КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Коммуникационная среда ММПС
|
|
|
|
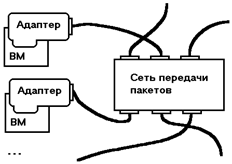
Разные виды. Составные части - адаптеры ВМ, коммутаторы и кабели.
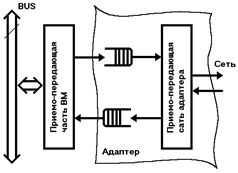
Адаптеры.
 ---------------
--------------- 
Коммутаторы.
Простые и составные. [зачем составные?]
Простые – с временным разделением (шина) и с пространственным (crossbar).
Недостатки шины - конкуренция за ресурсы – арбитраж.
Передача –
- получить доступ
- установить связь с адресатом
- определить его способность к взаимодействию
- передать данные или команду
Принимающий распознает свой адрес и выполняет запрашиваемые действия.
Арбитраж:
- статический
- динамический (обычно LRU или RDC)
- FIFO – максимальная пропускная способность, но сложен в реализации
- голосованиее [раскрыть]
- независимые запросы (как PCI).
Crossbar – любой вход с любым выходом (ординарные) или с подмножеством выходов (неординарные). Первые – минимальная задержка, но ниже надежность и сложная реализация.
Составные – из простых малого размера (например, 2х2). Задержка пропорциональна числу каскадов.
Коммутатор Клоза – m x d
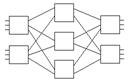
Этот – (2х3)х(2х3)
Любой вход с любым выходом. Регулярный алгоритм установления соединения.
Распределенные составные – v+1 вход и v+1 выход (v > 1). 1 вход и 1 выход каждого – это вход и выход составного.
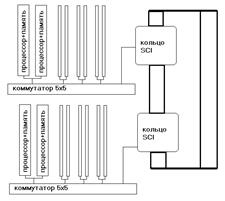
Обычно при нескольких десятках процессоров – полный, между такими блоками – сеть.
Пример – Convex Exemplar:
Классификация сетей: по топологии, динамические/статические, по алгоритмам маршрутизации.
Топология. Графы. Виды: полный (1 узел – N-1, все – N*(N-1)), k-мерная решетка ширины w (w^k узлов, 2*k связей у внутренних узлов), k-мерная решетка с замыканием (тор, все узлы степени 2*k), кольца, кольца с хордами, гиперкуб (2^k узлов в виде k-мерного гиперкуба
Предпочтительно – полный.
|
|
|
Терминология. Расстояние – количество ребер кратчайшего пути между 2-мя вершинами. Диаметр – расстояние между максимально удаленными вершинами. Средний диаметр – математическое ожидание расстояния при равновероятном выборе пар вершин.
Ширина бисекции (максимальное количество сообщений, которое можно отправить одновременно от одних p/2 процессоров к другим p/2.
Шина – простая и наиболее дешевая динамическая сеть. Диаметр – 1, бисекция – 1.
Кроссбар – наиб дорогая. Все ко всем, p^2 переключателей. Диаметр – 1, бисекция – p/2.
Челнок – соединяет p=2^m процессоров с другими p процессорами. Каждый процессор имеет m-бит адрес. Процессор с адресом b0b1b2…bm cоединяется с процессором b1b2…bm b0. Омега-сеть состоит из m челноков, соединенных переключателями. Каждый переключатель соединяет соседние пары проводов между 2 челноками. Перекл i выполняет переключение так: если бит i в адресах источника и приемника равны – то по 1 проводу, иначе – по 2-му.
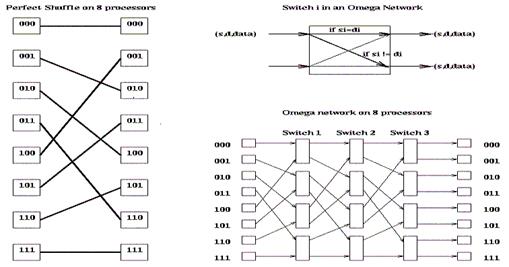 |
Используется в IBM RP3, BBN Butterfly и NYU Ultracomputer (разновидность – в IBM SP2).
Решетки. Диаметр d-мерной решетки - d*p^(1/d), бисекция - p^((d-1)/d).
Торы – Intel Paragon – 2D тор, Cray T3D – 3D тор (отсюда название). Диаметр -, бисекция -.
Деревья. Состоит из процессоров либо во всех узлах, либо в листьях (тогда во внутренних узлах – маршрутизаторы, как в CM5). Диаметр – 2*log2p, бисекция – 1. Корень – узкое место, поэтому в CM5 используется т.н. «толстое дерево» - пропускная способность каждого k-го уровня в 2 (или более) раз больше, чем k+1 –го (корень – уровень 0). Реально это означает, что у узла – 2 (или более) родителя. Тогда бисекция – p/2.
Гиперкубы.
В булевом и евклидовом пространстве. Булевы – {0,1} евклидовы - {0,1,…,Ni-1}
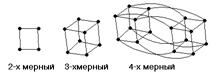
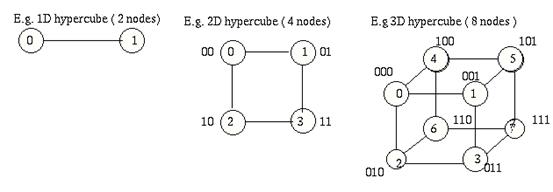
d-мерный гиперкуб состоит из 2^d проц-ров, каждый имеет d-бит адрес. Процессоры i и j соединены, если их адреса отличаются ровно 1 битом. Маршрутизация - по путям, определяемым кодом Грея. Код Грея (d-битный) – это перестановка целых чисел от 0 до 2^d-1 такая, что соседние числа в списке (а также 1 от последнего) отличаются ровно 1 битом в двоичном выражении. Т.о., это ближайшие соседи по гиперкубу. Такой список можно построить рекурсивно. Пусть G(1) = {0, 1} – 1-бит код Грея. Тогда, определив d-битный код как:
|
|
|
G(d) = { g(0), g(1),..., g(2^d-1) },
можно определить d+1 – битный код как:
G(d+1) = { 0g(0), 0g(1),..., 0g(2^d-1), 1g(2^d-1),..., 1g(1), 1g(0) }
Очевидно, если в G(d) g(i) и g(i+1) отличаются 1 битом, то это справедливо и для G(d+1).
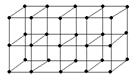
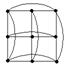
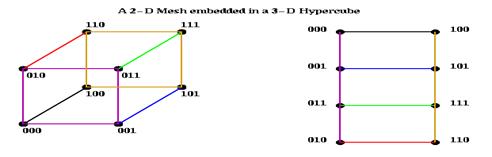
Поскольку в гиперкубе значительно больше связей, чем в решетке или в дереве, то эти топологии можно «встроить» в гиперкуб. Например:
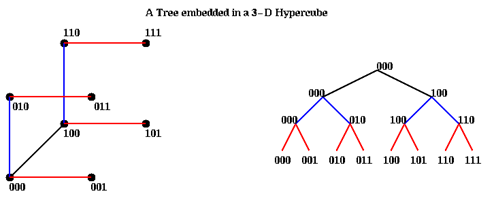
Следует учесть, что размерности решетки д.б. степенями 2, и для встраивания решетки 2^m1 x 2^m2 x … x 2^mk необходим гиперкуб размерностью m1+m2+…+mk.
Кольца встраиваются еще проще, т.к. код Грея точно описывает порядок соединения процессоров в кольце.
 | 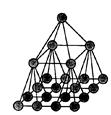 | ||
Во многих случаях используются другие топологии. Так, при обработке изображений используют mesh-of-trees и пирамиды.
Mesh-of-trees строится на основе решетки из n2 процессоров. Над каждой строкой и колонкой строится дерево. Эти деревья не соединены, за исключением листьев, т.е. процессоров, к-е входят в решетку. Количество процессоров – 3n2-2n
Пирамида также основана на решетке из n2 процессоров, образующих уровень 0. Далее строятся следующие уровни, каждый из которых содержит ¼ числа процессоров предыдущего уровня, и каждый процессор имеет 4 потомков. Т.о. корень будет находиться на уровне log4(n). Общее количество процессоров – (4/3)n2 – 1/3.
|
|
|
|
|
Дата добавления: 2015-07-02; Просмотров: 441; Нарушение авторских прав?; Мы поможем в написании вашей работы!