КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм поиска в глубину
|
|
|
|
При реализации многих алгоритмов на графах возникает необходимость организовать систематический перебор вершин графа, при котором каждая вершина просматривается точно один раз. Например, в задаче поиска максимального потока в сети, …
Такой перебор можно организовать двумя способами: поиском в глубину или поиском в ширину. При этом программы, реализующие оба поиска, имеют одинаковую структуру и отличаются лишь процедурой, выполняющей перебор вершин.
Основная идея алгоритма поиска в глубину состоит в последовательном движении из заданной вершины вдоль одного из ребер вглубь графа до тех пор, пока не дойдем до вершины, из которой нельзя попасть ни в какую непросмотренную вершину. Такую вершину назовем обработанной. После этого возвращаемся в предыдущую вершину и повторяем поиск. Если после возврата в начальную вершину и ее обработки останутся непросмотренные вершины, то повторим поиск, начиная из любой оставшейся вершины.
Для реализации поиска каждой вершине 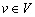 ставится в соответствие логическая переменная
ставится в соответствие логическая переменная 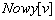 , которая равна
, которая равна 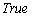 , если данная вершина еще не просмотрена, и
, если данная вершина еще не просмотрена, и 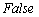 , если вершина просмотрена. Вначале поиска считаем все переменные непросмотренными. Просмотр вершины означает изменение флага и вывод номера вершины. Пусть поиск начинается из вершины
, если вершина просмотрена. Вначале поиска считаем все переменные непросмотренными. Просмотр вершины означает изменение флага и вывод номера вершины. Пусть поиск начинается из вершины 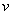 , тогда помечаем ее как просмотренную. Если список инцидентности этой вершины содержит хотя бы одну непросмотренную вершину
, тогда помечаем ее как просмотренную. Если список инцидентности этой вершины содержит хотя бы одну непросмотренную вершину 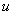 , то переходим в нее, т.е. осуществляем один шаг вглубь графа. Затем повторяем те же действия для вершины и т.д. Если список инцидентности текущей вершины пуст или содержит только просмотренные вершины, то считаем, что вершина обработана, и возвращаемся в предыдущую вершину, т.е. делаем шаг назад.
, то переходим в нее, т.е. осуществляем один шаг вглубь графа. Затем повторяем те же действия для вершины и т.д. Если список инцидентности текущей вершины пуст или содержит только просмотренные вершины, то считаем, что вершина обработана, и возвращаемся в предыдущую вершину, т.е. делаем шаг назад.
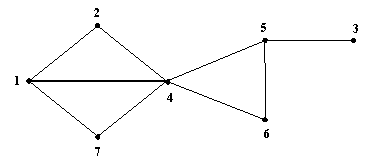
Например, для графа, изображенного на рис. 5 последовательность обхода вершин из начальной вершины 1 имеет вид: 1, 2, 4, 5, 3, 5, 6, 5, 4, 7, 4, 2, 1.
Повтор вершин в списке обхода объясняется тем, что во время обратного шага приходится возвращаться в уже просмотренную вершину. Анализ флага позволяет исключить просмотренные вершины из последовательности поиска в глубину. Поэтому, последовательность просмотра вершин для графа (рис. 3) имеет вид: 1, 2, 4, 5, 3, 6, 7.
|
Рис. 5
Следовательно, каждая вершина просматривается и выводится не более одного раза. Если граф является связным, то будут просмотрены все вершины графа. Это нетрудно показать, предположив противное, что существует непросмотренная вершина w. Отсюда следует, что непросмотренными являются все смежные с ней вершины, так как граф – связен, то существует маршрут связывающий вершины v и w, и за конечное число шагов получим, что начальная вершина v тоже не просмотрена.
Описанный в алгоритме порядок работы с вершинами, при котором вершина, просмотренная последней, обрабатывается первой, реализуется с помощью механизма стека. Приведем здесь вариант процедуры поиска в глубину, использующий этот механизм.
При построении алгоритмов мы будем пользоваться неформальным языком описания алгоритмов. Такой язык по синтаксису похож на язык программирования Паскаль, но он разрешает использование математических обозначений. Это позволяет сосредоточится на сути алгоритма и уйти от технических вопросов его реализации. Для реализации алгоритма на одном из языков программирования необходимо формализовать его в соответствии с правилами языка. Всюду в дальнейшем мы будем использовать следующие обозначения:
1) СПИСОК [ v ] – список инцидентности вершины v;
2) for uÎСПИСОК [ v ] – для всех вершин, содержащихся в списке инцидентности верины v;
3) СТЕК  , ОЧЕРЕДЬ - поместить вершину v в СТЕК или ОЧЕРЕДЬ;
, ОЧЕРЕДЬ - поместить вершину v в СТЕК или ОЧЕРЕДЬ;
4) 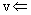 СТЕК; ОЧЕРЕДЬ - извлечь вершину v из СТЕКА или ОЧЕРЕДИ.
СТЕК; ОЧЕРЕДЬ - извлечь вершину v из СТЕКА или ОЧЕРЕДИ.
procedure DEPTH(v);
begin СТЕК 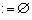 ; СТЕК ;
; СТЕК ;
NOWY [v ] 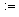 False; Write (v); {вершина просмотрена}
False; Write (v); {вершина просмотрена}
while СТЕК 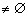 do
do
begin t top(СТЕК);
P mas_ref [t];
{поиск ноой вершины в списке вершины t}
while (P<>nil) and (not Nowy [P^.num])
do P P^.sled;
if P ¹ nil then {найдена новая вершина}
begin t P^.num; СТЕК 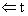 ;
;
NOWY [ t ] False; Write (t)
end
else {вершина t использована}
t 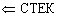
end
end;
Основная программа поиска имеет вид.
var NOWY: array [1..n] of boolean;
begin for v 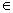 V do NOWY [ v ] True;
V do NOWY [ v ] True;
for v V do
if NOWY [ v ] then DEPTH (v)
end.
В первом цикле программы производится инициализация массива 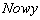 . Далее для первой непросмотренной вершины вызывается процедура поиска. Если граф – связный, то после возврата в основную программу поиск будет закончен. В противном случае при первом вызове процедуры DEPTH будут просмотрены все вершины одной связной компоненты графа, затем поиск повторится, начиная с первой непросмотренной вершины. Таким образом, обращение к процедуре DEPTH(v) из основной программы происходит всякий раз при переходе к очередной связной компоненте графа.
. Далее для первой непросмотренной вершины вызывается процедура поиска. Если граф – связный, то после возврата в основную программу поиск будет закончен. В противном случае при первом вызове процедуры DEPTH будут просмотрены все вершины одной связной компоненты графа, затем поиск повторится, начиная с первой непросмотренной вершины. Таким образом, обращение к процедуре DEPTH(v) из основной программы происходит всякий раз при переходе к очередной связной компоненте графа.
Например, рассмотрим невязный граф.
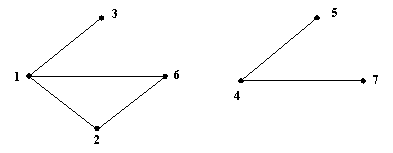
Рис. 6
Начнем поиск с начальной вершины 1. При вызове процедуры DEPTH(1) получаем следующую последовательность вершин: 1, 2, 6, 3, после чего происходит выход из процедуры в основную программу, т.к. список смежности исходной вершины исчерпан. При следующем вызове процедуры просмотр начнется с первой непросмотренной вершины 4, принадлежащей следующей связной компоненте графа.
Таким образом, для произвольного графа алгоритм работает корректно, то есть будут просмотрены все вершины графа, причем каждая не более одного раза.
Механизм стека автоматически реализуется в Паскале рекурсивной процедурой. Опишем такую процедуру.
procedure DEPTHR(v);
begin NOWY [v ] False; write (v);
for u СПИСОК [ v ] do
if NOWY [ u ] then DEPTHR (u);
end;
Оценим вычислительную сложность рекурсивного варианта алгоритма. В качестве основной операции, по числу выполнений которой определяется трудоемкость алгоритма, выберем вызов процедуры DEPTHR.
В основной программе она вызывается не более 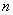 раз. Внутри самой процедуры ее вызов в каждой вершине осуществляется столько раз, сколько эта вершина имеет смежных, или сколько ребер ей инцидентны. Т.к. каждое ребро инцидентно двум вершинам, то число вызовов не более
раз. Внутри самой процедуры ее вызов в каждой вершине осуществляется столько раз, сколько эта вершина имеет смежных, или сколько ребер ей инцидентны. Т.к. каждое ребро инцидентно двум вершинам, то число вызовов не более 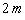 . Следовательно, вычислительная сложность алгоритма можно оценить как
. Следовательно, вычислительная сложность алгоритма можно оценить как
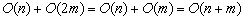 .
.
|
|
|
|
|
Дата добавления: 2015-06-27; Просмотров: 1280; Нарушение авторских прав?; Мы поможем в написании вашей работы!