КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Принцип оптимальности Беллмана
|
|
|
|
Основным методом динамического программирования является метод рекуррентных соотношений; который основывается на использовании принципа оптимальности, разработанного американским математиком Р.Беллманом.
Суть принципа:
Каковы бы ни были начальное состояние на любом шаге и управление, выбранное на этом шаге, последующие управления должны выбираться ОПТИМАЛЬНЫМИ относительно состояния, к которому придет система в конце каждого шага.
Использование данного принципа гарантирует, что управление, выбранное на любом шаге, не локально лучше, а лучше с точки зрения процесса в целом.
 Условная оптимизация
Условная оптимизация
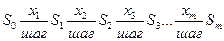
Безусловная оптимизация
 Si – состояние системы на i-м шаге. Основная рекуррентная формула динамического программирования в случае решения задачи максимизации имеет вид:
Si – состояние системы на i-м шаге. Основная рекуррентная формула динамического программирования в случае решения задачи максимизации имеет вид:
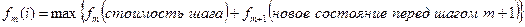 , где максимум в данной формуле берется по всем возможным решениям в ситуации, когда система на шаге m находится в состоянии i.
, где максимум в данной формуле берется по всем возможным решениям в ситуации, когда система на шаге m находится в состоянии i.
Величина fm(i) – есть максимальная прибыль завершения задачи из состояния i, если предположить, что на шаге m, система находится в состоянии i.
Максимальная прибыль может быть получена максимизацией суммы прибылей самого шага m и максимальной прибыли шага (m+1) и далее, чтобы дойти до конца задачи.
Планируя многошаговую операцию надо выбирать управление на каждом шаге с учетом всех его будущих последствий на ещё предстоящих шагах.
Управление на i-м шаге выбирается не так, чтобы выигрыш именно на данном шаге был максимальным, а так, чтобы была максимальна сумма выигрышей на всех оставшихся шагах плюс данный шаг.
Среди всех шагов последний шаг планируется без оглядки на будущее, т.е. чтобы он сам, как таковой принес наибольшую выгоду.
|
|
|
Задача динамического программирования начинает решаться с конца, т.е. с последнего шага. Решается задача в 2 этапа:
1 этап (от конца к началу по шагам): Проводится условная оптимизация, в результате чего находится условные оптимальные управления и условные оптимальные выигрыши по всем шагам процесса.
2 этап (от начала к концу по шагам): Выбираются (прочитываются) уже готовые рекомендации от 1-го шага до последнего и находится безусловное оптимальное управление х*, равный х*1, х*2, …, х*m.
|
|
|
|
|
Дата добавления: 2015-06-27; Просмотров: 386; Нарушение авторских прав?; Мы поможем в написании вашей работы!