КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
ВВЕДЕНИЕ 2 страница. - Не проводить фильтрацию для таких пикселей, обрезав изображение B по краям, или применив для их значений исходные значения изображения А
|
|
|
|
- Не проводить фильтрацию для таких пикселей, обрезав изображение B по краям, или применив для их значений исходные значения изображения А.
- Не включать отсутствующий пиксель в суммирование, распределив его вес h(i, j) равномерно среди других пикселей окрестности N(x, y).
- Доопределить значения пикселей за границами изображения при помощи экстраполяции.
- Доопределить значения пикселей за границами изображения, при помощи зеркального продолжения изображения.
Выбор способа производится с учетом конкретного фильтра и особенностей изображения.
Сглаживающие фильтры. Простейший прямоугольный сглаживающий фильтр радиуса r задается при помощи матрицы размера (2r+1) × (2r+1), все значения которой равны 1/(2r+1)2, а сумма значений равна единице. Это двумерный аналог низкочастотного одномерного П-образного фильтра скользящего среднего. При фильтрации с таким ядром значение пикселя заменяется усредненным значением пикселей в квадрате со стороной 2r+1 вокруг него. Пример маски фильтра 3× 3:
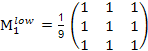 .
.
Одним из применений фильтров является шумоподавление. Шум меняется независимо от пикселя к пикселю и, при условии, что математическое ожидание значения шума равно нулю, шумы соседних пикселей при суммировании будут компенсировать друг друга. Чем больше окно фильтрации, тем меньше будет усредненная интенсивность шума, однако при этом будет происходить и соответствующее размытие значащих деталей изображения. Образом белой точки на черном фоне при фильтрации (реакция на единичный импульс) будет равномерно серый квадрат.
Шумоподавление при помощи прямоугольного фильтра имеет существенный недостаток: все пиксели в маске фильтра на любом расстоянии от обрабатываемого оказывают на результат одинаковый эффект. Несколько лучший результат получается при модификации фильтра с увеличением веса центральной точки:
|
|
|
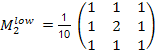 .
.
Более эффективное шумоподавление можно осуществить, если влияние пикселей на результат будет уменьшаться с увеличением расстояния от обрабатываемого. Этим свойством обладает гауссовский фильтр с ядром: h(i, j) = (1/2ps2) exp(-(i2+j2)/2s2). Гауссовский фильтр имеет ненулевое ядро бесконечного размера. Однако значения ядра фильтра очень быстро убывает к нулю при удалении от точки (0, 0), и потому на практике можно ограничиться сверткой с окном небольшого размера вокруг (0, 0), например, взяв радиус окна равным 3σ.
Гауссовская фильтрация также является сглаживающей. Однако, в отличие от прямоугольного фильтра, образом точки при гауссовой фильтрации будет симметричное размытое пятно, с убыванием яркости от середины к краям. Степень размытия изображений определяются параметром σ.
Контрастоповышающие фильтры. Если сглаживающие фильтры снижают локальную контрастность изображения, размывая его, то контрастоповышающие фильтры производят обратный эффект и, по существу, являются фильтрами высоких пространственных частот. Ядро контрастоповышающего фильтра в точке (0, 0) имеет значение, большее 1, при общей сумме значений, равной 1. Например, контрастоповышающими фильтрами являются фильтры с ядром, задаваемым матрицами:
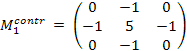 .
. 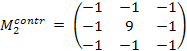 .
.
 Рис. 17.3.1.
Рис. 17.3.1.
|
Пример применения фильтра 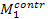 приведен на рис. 17.3.1. Эффект повышения контраста достигается за счет того, что фильтр подчеркивает разницу между интенсивностями соседних пикселей, удаляя эти интенсивности друг от друга. Этот эффект будет тем сильней, чем больше значение центрального члена ядра. Характерным артефактом линейной контрастоповышающей фильтрации являются заметные светлые и менее заметные темные ореолы вокруг границ.
приведен на рис. 17.3.1. Эффект повышения контраста достигается за счет того, что фильтр подчеркивает разницу между интенсивностями соседних пикселей, удаляя эти интенсивности друг от друга. Этот эффект будет тем сильней, чем больше значение центрального члена ядра. Характерным артефактом линейной контрастоповышающей фильтрации являются заметные светлые и менее заметные темные ореолы вокруг границ.
|
|
|
Разностные фильтры – это линейные фильтры, задаваемые дискретными аппроксимациями дифференциальных операторов (по методу конечных разностей). Данные фильтры играют важнейшую роль во многих приложениях, например, для задач поиска границ на изображении.
Простейшим дифференциальным оператором является взятие производной по x-координате d/dx, который определен для непрерывных функций. Распространенными вариантами аналогичных операторов для дискретных изображений являются фильтры Прюита (Prewitt) и Собеля (Sobel):
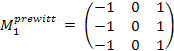 .
.  .
.
Фильтры, приближающие оператор производной по y-координате d/dy, получаются путем транспонирования матриц.
Простейший алгоритм вычисления нормы градиента по трем смежным точкам:
G(x, y) = 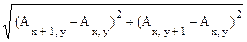 .
.
Применяется также упрощенная формула вычислений:
G(x, y) @ 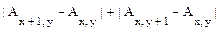 .
.
Вычисление нормы градиента по четырем смежным точкам (оператор Робертса):
G(x, y) = 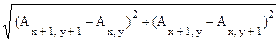 .
.
G(x, y) @ 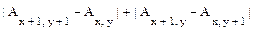 .
.
В алгоритме Собеля используется восемь отсчетов яркости в окрестностях центральной точки:
G(x, y) = 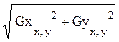 , G(x, y) @
, G(x, y) @ 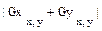 ,
,
Gxx,y= [Ax-1,y-1+2Ax-1,y+Ax-1,y+1] - [Ax+1,y-1+2Ax+1,y+Ax+1,y+1],
Gyx,y = [Ax-1,y-1+2Ax,y-1+Ax+1,y-1] - [Ax-1,y+1+2Ax,y+1+Ax+1,y+1].
Наряду с более точным определением нормы градиента алгоритм Собеля позволяет определять и направление вектора градиента в плоскости анализа изображения в виде угла j между вектором градиента и направлением строк матрицы:
j(x, y) = argtg(Gyx,y /Gxx,y).
В отличие от сглаживающих и контрастоповышающих фильтров, не меняющих среднюю интенсивность изображения, в результате применения разностных операторов получается, как правило, изображение со средним значением пикселя близким к нулю. Вертикальным перепадам (границам) исходного изображения соответствуют пиксели с большими по модулю значениями на результирующем изображении. Поэтому разностные фильтры называют также фильтрами выделения границы объектов.
Аналогично вышеприведенным фильтрам, по методу конечных разностей можно составить фильтры для других дифференциальных операторов. В частности, важный для многих приложений дифференциальный оператор Лапласа (лапласиан) D= 𝝏2/𝝏x2 + 𝝏2/𝝏y2 можно приблизить для дискретных изображений фильтром с матрицей (один из вариантов):
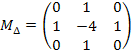 .
.
 Рис. 17.3.2.
Рис. 17.3.2.
|
Как видно на рис. 17.3.2, в результате применения дискретного лапласиана большие по модулю значения соответствуют как вертикальным, так и горизонтальным перепадам яркости. Фильтр является, таким образом, фильтром, находящим границы любой ориентации. Нахождение границ на изображении может производиться путем применения этого фильтра и взятия всех пикселей, модуль значения которых превосходит некоторый порог.
|
|
|
Однако такой алгоритм имеет существенные недостатки. Главный из них - неопределенность в выборе величины порога. Для разных частей изображения приемлемый результат обычно получается при существенно разных пороговых значениях. Кроме того, разностные фильтры очень чувствительны к шумам изображения.
Двумерная циклическая свертка. Как и для одномерных сигналов, двумерная свертка может выполняться в области пространственных частот с использованием алгоритмов быстрого преобразования Фурье и перемножением двумерных спектров изображения и ядра фильтра. Она также является циклической, и выполняется обычно в скользящем варианте. С учетом цикличности, для вычисления постоянного шаблона спектра ядра размеры маски фильтра ядра удваиваются по осям и дополняются нулями, и эти же размеры маски используются для выделения скользящего по изображению окна, в пределах которого и выполняется БПФ. Реализация КИХ фильтра с помощью БПФ особенно эффективна, если фильтр имеет большую опорную область.
Нелинейные фильтры. В цифровой обработке изображений широко применяются нелинейные алгоритмы на основе ранговой статистики для восстановления изображений, поврежденных различными моделями шумов. Они позволяют избежать дополнительного искажения изображения при удалении шума, а также значительно улучшить результаты работы фильтров на изображениях с высокой степенью зашумленности.
Введем понятие M-окрестности элемента изображения A(x, y), который является для этой окрестности центральным. В простейшем случае M-окрестность содержит N-пикселей – точки, попадающие в маску фильтра, включая (или не включая) центральный. Значения этих N-элементов можно расположит в вариационном ряду V(r), ранжированном по возрастанию (или убыванию), и вычислить определенные моменты этого ряда, например, среднее значение яркости mN и дисперсии dN. Вычисление выходного значения фильтра, которым заменяется центральный отсчет, выполняется по формуле:
|
|
|
B(x, y) = aА(x, y) + (1-a)mN. (17.3.2)
Значение коэффициента a = [0, 1] связывается определенной зависимостью со статистикой отсчетов в окне фильтра, например:
a = dN /(dN + k dS), (17.3.3)
где dS – дисперсия шумов по изображению в целом или по S-окрестности при S > M и MÎS, k - константа доверия дисперсии S-окрестностей. Как следует из этой формулы, при k=1 и dN» dS имеет место a» 0.5, а значение B(x, y) = (А(x, y) + mN)/2, т.е. складываются в равной степени от значений центрального отсчета и среднего значения пикселей его M-окрестности. При увеличении значений dN происходит увеличение вклада в результат значения центрального отсчета, при уменьшении – значения mN. Весомость вклада средних значений по M-окрестности можно изменять значением коэффициента k.
Выбор статистической функции и характер зависимости от нее коэффициента a может быть достаточно многообразным (например, по дисперсиям разностей отсчетов в М-окрестности с центральным отсчетом), и зависит как от размеров апертуры фильтра, так и от характера изображений и шумов. По существу, значение коэффициента a должно задавать степень поврежденности центрального отсчета и, соответственно, функцию заимствования для его исправления отсчетов из М-окрестности.
Наиболее простыми и распространенными типами нелинейных фильтров для обработки изображений являются пороговые и медианные фильтры.
Пороговая фильтрация задается, например, следующим образом:
B(x, y) = 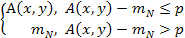
Величина p является порогом фильтрации. Если величина центральной точки фильтра превышает среднее значение отсчетов mN в ее М-окрестности на величину порога, то она заменяется средним значением. Значение порога может быть как константой, так и функционально зависимым от величины центральной точки.
Медианная фильтрация определяется следующим образом:
B(x, y) = med {M(x, y)},
т.е. результат фильтрации есть медианное значение пикселей окрестности, форма которой определяется маской фильтра. Медианная фильтрация способна эффективно удалять из изображения помехи, независимо воздействующие на отдельные пиксели. Например, такими помехами являются "битые" пиксели при цифровой съемке, "снеговой" шум, когда часть пикселей заменяется на пиксели с максимальной интенсивностью, и т.п. Преимущество медианной фильтрации заключается в том, что "горячий" пиксель на темном фоне будет заменен темным, а не "размазан" по окрестности.
Медианная фильтрация обладает выраженной избирательностью по отношению к элементам массива, представляющим собой немонотонную составляющую последовательности чисел в пределах апертуры фильтра. В то же время монотонную составляющую последовательности медианный фильтр оставляет без изменений. Благодаря этой особенности, медианные фильтры при оптимально выбранной апертуре сохраняют без искажений резкие границы объектов, подавляя некоррелированные или слабо коррелированные помехи и малоразмерные детали.
Фильтры экстремумов определяются по правилам:
Bmin(x, y) = min {M(x, y)},
Bmax(x, y) = max {M(x, y)},
т.е. результат фильтрации есть минимальное и максимальное значения пикселей в маске фильтра. Применяются такие фильтры, как правило, для бинарных изображений.
17.4. СЖАТИЕ ИЗОБРАЖЕНИЙ [1i]
Типичное изображение с разрешением порядка 3000×2000 при 24 бит на пиксель для передачи цвета имеет объем 17 мегабайт. Для профессиональных устройств размер получаемого растра изображений может быть значительно больше, глубина цвета до 48 бит на пиксель, а размер одного изображения может быть больше 200 мегабайт. Поэтому весьма актуальными являются алгоритмы сжатия изображений для уменьшения объема данных, представляющих изображение.
Существуют два основных класса алгоритмов:
1. Сжатие без потерь А (lossless compression), если существует такой обратный алгоритм A-1, что для любого h - изображения A[h] = h1 имеем A-1[h1] = h. Сжатие без потерь применяется в таких графических форматах представления изображений, как: GIF, PCX, PNG, TGA, TIFF, и применяется при обработке особо ценной первичной информации (медицинские изображения, аэро- и космоснимки и т.п.), когда даже малейшие искажения нежелательны
2. Сжатие c потерями (lossy compression), если оно не обеспечивает возможность точного восстановления исходного изображения. Парный к A алгоритм примерного восстановления изображения будем обозначать как A*. Пара (A, A*) подбирается так, чтобы обеспечить большие коэффициенты сжатия при сохранении визуального качества. Сжатие с потерями применяется в графических форматах: JPEG, JPEG2000 и т.д.
Все алгоритмы и утверждения относятся как к изображениям, так и к произвольным последовательностям, элементы которых могут принимать конечное количество значений. При этом следует учитывать, что не существует идеальных алгоритмов, сжимающих без потерь любой набор данных.
Алгоритмы кодирования длины повторения (RLE) базируются на простом принципе: замене повторяющихся групп элементов исходной последовательности на пару (количество, элемент), либо только на количество.
Битовый уровень. Будем рассматривать исходные данные на уровне последовательности битов, например, представляющих черно-белое изображение. Подряд обычно идет несколько 0 или 1, и кодировать можно количество идущих подряд одинаковых цифр. Но количество повторений также надо кодировать битами. Можно считать, что каждое число повторений изменяется от 0 до 7 (3-х битовый код), чередуя последовательность кодов единиц и нулей. Например, последовательности 11111111111 можно сопоставить числа 7 0 4, т.е. 7 единиц, 0 нулей, 4 единицы, при этом имеем новый год – 111 000 100. Чем больше длина последовательностей одинаковых бит, тем больше эффект. Так, последовательность из 21 единицы, 21 нуля, 3 единиц и 7 нулей закодируется так: 111 000 111 000 111 111 000 111 000 111 011 111, т.е. из исходной последовательности длиной 51 бит, имеем последовательность длиной 36 бит.
Байтовый уровень. Предположим, что на вход подается полутоновое изображение, где на значение интенсивности пикселя отводится 1 байт, при этом ожидание длинной цепочки одинаковых битов существенно снижается.
Будем разбивать входной поток на байты (код от 0 до 255) и кодировать повторяющиеся байты парой (количество, буква). Одиночный байт можно не изменять. Так, байты AABBBCDAA кодируем (2A) (3B) (C) (D) (2A).
Однако модификации данного алгоритма редко используются сами по себе (например, в формате PCX), т.к. подкласс последовательностей, на которых алгоритм эффективен, относительно узок. Чаще они используются как одна из стадий конвейера сжатия.
Словарные алгоритмы вместо кодирования только по одному элементу входящей последовательности производят кодирование цепочки элементов. При этом используется словарь цепочек (созданный по входной последовательности) для кодирования новых.
Алгоритм LZ77 был одним из первых, использующих словарь. В качестве словаря используются N последних уже закодированных элементов последовательности. В процессе сжатия словарь-подпоследовательность "скользит" по входящей последовательности. Цепочка элементов на выходе кодируется следующим образом: положение совпадающей части обрабатываемой цепочки элементов в словаре - смещение (относительно текущей позиции), длина, первый элемент, следующий за совпавшей частью цепочки. Длина цепочки совпадения ограничивается сверху числом n. Соответственно, задача состоит в нахождении наибольшей цепочки из словаря, совпадающей с обрабатываемой последовательностью. Если же совпадений нет, то записывается нулевое смещение, единичная длина и первый элемент незакодированной последовательности.
Описанная выше схема кодирования приводит к понятию скользящего окна (sliding window), состоящего из двух частей:
- подпоследовательность уже закодированных элементов длины N-словарь - буфер поиска (search buffer);
- подпоследовательность длины n из цепочки элементов, для которой будет произведена попытка поиска совпадения - буфер предварительного просмотра (look-ahead buffer).
Декодирование сжатой последовательности является расшифровкой записанных кодов: каждой записи сопоставляется цепочка из словаря и явно записанного элемента, после чего производится сдвиг словаря. Словарь воссоздается по мере работы алгоритма декодирования.
Данный алгоритм является родоначальником целого семейства алгоритмов. К его достоинствам можно отнести приличную степень сжатия на достаточно больших последовательностях и быструю распаковку. К недостаткам относят медленную скорость сжатия и меньшую, чем у альтернативных алгоритмов, степень сжатия.
Алгоритм LZW. Словарь в данном алгоритме представляет собой таблицу, которая заполняется цепочками элементов по мере работы алгоритма. В процессе сжатия отыскивается наиболее длинная цепочка, уже записанная в словарь. Каждый раз, когда новая цепочка элементов не найдена в словаре, она добавляется в словарь, при этом записывается код цепочки. В теории на размер таблицы не накладывается ограничений, однако ограничение на размер позволяет улучшить степень сжатия, т.к. накапливаются ненужные (не встречающиеся) цепочки. Чем больше вхождений имеет таблица, тем больше информации нужно выделять для хранения кодов.
Декодирование заключается в прямой расшифровке кодов, т.е. в построении словаря и вывода соответствующих цепочек. Словарь инициализируется так же, как и в кодере. К достоинствам алгоритма можно отнести высокую степень сжатия и достаточно высокую скорость, как сжатия, так и декодирования.
Алгоритмы статистического кодирования ставят в соответствие каждому элементу последовательности код так, чтобы его длина соответствовала вероятности появления элемента. Сжатие происходит за счет замены элементов исходной последовательности, имеющих одинаковые длины (каждый элемент занимает одинаковое количество бит), на элементы разной длины, пропорциональной отрицательному логарифму от вероятности, т.е. элементы, встречающиеся чаще, чем остальные, имеют код меньшей длины.
Алгоритм Хаффмена использует префиксный код переменной длины, обладающий особым свойством: менее короткие коды не совпадают с префиксом (начальной частью) более длинных. Такой код позволяет осуществлять взаимно-однозначное кодирование. Процесс сжатия заключается в замене каждого элемента входной последовательности его кодом. Построение набора кодов обычно осуществляется с помощью так называемых кодовых деревьев.
Алгоритм Хаффмена является двухпроходным. Первый проход по изображению создает таблицу весов элементов, а во время второго происходит кодирование. Существуют реализации алгоритма с фиксированной таблицей. Часто бывает, что априорное распределение вероятностей элементов алфавита неизвестно, т.к. не доступна вся последовательность сразу, при этом используются адаптивные модификации алгоритма Хаффмена.
Сжатие изображений с потерями. Объем информации, нужной для хранения изображений, обычно велик. Классические алгоритмы, являясь алгоритмами общего назначения, не учитывают, что сжимаемая информация есть изображение - двумерный объект, и не обеспечивают достаточной степени сжатия.
Сжатие с потерями основывается на особенностях восприятия человеком изображения: наибольшей чувствительности в определенном диапазоне волн цвета, способности воспринимать изображение как единое целое, не замечая мелких искажений. Главный класс изображений, на который ориентированы алгоритмы сжатия с потерями - фотографии, изображения с плавными цветовыми переходами.
Оценка потерь в изображениях. Существует множество мер для оценки потерь в изображениях после их восстановления (декодирования) из сжатых, однако для всех из них можно подобрать такие два изображения, что их мера отличия будет достаточно большой, но на глаз различия будут почти незаметными. И наоборот - можно подобрать изображения, сильно различающиеся на глаз, но имеющие небольшую меру отличия.
Стандартной числовой мерой потерь обычно является среднеквадратическое отклонение (СКО) значений пикселей восстановленного изображения от исходного. Тем не менее, самой важной "мерой" оценки потерь является мнение наблюдателя. Чем меньше различий (а лучше - их отсутствие) обнаруживает наблюдатель, тем выше качество алгоритма сжатия. Алгоритмы сжатия с потерями часто предоставляют пользователю возможность выбирать объем "теряемых" данных, т.е. право выбора между качеством и размером сжатого изображения. Естественно, что чем лучше визуальное качество при большем коэффициенте сжатия, тем алгоритм лучше.
Преобразование Фурье. В общем случае изображение можно рассматривать как функцию двух переменных, определенную в точках конечного растра. Множество таких функций на точках фиксированного конечного растра образуют конечномерное евклидово пространство, и к ним может быть применено дискретное преобразование Фурье, т.е. спектральное представление изображения. Оно обеспечивает:
- Некоррелированность и независимость коэффициентов спектра, т.е. точность представления одного коэффициента не зависит от любого другого.
- "Уплотнение" энергии (energy compaction). Преобразование сохраняет основную информацию в малом количестве коэффициентов. Данное свойство сильнее всего проявляется на фотореалистичных изображениях.
Коэффициенты спектрального представления - это амплитуды пространственных частот изображения. В случае изображений с плавными переходами большая часть информации содержится в низкочастотном спектре.
Алгоритм сжатия, используемый в формате JPEG, построен на использовании дискретного косинусного преобразования Фурье. Схема сжатия в алгоритме представляет собой конвейер, где это преобразование - лишь одна из стадий, но одна из основных. Алгоритм содержит следующие основные операции:
1. Перевод в цветовое пространство YCbCr. Здесь Y - компонента яркости, Cb и Cr - компоненты цветности. Человеческий глаз более чувствителен к яркости, чем к цвету. Поэтому важнее сохранить большую точность при передаче Y, чем при передаче Cb и Cr.
2. Дискретное косинус-преобразование (ДКП). Изображение разбивается на блоки 8 × 8. К каждому блоку применяется дискретное косинус-преобразование (отдельно для компонент Y, Cb и Сr).
3. Сокращение высокочастотных составляющих в матрицах ДКП. Человеческий глаз практически не замечает изменения в высокочастотных составляющих, следовательно, коэффициенты, отвечающие за высокие частоты, можно хранить с меньшей точностью.
|
4. Зигзаг-упорядочивание матриц. Это особый проход матрицы для получения одномерной последовательности. Сначала идет элемент T00, затем T01, T10, T11... Причем для типичных фотореалистических изображений сначала будут идти ненулевые коэффициенты, соответствующие низкочастотным компонентам, а затем - множество нулей (высокочастотные составляющие).
5. Сжатие сначала методом RLE, а затем методом Хаффмена.
Алгоритм восстановления изображения действует в обратном порядке. Степень сжатия от 5 до 100 и более раз. При этом визуальное качество для большинства фотореалистичных изображений остается на хорошем уровне при сжатии до 15 раз. Алгоритм и формат являются самыми распространенными для передачи и хранения полноцветных изображений.
Вейвлет-преобразование сигналов является обобщением классического преобразования Фурье. Термин "вейвлет" (wavelet) в переводе с английского означает "маленькая (короткая) волна". Вейвлеты - это обобщенное название семейств математических функций определенной формы, которые локальны во времени и по частоте, и в которых все функции получаются из одной базовой посредством ее сдвигов и растяжений по оси времени.
В алгоритмах сжатия с потерями, как правило, сохраняются все операции конвейера сжатия с заменой дискретного преобразования Фурье на дискретное вейвлет-преобразование. Вейвлет-преобразования имеют очень хорошую частотно-пространственную локализацию и по этому показателю превосходят традиционные преобразования Фурье. При этом становится возможно применять более сильное квантование, улучшая свойства последовательности для последующего сжатия. Алгоритмы сжатия изображений, основанные на этом преобразовании, при той же степени сжатия показывают лучшие результаты по сохранению качества изображения.
А.В.Давыдов.
24.03.08.
литература
46. Хуанг Т.С. и др. Быстрые алгоритмы в цифровой обработке изображений. – М.: Радио и связь, 1984. – 224 с.
47. Сойфер В.А. Компьютерная обработка изображений. Часть 2. Методы и алгоритмы. – Соросовский образовательный журнал №3, 1996.
48. Апальков И.В., Хрящев В.В. Удаление шума из изображений на основе нелинейных алгоритмов с использованием ранговой статистики. - Ярославский государственный университет, 2007.
49. Андреев А.Л. Автоматизированные телевизионные системы наблюдения. Часть II. Арифметико -логические основы и алгоритмы. Учебное пособие. - СПб: СПб, ГУИТМО, 2005. – 88с.
51. Лукин А. Введение в цифровую обработку сигналов (Математические основы).- М.: МГУ, Лаборатория компьютерной графики и мультимедиа, 2002. – http://pv.bstu.ru/dsp/dspcourse.pdf, http://dsp-book.narod.ru/dspcourse.djvu, http://geogin.narod.ru/arhiv/dsp/dsp4.pdf.
1i. Иванов Д.В. и др. Алгоритмические основы растровой графики. – Интернет университет информационных технологий. – http://www.intuit.ru/goto/course/rastrgraph/
2i. Лукин С.Б. Оптико-электронные системы: Конспект лекций. ИТМО, 2004. – СПб, ИТМО ИФФ, 2004. - http://iff.ifmo.ru/kons/oes/KL.htm
Cайт автора Лекции Практикум
О замеченных ошибках и предложениях по дополнению: [email protected].
|
|
|
|
|
Дата добавления: 2015-06-28; Просмотров: 547; Нарушение авторских прав?; Мы поможем в написании вашей работы!