..., qm). Задача исследователя состоит в том, чтобы с помощью эксперимента определить такую функцию h(X, Q) c параметрами q1,..., qm, которая с наибольшей вероятностью соответствует реальной функции Y. Согласно принципу максимального правдоподобия полагают, что функция h(X, Q) должна представлять собой множество значений {E(yi)}, где E(yi) - математическое ожидание случайной величины Y в точке Xi (Xi - набор значений факторов x1,..., xn в точке i).
|
|
|
Функция h(X, Q) обычно представляется в виде линейного относительно параметров q1,... qm полинома
h (X,Q) = q 0f0(X) + q 1f1(X) +... + q mfm(X), (1.12)
который называется уравнением регрессии случайной величины Y. В случае однофакторной функции Y ее уравнение регрессии может быть представлено в виде разложения в ряд Фурье:
h (x, Q) = q 0 1/2 + q 1 Sin (x) + q 2 Cos (x) +...,
или в виде разложение в ряд Тейлора:
h (x,Q) = q 0 + q 1x + q 2x2 +....
В данном случае функция h (х, Q) называется линией регрессии. Когда функция U является многофакторной, применяется разложение в форме полинома (1.12), где fi(x) представляет собой комбинацию из n по r факторов xiI {x1,..., xn}. В этом случае число членов в разложении полинома определяется величиной
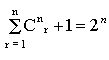 , а уравнение регрессии, представленное таким полиномом имеет следующий вид:
, а уравнение регрессии, представленное таким полиномом имеет следующий вид:
h (C, Q) = q 0(x01 x02 ... x0n) + q 1(x11 x02 ... x0n) +... + q 2n-1(x11... x1n). (1.13)
Поэтому проблема состоит еще и в том, как выбирать полином (1.12) так, чтобы трудоемкость вычислений была бы по возможности наименьшей. Эта проблема называется планированием эксперимента. Для того чтобы полиномиальное представление функции h (C, Q) было хорошо обозримым и удобным для вычислений, введем следующие обозначения:
XKj = (x1a 1,..., xna n)j,
где a eI {0, 1}=Ae, e = 1,...,n, (a 1,...,a n)j= KjI {A1? ...? An}. Другими словами, Kj - есть двоичное число от (01, 02,..., 0n) до (11,12,..., 1n). В силу данных обозначений XKj представляет (обозначает) вполне определенную комбинацию переменных x1,..., xn, например, при Kj = (11, 02,..., 0n) XKj= x1, при Kj = (11, 12, 03,..., 0n) XKj = x1 x2 , и так далее. При этом полином (1.13) может быть записан в следующем виде:
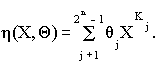 Данное представление позволяет включать в полином только некоторое ограниченное количество членов, обеспечивающее заданную точность. Это может быть использовано для построения эффективных алгоритмов планирования экспериментов и вычисления параметров q 0,...,q n. Если случайная величина Y распределена по нормальному закону, то имеет место следующее уравнение:
Данное представление позволяет включать в полином только некоторое ограниченное количество членов, обеспечивающее заданную точность. Это может быть использовано для построения эффективных алгоритмов планирования экспериментов и вычисления параметров q 0,...,q n. Если случайная величина Y распределена по нормальному закону, то имеет место следующее уравнение:
 из которого логарифмическая функция правдоподобия выборки y1,..., ys случайной величины Y получается в виде:
из которого логарифмическая функция правдоподобия выборки y1,..., ys случайной величины Y получается в виде:
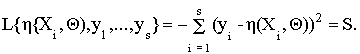
Чтобы найти значения функции h (C i, Q ) , максимизирующие данную функцию правдоподобия в точках Xi, необходимо решить систему следующих дифференциальных уравнений:
|
|
|
¶ L{h (C 1, Q ) , y1,..., ys} / ¶ q j = 0, j = 1,...,m.
В общем случае эта система имеет следующий вид:
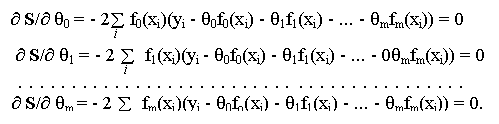 (1.14)
(1.14)
В результате решения данной системы линейных уравнений получают множество оценок q ^0, q ^1,..., q ^m параметров q 0, q 1,..., q m искомой функции h (C i, Q ) . Для решения этой системы обычно применяют матричную алгебру. Система уравнений (1.14) может быть получена и другим способом. Данный способ основан на предположении, что каждое значение yi получается из опыта с некоторой погрешностью x i. При этом имеет место система уравнений
x i = yi - h (C i, Q ) , i = 1,...,s.
Степень приближения функции h (C i, Q ) к экспериментальным данным
оценивается величиной дисперсии 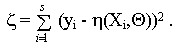
Таким образом, приходят к соотношению | S| = z, показывающему, что оценки параметров q j логарифмической функции правдоподобия S и дисперсии z имеют одинаковые значения в точке экстремума. Заметим, что данный способ не предполагает никаких ограничений на вид распределения случайной величины Y. Поэтому можно считать, что функция S (z) годится для оценки параметров функции регрессии h (C i,Q) случайной величины Y при любом законе ее распределения.
|
|
|
|
|
Дата добавления: 2015-06-04; Просмотров: 622; Нарушение авторских прав?; Мы поможем в написании вашей работы!