КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Идеология организации без упорядоченного выполнения 13 страница
|
|
|
|
разряды[28-31] – номер кластера
разряды[24-27]- номер процессора в кластере
таким образом, при принятой схеме логической адресации можно адресовать до 60 агентов в системе так значение адреса кластера равное F используется для обращения ко всем агентам на шине одновременно.
Но дело в том, что данное количество процессоров на шине разместить на шине при данной архитектуре не возможно, так как арбитражный идентификатор в данной системе имеет всего четыре разряда, поэтому, даже отказавшись от принятой арбитражной схемы, можно только зафиксировать максимум 15 агентов при условии значение 1111 использовать как широковещательный адрес. Поэтому при количестве агентов больше 15 используется иерархическая система, состоящая из нескольких шин связь между которыми осуществляется через специальные аппаратные средства- менеджеры. Такая технология используется в системе неоднородных мультипроцессорных системах, но это уже другая архитектура, которую мы рассмотрим позже.
Регистр команд прерываний.
Данный регистр используется для организации сообщений в системе, поэтому прежде чем разбирать использование информации в этом регистре, целесообразно классифицировать виды сообщений и форматы кадров, передаваемых в них.
Виды сообщений
сообщениеEOI- окончание обработки прерывания
короткое сообщение- для передачи запросов на прерывание
сообщение для выявления агента с наименьшим приоритетом
сообщения типа ’удаленное чтение’ - для передачи информации между агентами
с точки зрения выбора адресата для сообщения все сообщения делятся на две группы;
статическое распределение, когда адресат указывается в сообщении
динамическое, когда адресат выявляется в процессе передачи сообщения в системе- определение адреса процессора с наименьшим приоритетом
|
|
|
Формат сообщения в общем виде имеет следующую структуру
 
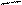
| 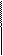
| 
| 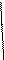 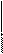
| 
| |||||||||||||||
| 
| ||||||||||||||||||
| |||||||||||||||||||



Режимы передачи:
000- FIX
передача сообщения ко всем агентам системы информации, подготовленной в регистре команды прерывания
001- LOST
наименьший приоритет, передается также как и FIX ко всем агентам, за исключением того, приемником сообщения становится процессор с наименьшим приоритетом выполняемой задачи
010-SMI
Прерывания, связанные с режимом системного управления
100-NMI
Немаскируемые, прерывания. возникающие при возникновении аппаратных ошибок в системе
|
|
|
101-INIT
Прерывания ко всем агентам для установки их арбитражных идентификаторов в соответствии со значениями, записанными в их регистрах APICID
110-START
Используются как специальные сообщения между процессорами для указания передачи управления загрузочному блоку для начала активизации процессора приложения, используется в процедуре инициализации многопроцессорной системы
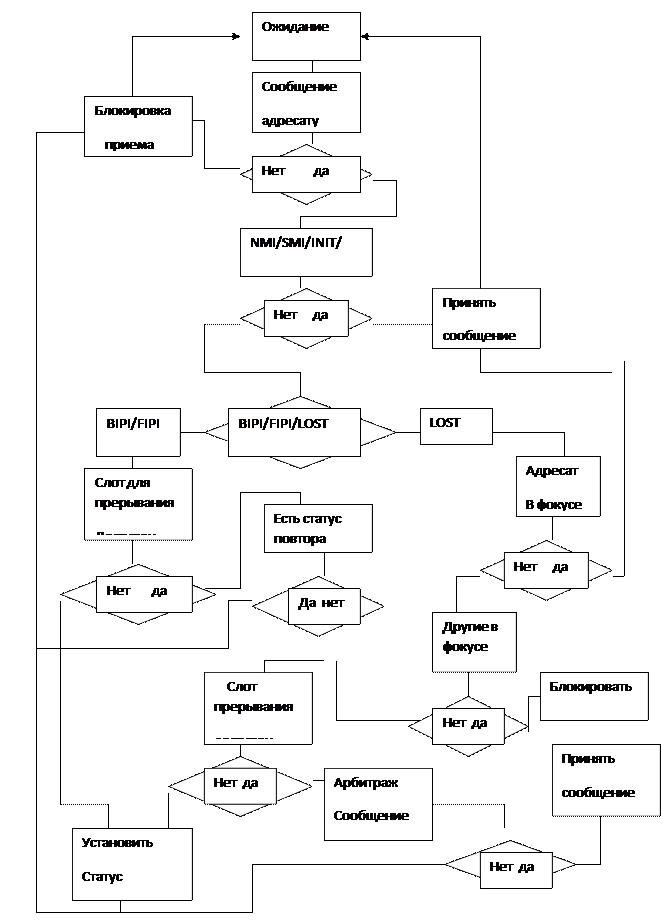
Протокол инициализации мультипроцессорной системы.
Функционирование любой вычислительной системы начинается с ее инициализации. Эта процедура начинается с включения питания. В первоначальный момент времени любая система использует аппаратные средства, которые формируя сигнал аппаратного сброса, устанавливается в исходное состояние, и в частности загружают адрес инструкции начальным значением, указывающим на расположение загрузочного блока в постоянной памяти.
Системы, которые не используют постоянную память для загрузки, аппаратно формируют команду ввода вывода с обращением к устройству загрузки.
Но прежде чем произойдет обращение к устройству загрузки, система должна быть уверена в исправности своих аппаратных средств, поэтому во многих системах при инициализации осуществляется прогон тестов автоматически и только после их успешного прохождения формируется вектор, указывающий на первую команду, с которой начинается программа загрузки. Так в архитектуре процессоров фирмы INTEL такие тесты являются частью BIOS.
В системах со сложной архитектурой, например манфреймах фирмы IBM, операции инициализации и проверку работоспособности аппаратных средств осуществляет сервисный процессор.
В качестве примера рассмотрим протокол инициализации мультипроцессорной системы на базе процессоров фирмы INTEL с архитектурой базовой модели P6.
Для успешной инициализации мультипроцессорной системы протокол накладывает определенные требования и ограничения на систему во время процедуры инициализации:
- все механизмы прерываний в системе должны быть отключены,
- протокол может быть инициирован только после аппаратного сброса,
-по окончании процедуры инициализации, согласно алгоритму, должен быть установлен флаг в блоке локального контроллера APIC для процессора в системе, с которого будет произведена загрузка управляющей программы,
|
|
|
- протокол инициализации основан на том факте, что только одно сообщение может присутствовать на шине в данный момент времени и каждый из агентов может выставить его соответствии с приоритетом.
Действия по инициализации начинаются по сигналу аппаратного сброса, сформированного при включении питания в системе путем активизации диагностических тестов в каждом из процессоров.
Во время прохождения тестов в процессорах арбитраж на шине блокируется до окончания прохождения тестов. Блокировка эта осуществляется путем активизацией сигналов низкого уровня в каждом из процессоров, соединенных между собой в ‘монтажное ИЛИ” на шине арбитража. Поэтому пока будет присутствовать низкий уровень на шине, арбитраж будет заблокирован, и только по окончании тестов в каждом из процессоров он станет высоким.
Далее начинается активизация действий по определению процессора BSP в системе.
Эти действия основаны на следующих положениях:
- процессору, которому будет установлен флаг загрузочного по включению питания, устанавливается низший приоритет путем внешнего монтажа контактов процессоров, подсоединенных к арбитражной шине и подачей сигнала низкого уровня на один из этих контактов в каждом процессоре являющихся двунаправленными.
- для выявления BSP на шине каждый из агентов формирует сообщение типа “всем агентам включая себя” и согласно протоколу формирует в процессе инициализации только один раз
-формируется финальное сообщение, которое автоматически формирует BSP процессор, сообщая всем остальным об окончании процедуры.
-формат сообщения содержит вектор прерывания младшие разряды которого формируются по значениям APICID каждого из процессоров полученных ими с шины арбитража во время аппаратного сброса при включении питания.
Получив сообщение от агента в соответствии с приоритетом на шине, процессора сравнивают значения младших разрядов вектора из сообщения со своими идентификаторами APICID. Если эти значения равны, то процессор определяется как BSP. Если нет, то процессор будет процессором приложений.
|
|
|
На первый взгляд протокол не обеспечивает определения BSP и содержит противоречивое положение так как каждый процессор посылая свое сообщение будет себя идентифицировать как BSP. Но дело в том, что протокол обязывает каждый процессор принять одно сообщение от себя и три от других процессоров, поэтому в привилегированном положении окажется процессор с наименьшим приоритетом в начальный момент активизации межпроцессорных сообщений. Когда этот процессор получит доступ к шине все другие будут иметь статусы приложений и он установит свой статус B SP и сформирует на шину сообщение окончания процедуры с соответствующим значением вектора прерывания.
Получив на шине финальное сообщение, локальные контроллеры прерываний APIC формируют запросы на прерывания, обрабатываемые в BIOS, но так как все процессора, кроме процессора со статусом BSP, имеющие статусы процессоров приложений, будут остановлены до моментов, когда каждый из них получит стартовое сообщение с вектором прерывания от процессора BSP.
Процессор BSP, выставляя на шину стартовое сообщение адресату, в программе включает таймер по истечении которого обращается в оперативную память по определенному адресу с командой чтения, и если адресат присутствует на шине то последний, обрабатывая стартовое сообщение, обязан записать свой идентификатор. Таким образом процессор BSP определяет наличие агентов на шине.
Лекция N 13
1.Проблемы когерентностей кэш в симметричных мультипроцессорных системах. Протоколы MSI, MESI, MOESI.
2. Организация больших многопроцессорных систем на базе процессоров, объеденных в SMP. Архитектура систем CC-NUMA, NC-NUMA, NUMA-Q.
3.Организация SMP с межмодульными связями.
4.Блок-схема SMP с межмодульными связями. Организация многопроцессорной системы CC-NUMA с кольцевой топологией на базе подобных SMP напримере ‘1многокнижной’ архитектуры сервера Z990
Протокол MSI
Данный протокол поддерживает когерентность КЭШей в мультипроцессорных системах используя три состояния строк в КЭШ:
M-модифицированный
S- разделяемое
I-недействительная
M- Состояние строки в результате записи данных из процессора, свидетельствует о содержание в строке кэш измененных данных и несоответствие данных в строке памяти. Данное состояние приведет всех копий данной строки в кэш всех агентов с состояние I.
S- Данное состояние устанавливается когда строка кэш содержит действительное значение данных эквивалентной информации в строке системной памяти. Перевод в данные состояние осуществляется при записи из оперативной памяти или из копии строки в любом кэш при состояние М
Устанавливается если в каком либо кэш копия строки переходит из состояния S в состояние М, или из I и М при условии в последнем случае, если в системе нет уже копии строки в состоянии М, то есть протокол допускает в системе наличие только одной копии с измененными данными. Поэтому при попытке произвести запись процессором в строку с состояния I(недействит.), при наличии копии строки с состояния М в другой кэш, происходит блокировка операций, а шина представляет процессору кэш со строкой в состоянии М, для того, чтобы данный процессор призвал запись в системную память и кэш того процессора каждый пытался создать еще копии с измененными данными. Только после этого, когда в системе будет отсутствовать строка с состоянием М, может быть произведена следующая модификация строки любым из процессоров в системе.
Из анализа работы протокола следует, что данный протокол имеет существенный недосаток, а именно, при любой попытке вторичной модификации в системе, независимо от того, существует одна копия или несколько в системе, контроллер шины вынужден вводить дополнительный цикл записи в оперативную память агенту с 0 строкой в состояние М для ее перевода в S. И только после этого давать возможность другому агенту производить следующую модификацию, так как протокол имея состояний строк с индексом S, не определяет сколько копий строк оперативной памяти находится в КЭШ агентов.
Если предположить, что в системе находится только одна копия строки, то процессору можно было бы разрешить ее модификацию многократно, пока исходная строка из оперативной памяти не потребуется другим агентам. Такая идея была реализована в протоколе MESI, в котором вводится еще одна строка состояние строки.
Е - единственная. Именно это состояние строки КЭШа позволяет производить многократную модификацию, но как только будет сформирован запрос другим агентом за этой строкой из памяти, процессор, имея копию этой строки с М состоянием, обязан сформировать запрос в память и записать эту строку в кэш память и перевести ее из состояния М в S. Агент выставит запрос и ждет пока процессор, владеющий строкой с состоянием М, запишет в память, а потом читает ее из памяти, устанавливая состояние своей строки разделяемое(S).
Протокол MOSI.
Протокол MOSI вводит новое состояние стоки OWNED-(принадлежащий), означающий, что копия данной строки может находиться в других КЭШах, отличаются от копии в системной памяти, то есть переходит в это состояние из состояния М. пока строка находится в состояние О, все её копии в других кэш имеют состояние S, то есть одновременно в системе может находится несколько копий, отличных от оригинал а в системной памяти.
Протокол предусматривает только наличие только одной строки в системе с состоянием “owned”. При попытке модифицировать строку с таким состоянием, все копии строки в других кэш приводятся в состояние I(инвалид), после чего строка переводится в состояние M-“модифицированное”. Строка в состояние “owned” может переходить в состояние S, при записи ее оперативной памяти, так как в этом случае будет соответствие между строками в состояние S в кэш и строки в памяти. Значения M,S,I такие же ак и в протоколах MSI, MESI.
Протокол MOESI.
Протокол MOESI это комбинация протоколов MOSI+MESI=MOESI. Данный протокол позволяет во первых модифицировать копию в кэш, пока строка находится в состояние “Е” без записи ее в оперативную память. При переводе строки в состояние “О”, имеется несколько модифицированных копий в других КЭШах, до момента попытки второй ее модификации, с переводом ее в состояние М после установки ее копий в других кэш в состояние S при записи строки в системную память. Возможен вариант оставить строку в состояние “О” при условии удовлетворить запрет на обновление и сохранение им состояния S.
Мультипроцессоры класса NC-NUMA и СС-NUMA.
Прежде чем рассматривать подробно каждый вид данной категории мультипроцессоров, отметим ключевые характеристики, которыми обладают и которые отличают их от других мультипроцессоров
1. Существует одно адресное пространство, видимое для всех процессоров.
2. Доступ к удаленной памяти производится с использованием команд LOAD и STORE.
3. Доступ к удаленной памяти происходит медленнее чем доступ к локальной памяти.
Подкласс процессоров NC-NUMA характеризуется отсутствием кэш памятей в узлах мультипроцессора, и общая блок-схема имеет следующий вид
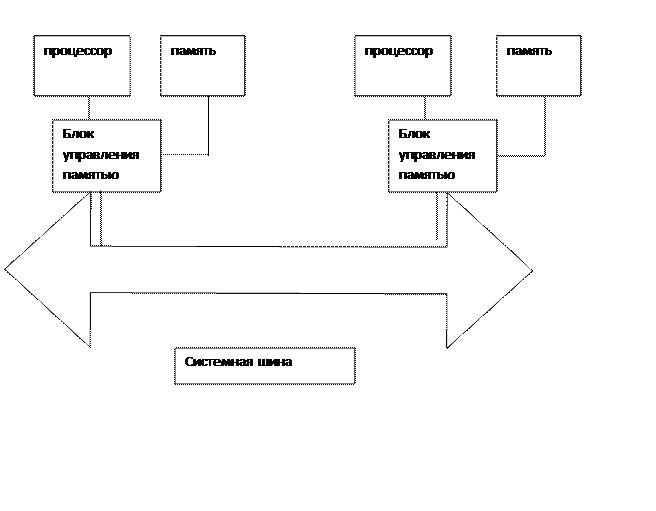
Одной из первых машин NC-NUMA была Carnegie-Mellon
Структурная схема, которой была подобная, указанной выше. Машина состояла из набора процессоров LS-11, каждый с собственной памятью, обращение к которой производилось по локальной шине. Когда запрос приходил в блок управления памятью, производилась проверка, находится ли запрашиваемое слово в локальной памяти. Если да, то запрос выдавался на локальную шину. В противном случае запрос направлялся на системную шину в узел, в памяти которого находилось запрашиваемое слово.
|
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 308; Нарушение авторских прав?; Мы поможем в написании вашей работы!