КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Микропроцессоры фирмы AMD 1 страница
|
|
|
|
Запись в память никогда не выполняется опережающим образом, так как нет эффективного способа организации отката в случае неверного предсказания. Разные команды записи никогда не переупорядочиваются друг относительно друга. Буфер записи инициирует запись, только когда сформированы и адрес, и данные, и нет ожидающих выполнения более ранних команд записи.
Управление производительностью – особенность Р5, позволяющая разработчикам систем и прикладных программ оптимизировать свои аппаратные и программные средства посредством определения потенциально узких мест при исполнении программного кода, а разработчики могут наблюдать и считать такты для внутренних событий процессора, таких, как производительность чтения и записи данных, кэширование совпадений и выпадений, прерываний и использования шины. Это позволяет им выполнять тонкую настройку своих приложений или систем для достижения оптимальной производительности.
Использование блока адреса ветвления минимизирует простои в одной или обеих секциях, вызванных задержками выборки команд при “нелинейном” изменении программного адреса, вызванном, например, переходом от одного участка программы к другому или от текущей программы к подпрограмме обработки прерывания. Основное назначение блока - предвидеть возможные “нелинейные” переходы. Если такой переход должен произойти в ближайшем будущем, программные инструкции из соответствующей ячейки памяти заранее считываются в буфер адреса ветвления, что приводит к увеличению быстродействия работы МП.
Кэш-память может работать как в режиме сквозной записи (при которой кэшируются только операции считывания), так и в двунаправленном (с обратной записью) режиме. Кэш-память P5 может также хранить информацию, которая должна быть записана в память, до того момента, когда снизится нагрузка на МП и на другие компоненты системы.
|
|
|
Блоки программной и данных кэш-памяти организованы по двухстраничной схеме, каждая страница разделена на строки по 32 байта. Для каждого блока кэш-памяти предусмотрен специальный ассоциативный буфер преобразования (TLB), задачей которого является преобразование линейных адресов в физические адреса памяти.
В двунаправленном режиме записи осуществляется кэширование не только результатов операций считывания, но и записи, что повышает производительность процессора по сравнению с режимом сквозной записи. В двунаправленном режиме значительно уменьшается количество обменов данными между МП и системной памятью, которые в быстродействующих системах являются самым медленным процессом. Необходимо отметить, что программный кэш построен с защитой от записи в него данных, полученных в процессоре. Благодаря использованию укороченных циклов памяти данные в кэш-памяти или из него могут быть переданы очень быстро.
Все эти особенности построения МП потребовали использования 64 - разрядной внутренней шины данных, которая обеспечивает возможность двойного кэширования и суперскалярной конвейерной обработки одновременно с загрузкой следующих к исполнению данных.
Кэш-память данных имеет два 64 - разрядных интерфейса, по одному для каждого из конвейеров, что позволяет ей обеспечивать данными две отдельно исполняемые инструкции в течение одного машинного цикла. После того, как данные достаются из кэш-памяти, они записываются в основную память в режиме обратной записи. Такая техника кэширования дает лучшую производительность, чем простое кэширование с непосредственной записью, при котором процессор записывает данные одновременно в кэш и основную память. Тем не менее, Р5 способен динамически конфигурироваться для поддержки кэширования с непосредственной записью.
|
|
|
Рекомендуемый объем общей кэш - памяти для настольных систем, основанных на Р5, равен 128 - 256 КБайт, а для серверов - 256 КБайт и выше.
Блок адреса ветвления - это следующее новое решение для вычислений, увеличивающее производительность посредством полного заполнения конвейеров командами. Известно, что для процессоров 8086 команды переходов встречаются через каждые 6-7 команд. При обнаружении перехода устройство выборки команд должно выбирать инструкции с адреса перехода. Если переход безусловный, то проблем нет - адрес перехода определен однозначно. Проблема возникает в том случае, когда переход определяется каким-либо условием. Например, если содержимое одного из регистров окажется равным нулю, то осуществить переход по такому-то адресу, в противном случае выполнять команду, следующую за текущей командой.
Поскольку к моменту, когда процессор должен начать выборку идущей за точкой перехода команды, условие перехода еще не определено, процессор должен сделать предположение о том, будет или не будет совершен переход. После этого начнется выборка команд соответственно с точки перехода или с команды, следующей за текущий. Если переход спрогнозирован верно, то работа конвейера не прервется. В противном случае с конвейера придется удалять команды, относящиеся к неправильно предсказанному направлению ветвления программы, и перезагружать его.
Поэтому безошибочное прогнозирование переходов является одним из путей повышения производительности конвейерных систем. Для этого существует буфер адреса переходов на 256 позиций. В нем хранится информация о результатах последних 256 ветвлений. Эта информация обрабатывается в соответствии с алгоритмом, и на основании результата обработки делается предположение о направлении ветвления.
Высокопроизводительный блок вычислений с плавающей запятой. 32 - разрядные программные приложения включают много интенсивно вычисляющих, графически ориентированных программ, которые занимают много процессорных ресурсов на выполнение операций с плавающей запятой.
|
|
|
P5 позволяет выполнять математические вычисления на более высоком уровне, по сравнению с предыдущими моделями МП, благодаря использованию усовершенствованного встроенного блока вычислений с плавающей запятой, который включает восьмитактовый конвейер и аппаратно реализованные блоки для вычисления основных математических функций. При этом восьмитактовый конвейер обеспечивает четырехтактовые конвейерные исполнения команд с плавающей запятой с дополнительной четырехтактовой целочисленной конвейеризацией команд. Большая часть команд вычислений с плавающей запятой могут выполняться в одном целочисленном конвейере, после чего подаются в конвейер вычислений с плавающей запятой. Обычные функции вычислений с плавающей запятой, такие как сложение, умножение и деление, реализованы аппаратно.
P5 с тактовой частотой 100МГц выполняет команды вычислений с плавающей запятой в пять раз быстрее, чем 33 МГц Intel 80486 DX, в 6 раз быстрее 25 МГц Intel 80486 SX и в 2.6 раз - 66 МГц Intel 80486 DX2.
Расширенная 64 – битовая шина данных. Р5 представляет собой 32 – битовое устройство, однако внешняя шина данных к памяти, как уже отмечалось, является 64 - битовой, удваивая количество данных, передаваемых в течение одного шинного цикла.
Р5 поддерживает несколько типов шинных циклов, включая пакетный режим, в течение которого происходит ввод “порции” данных из 256 бит в кэш-память данных за один машинный цикл.
Шина данных является главной магистралью, которая передает информацию между процессором и системной памятью. Имея широкую шину данных, Р5 обеспечивает конвейеризацию шинных циклов, что способствует повышенной пропускной способности шины. Конвейеризация шинных циклов позволяет второму циклу стартовать раньше завершения выполнения первого цикла. Это дает возможность элементам памяти больше времени для декодирования адреса, что позволяет использовать более медленные и менее дорогостоящие компоненты памяти.
Ускорение процессов чтения и записи, параллелизм передачи адреса и данных, а также декодирование в течение одного цикла - все вместе позволяет улучшить пропускную способность и повышает возможности системы.
|
|
|
Мультипроцессорность. Р5 обладает мощным средством для организации мультипроцессорных систем. Мультипроцессорные приложения, исполняемые на двух или более Р5, хорошо обслуживаются посредством усовершенствованной архитектуры кристаллов, раздельным встроенным кэшированием программного кода и данных, а также наборами микросхем для управления внешней (вторичной) кэш - памятью и утонченными средствами контроля целостности данных.
Блок управления страничной памятью Р5 содержит опции поддержки традиционных размеров страниц памяти от 4 КБайт до 4 Мбайт. Эти опции позволяют производить вычисление частоты обновления (“свопинга”) страниц в комплексных графических приложениях, буферах фреймов, а также ядер операционных систем, где увеличенный размер страницы позволяет пользователям перепланировать шире первоначально громоздкие программные объекты. Управление размером страниц позволяет оптимизировать частоту обращений к медленной системной памяти и, тем самым, повысить производительность, причем это повышение существенно отражается на прикладном программном обеспечении.
Определение ошибок и функциональная избыточность. Хорошая защита данных и обеспечение их целостности посредством внутренних средств становится крайне важным в приложениях, критичным к потерям данных, формируемых при использовании клиент - серверов. Р5 содержит два усовершенствования, к которым относятся, во-первых, внутреннее определение ошибок и, во-вторых, контроль за счет функциональной избыточности.
Если между двумя процессами обработки программ в системе обнаруживаются разногласия, система извещается об ошибке. В результате происходит обнаружение более, чем 99% ошибок. Кроме того, на подложке процессора расположено устройство встроенного тестирования. Самотестирование охватывает более 70% узлов Р5 и представляет собой процедуру, обычно используемую при диагностике систем.
Другими встроенными решениями является возможность тестировать внешние соединения процессора и отладочный режим, позволяющий программному обеспечению просматривать регистры и состояние процессора.
Наращиваемость - Р5 имеет возможность легкого наращивания с использованием разработанных фирмы INTEL аппаратных средств. Это позволяет вести наращивание производительности, которая помогает поддерживать уровень продуктивности систем, основанных на архитектуре процессоров фирмы INTEL, больше, чем продолжительность жизни отдельных компонентов.
Технология наращивания делает возможным использовать преимущества большинства процессоров усовершенствованной технологии в уже существующих системах с помощью простой инсталляции средств однокристального наращивания производительности. Например, первое средство наращивания - это OverDrive процессор, разработанный для процессоров Intel486 SX и Intel486 DX, использующий технологию простого удвоения тактовой частоты, использованную при разработке микропроцессоров Intel486 DX2.
Посредством наращивания одного из этих дополнительных процессоров в сокет (разъем), расположенный возле центрального микропроцессора на большинстве материнских платах Intel486, пользователи могут увеличить общую производительность системы более, чем на 70% практически для всех программных приложений.
| Микропроцессоры Pentium Pro (Р6) | В 1995 г. был выпущен новый процессор Pentium Pro (Р6), имеющий внутреннюю |
RISC - архитектуру.
RISC - архитектура означает, что все CISC-команды, обрабатываемые процессором, сначала раскладываются на простые RISC - операции, а потом только начинают обрабатываться в вычислительных устройствах процессора. Преимуществом этой архитектуры является то, что сравнительно простые RISC-инструкции могут выполняться процессором по несколько одновременно и намного облегчают предсказание переходов, тем самым, позволяя наращивать производительность за счет большего параллелизма.
Процессор имеет 5,5 млн. транзисторов, выполненных сначала по 0,5 мкм (а затем по 0,35 мкм) технологии. Его производительность около 300 млн. оп/с на частотах до 200 МГц. Процессор имеет двойную независимую шину: внешнюю (FSB - Front Side Bus) и внутреннюю (BSB - Back Side Bus). Это предопределило его новое конструктивно-технологическое исполнение. Он выполнен в квадратном корпусе с 387 контактными выводами матричного типа, также, как и в предыдущем варианте, расположенными по всему периметру корпуса в несколько рядов (конструктив Socket 8).
В процессоре используются встроенные кэш-памяти: первого уровня L1 объемом 32 Кбайт (по 16 Кбайт на кэш-памяти команд и данных) и второго уровня (L2) объемом 256, 512 и даже 1024 Кб. Последняя по сути является расширением кэш-памяти первого уровня, располагается на отдельном кристалле и работает на полной тактовой частоте процессора.
В P6 для увеличения пропускной способности осуществлен переход к одному 12 - стадийному конвейеру. При этом параллельно может выполняться только пара команд, следующих в программе друг за другом и удовлетворяющих определенным правилам, например, отсутствие регистровых зависимостей типа "запись после чтения". Увеличение числа стадий в Р6 по сравнению с Р5 привело к уменьшению выполняемых на каждой стадии операций и, как следствие, к уменьшению практически на треть времени нахождения команды на каждой стадии. Это означает, что использование на практике P6 с тактовой частотой 100 МГц равносильно использованию P5 с тактовой частотой 133 МГц.
Организация работы ядра Р6 подразумевает использование нового подхода в его организации, устраняющего жесткую зависимость порядка выполнения команд в программе. Во всех ранее выпущенных процессорах последовательность выполнения команд в программе соответствует последовательности команд в этой программе. Новый подход связан с использованием так называемого “пула” команд и реализации таких архитектурных методов, как улучшенное предсказание переходов (почти всегда правильно определяется предстоящая последовательность команд), анализ потоков данных (определяется оптимальный порядок выполнения команд) и опережающее выполнение (предвиденная последовательность команд выполняется без простоев в оптимальном порядке). Комбинация перечисленных методов направлена на эффективность использования методов предвидения будущего поведения программы.
В процессоре традиционная фаза выполнения команды заменяется на две фазы: "диспетчирование-выполнение" и "откат". В результате команды могут начинать выполняться в произвольном порядке, который отличается от порядка их расположения в программе, но завершение их выполнения всегда соответствует исходному порядку в программе.
Ядро P6 реализовано как три независимых устройства, взаимодействующих через пул команд. Решение об организации P6 как трех независимых и взаимодействующих через пул команд устройств было принято после тщательного анализа факторов, ограничивающих производительность современных микропроцессоров. Рассмотрим в качестве примера следующий фрагмент программы, записанный на некотором условном языке:
| N/N команд | Операция |
| R1 М [R0] | |
| R2 R1 + R2 | |
| R5 R5 + 1 | |
| R6 R6 - R3 |
Где Ri – регистр процессора,
M [R0] – регистр памяти.
Предположим, что при выполнении первой команды фрагмента - загрузки из памяти М [R0] в регистр R1, оказалось, что содержимое соответствующей ячейки памяти отсутствует в кэш-памяти. При традиционном подходе процессор перейдет к выполнению команды 2 только после того, как данные из ячейки М [R0] основной памяти будут прочитаны через интерфейс шины. Все время ожидания процессор будет простаивать, так как скорость процессора во много раз больше скорости считывания информации из основной памяти.
Для согласования скоростей работы процессора и памяти используется пул команд. Его назначение заключается в том, что процессор извлекает из него ближайшие команды, следующие за командой, требующей обращения к памяти, и выполняет их до момента завершения команды, тормозящей дальнейшее выполнение программы. В приведенном выше фрагменте программы процессор не может выполнить команду 2 до завершения команды 1, так как команда 2 зависит от результатов команды 1. В то же время процессор может выполнить команды 3 и 4, независящие от результата выполнения команды 1. Такое выполнение команд называется опережающим выполнением команд.
Результаты опережающего выполнения команд 3 и 4 не могут быть сразу выведены из процессора и записаны в основную память, поскольку необходимо выполнять их в соответствии с порядком выполнения программы. Поэтому результаты опережающего выполнения команд хранятся в пуле команд и извлекаются оттуда после завершения выполнения предыдущих команд.
Таким образом, процессор выполняет команды в соответствии с их готовностью к выполнению, вне зависимости от их первоначального порядка в программе, то есть с точки зрения реального порядка выполнения команд P6 является машиной, управляемой потоком данных. В то же время изменение состояния вычислительной системы, например запись результатов в память, производится в строгом соответствии с истинным порядком команд в программе.
Чтение из памяти данных, необходимых для исполнения команды 1, может занимать достаточно много времени. Тем временем P6 продолжает опережающее выполнение команд, следующих за командой 1, и успевает обработать, как правило, 20 - 30 команд. Среди этих 20 - 30 команд будет в среднем около пяти команд перехода, которые устройство выборки/декодирования должно правильно предсказать для того, чтобы работа устройства диспетчирования-выполнения не оказалась бесполезной.
Сравнительно небольшое количество регистров в архитектуре процессора приводит к интенсивному использованию каждого из них и, как следствие, к возникновению множества мнимых зависимостей между командами, использующими один и тот же регистр. Поэтому, чтобы исключить задержку в выполнении команд из - за мнимых зависимостей, устройство диспетчирования-выполнения работает с дублями регистров, находящимися в пуле команд (одному регистру может соответствовать несколько дублей). Реальный набор регистров контролируется устройством отката, и результаты выполнения команд отражаются на состоянии вычислительной системы только после того, как выполненная команда удаляется из пула команд в соответствии с истинным порядком команд в программе.
Таким образом, принятая в P6 технология динамического выполнения команд позволяет оптимально выполнять программы, основанные на предсказании будущих переходов, анализе потоков данных с целью выбора наилучшего порядка исполнения команд и на опережающем выполнении команд в выбранном оптимальном порядке.
Аппаратурная реализация описанного подхода осуществляется с помощью устройства, представленного на рис. 6. Оно содержит устройства выборки - декодирования, диспетчирования-выполнения, устройства отката и пула команд.
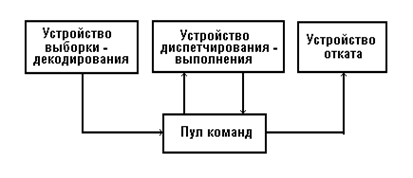
Рис. 6. Организация ядра МП Pentium Р6
Устройство выборки - декодирования выбирает команды обрабатываемой программы из программной кэш-памяти. Указателем к вводу на исполнение следующей команды является определяемый буфером переходов индекс кэш-команды, состояние процессора и сообщения о неправильном предсказании перехода, поступающих из устройства выполнения целых команд.
Буфер переходов для предсказания возможных адресов перехода при обработке программ использует специальный алгоритм, который обеспечивает более чем 90% точность предсказания переходов. Его суть заключается в том, что в кэш-памяти команд выбирается строка, соответствующая индексу в указателе на следующую команду, и следующая за ней строка, после чего передаются 16 выровненных байтов на декодирование.
Необходимость считывания двух строк объясняется тем, что команды в Р6 выровнены по границе байта, и поэтому может происходить передача управления на середину или конец строки кэш-памяти.
Три декодера устройства выборки - декодирования принимают поток информации и обрабатывают их, отыскивая и декодируя содержащиеся в потоке команды. Декодеры преобразуют команды в микрокоманды - триады (два операнда, один результат).
Большинство команд программы в устройстве выборки - декодирования преобразуются в одну микрокоманду, но некоторые команды требуют четырех микрокоманд. Более того, сложные команды требуют обращения к микрокоду, который представляет собой набор из заранее составленных последовательностей микрокоманд. Некоторые команды, так называемые “байт - префиксы”, модифицируют следующую за ними команду. Микрокоманды ставятся в очередь, посылаются в таблицу псевдонимов регистров, где ссылки на логические регистры преобразуются в ссылки на физические регистры P6, после чего каждая из микрокоманд вместе с дополнительной информацией о ее состоянии (статусе) посылается в пул команд.
P6 может запускать на выполнение до 5 микрокоманд за такт. Средняя длительно поддерживаемая пропускная способность - 3 микрокоманды за такт.
Алгоритм, отвечающий за планирование выполнения микрокоманд, является крайне важным для поддержания производительности процессора в целом. Если в каждом такте для каждого ресурса готова к выполнению только одна микрокоманда, то проблемы выбора не возникает. Но если готовых к выполнению микрокоманд несколько, то возникает проблема выбора. Для ее решения в МП используется алгоритм планирования, имитирующий модель "первый пришел - первый обслужен", предпочитающая смежное выполнение смежных микрокоманд. Поскольку в исполняемой программе может содержаться множество команд перехода, то и многие микрокоманды также будут являться переходами. Алгоритм, реализованный в буфере переходов, позволяет в большинстве случаев правильно предсказать, состоится или не состоится переход.
Для исправления случаев неверного предсказания перехода применяется следующий подход. Микрокомандам перехода еще в упорядоченной части конвейера команд ставятся в соответствие адрес следующей команды и предполагаемый адрес перехода. После вычисления адреса перехода реальная ситуация сравнивается с предсказанным адресом. Если вычисленный и предсказанный адреса совпадают, то проделанная работа оказывается полезной, так как соответствует реальному ходу программы, а микрокоманда перехода удаляется из пула команд. Если же вычисленный и предсказанный адреса не совпадают, то есть была допущена ошибка (переход был предсказан, но не произошел, или было предсказано отсутствие перехода, а в действительности он состоялся), то устройство выборки - декодирования изменяет статус всех микрокоманд, засланных в пул команд после команды перехода, чтобы убрать их из него. Правильный адрес перехода направляется в буфер переходов, который перезапускает весь конвейер с нового адреса.
Устройство диспетчирования-выполнения выбирает микрокоманды из регистров пула команд в зависимости от их статуса. Здесь под статусом понимается информация о доступности операндов микрокоманды к их обработке и наличии необходимых для ее выполнения вычислительных ресурсов, то есть операндов и свободных для их выполнения устройств процессора. Если статус микрокоманды показывает, что ее операнды уже вычислены и доступны, а необходимое для ее выполнения вычислительное устройство также доступно, то устройство диспетчирования-выполнения выбирает микрокоманду из пула команд и направляет ее на устройство для выполнения. Результаты выполнения микрокоманды возвращаются в пул.
Устройство отката проверяет статус микрокоманд в пуле команд - оно ищет микрокоманды, которые уже выполнены и могут быть удалены из пула. Именно при удалении микрокоманды результаты ее выполнения, хранящиеся в пуле команд, реально изменяют состояние вычислительной системы, например, происходит запись в регистры памяти.
Устройство отката должно не только обнаруживать завершившиеся микрокоманды, но и удалять их из пула команд таким образом, чтобы процесс вычисления происходил бы в соответствии с первоначальным порядком команд в программе. При этом оно должно учитывать и правильно обрабатывать прерывания, исключительные ситуации, неправильно предсказанные переходы и другие экстремальные случаи.
Процесс отката занимает два такта. В первом такте устройство отката считывает содержимое регистров пула команд и отыскивает готовые к удалению (откату) микрокоманды; затем оно определяет, какие из этих микрокоманд могут быть удалены из регистров пула в соответствии с исходным порядком команд в программе. Во втором такте результаты отката записываются в регистры пула команд и в регистровый файл отката.
Организация интерфейса шины. Есть два типа обращений к памяти: чтение из памяти в регистр и запись из регистра в память. При чтении из памяти должны быть заданы адрес памяти, размер блока считываемых данных и регистр-назначение. Команда чтения кодируется одной микрокомандой. При записи надо задать адрес памяти, размер блока записываемых данных и сами данные. Поэтому команда записи кодируется двумя микрокомандами: первая генерирует адрес, вторая готовит данные. Эти микрокоманды формируются независимо друг от друга и могут выполняться параллельно; они могут переупорядочиваться в буфере записи.
Организация системы памяти учитывает следующие аспекты: очередная команда записи не должна обгонять идущую впереди команду записи, так как это может лишь незначительно увеличить производительность. Можно запретить командам записи обгонять команды чтения из памяти, так как это приведет лишь к незначительной потере производительности. Запрет командам чтения обгонять другие команды чтения или команды записи может повлечь существенные потери в производительности.
С учетом сказанного была реализована архитектура системы памяти, позволяющая командам чтения опережать команды записи и другие команды чтения. Буфер упорядочения памяти служит в качестве распределительной станции и буфера переупорядочивания. В нем хранятся отложенные команды чтения и записи, и он осуществляет их повторное диспетчирование, когда блокирующее условие (зависимость по данным или недоступность ресурсов) исчезает.
| Микропроцессоры Pentium II (Klamath) | Pentium II рассчитан на использование в бытовых компьютерах, рабочих |
станциях и серверах начального уровня (с двухпроцессорной конфигурацией). Он имеет частоты 233, 266 и 300 МГц, рассчитан на работу с 66 МГц системной шиной, выполнен по 0,35 мкм технологии, на кристалле площадью 203 мм2 содержит 7,5 млн. транзисторов и, наконец, имеет кэш-памяти L1 (32 Кбайт) и L2 (512 Кбайт), причем последняя выполнена вне ядра процессора и соединена с ним высокоскоростной локальной шиной, работающей на половинной тактовой частоте процессора.
Процессор выполнен в модульном исполнении. Необходимость такого исполнения вызвана тем, что процессор, вторичная кэш-память и обслуживающие ее схемы (высокоскоростные контроллер, локальная шина и другие вспомогательные элементы) технологически расположены на одной плате, то есть представляет собой целую сборку. Для его подключения к системной плате используется разъем Slot 1 с 242 контактными выводами, которые выполнены вдоль одной из больших сторон платы.
Важной особенностью этого МП является возможность увеличения, за счет изменения значения внутреннего коэффициента умножения, частоты работы системной шины свыше 100 МГц при условии использования элементов памяти с временем выборки менее 10 нс., что позволяет значительно повысить производительность систем на его основе. Другая особенность - это пониженное напряжение питания до 2,8 В, позволяющее улучшить охлаждение процессора на повышенных частотах.
Структура МП имеет следующие особенности:
- возможность неупорядоченного выполнения команд,
- улучшенный алгоритм предсказания ветвлений,
- предварительное выполнение условного перехода, если он предсказан верно.
- синхронное исполнение нескольких команд набора ММХ.
| Микропроцессоры Pentium II (Deschutes) | Pentium II (Deschutes) является модификацией Klamath. Его отличиями |
являются:
- более высокие тактовые частоты (333,..., 450 МГц),
- возможность тактирования системной шины частотой до 100 МГц (для процессоров с тактовой частотой выше 400 МГц),
- используемая технология - 0,25 мкм,
- напряжение питания ядра - 2 В,
- использование высокоскоростного AGP (Accelerated Graphic Port) порта.
Перевод системной шины с классической частоты 66 МГц до 100 МГц хотя и привел к заметному росту производительности (порядка 35-45%), но не дал резкого скачка в быстродействии ПК. Это объясняется сильным демпфирующим влиянием кэш-памяти 2 уровня.
Наилучшего применения процессор получил при работе с DVD-проигрывателями и графикой AGP.
Процессор Deschutes выполнен, как и предыдущий, в модульном исполнении и имеет 242 – контактный разъем Slot 1.
Для обеспечения надежной работы в некоторые процессоры встроены датчики контроля температуры.
| Микропроцессоры Pentium II (Xeon) | Микропроцессоры Pentium II Xeon ориентированы на использование в серверах и |
рабочих станциях, для которых стоимость не является определяющим фактором. Они имеют практически те же конструктивно-технологические характеристики, что и предыдущие модели процессоров.
Отличительными особенностями Pentium II (Xeon) от Pentium II (Klamath) являются:
|
|
|
|
|
Дата добавления: 2015-06-04; Просмотров: 521; Нарушение авторских прав?; Мы поможем в написании вашей работы!