КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Модуль передатчика
|
|
|
|
На чипе свитча находится 8 модулей передатчиков, каждый из которых принимает для передачи их в выходной порт. Логика передатчика свитча ответственна за выборку данных из передачи или из сервисной логики чипа и передачи их по кабелю или так же через ТЭЗ к приемнику на предназначенный свитч чипа. Передатчик может только передавать данные, когда он получил достоверный сигнал квинта (TOKELY) из соответствующего приемника, указывающего, что приемник имеет возможность принять данные.
Стадия выборки у передающего модуля управляется состоянием чипа, которое определяет, откуда должны быть выбраны данные и отправлены в выходной порт. Данные из селектора пересылаются в FIFO. Назначение FIFO управлять потоком данных при передаче в обрабатывающую логику передатчика, дав возможность обрабатывать входную информацию без останова потока данных (например, при возникновении прерывания при формировании контрольного кода, когда обрабатывающей логике необходимо дополнительное время).
Селектор выходных данных генерирует данные, которые должны быть посланы в канал в зависимости от состояния передающего порта. Он будет осуществлять передачу пакет данных, передавая EDC байты или управляющие коды для приемного порта.
Логика управления квинтами используется как при инициализации, так и при реакции обычных операций передачи данных. Принимаемые квинты увеличивают значения счетчика квитов каждый раз на +1, как только очередная порция данных (2 байта) передается в канал, значение счетчика квитов уменьшается на 1. Исходное значение счетчика, установленное во время инициализации связи. Он может считать до величины эквивалентной разряду памяти в приемном модуле. Если счетчик достигает максимальной величины, квинт принимается, но очередная порция данных в канал не передастся, сигнал переполненного счетчика будет сформирован, но само значение счетчика не будет изменено и останется в максимальном значении. Согласно архитектуре счетчик не может из максимального значения переходить в состояние нулевого значения, т.к. состояние в нуле согласно протоколу будет свидетельствовать об отсутствии данных в буфере приемного модуля, поэтому все данные будут находить в буфере передатчика и в канале по пути следования. При передаче в канал из передающего порта значение счетчика будет уменьшаться и если конечное значение не достигнет нулевого значения будет зафиксирован «промах» и произведена перезагрузка счетчиков приемника и получателя, и несвоевременно будет послан символ, указывающий о неисправности в канале и звено (канал) должен быть переинициализирован.
|
|
|
Признак начала пакета приходит в 2-х вариантах: ВОРа и ВОРв, указывающие какой из байтов поля адреса должен быть декодирован.
ВОРа – старший байт
ВОРв – младший байт

|  Н Н
| Н | Н | L | L | L |
 1 – Использовать младшие разряды
1 – Использовать младшие разряды
0 – использовать старшие разряды
После декодирования адреса назначения пакета данные готовы для передачи в буфер очереди или в сервисную точку чипа. Центральная очередь имеет область памяти в 4 кб с одним портом чтения и одним портом записи, т.к. только один порт записи в чипе. 8 портов от приемников выставляют запрос на запись, требующие арбитража.
Стадия модификации маршрута использует информацию о маршруте, указанном в пакете с целью определения, должен ли пакет быть передан другому чипу свитча или предназначен для принимающего чипа. Модификация информации в поле адресации проводится еще с целью возможности использования в следующей стадии.
Приемник обрабатывает только первые 2 байта поля маршрутизации, следующих за символом начало пакета В.О.Р. Каждый бат поля маршрутизации содержит одно или два значения кода адреса приемного узла. Максимальное значение портов, которое может быть закодировано в 2-х байтах поля адреса при выборе маршрута 4(4 стадии). Как только приемник декодирует указатель порта назначения, он установит «INVALID» для этого поля.
|
|
|

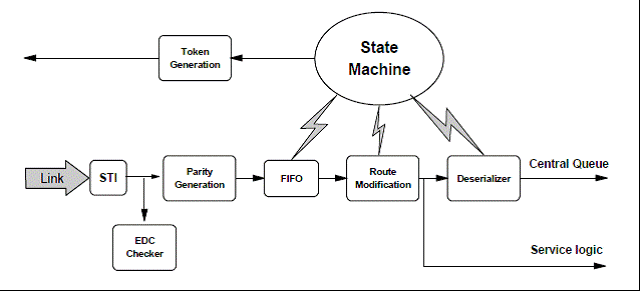
Схема приемного модуля
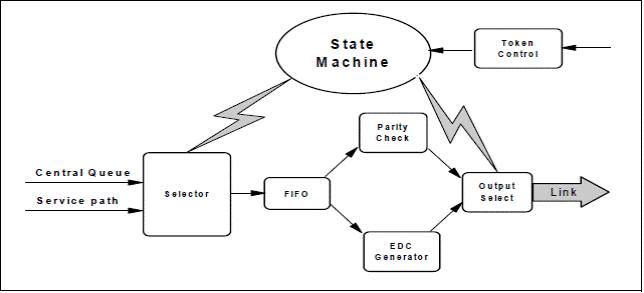
Схема передающего модуля
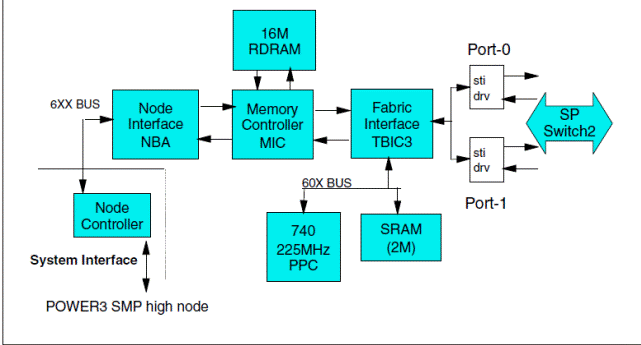
Схема адаптера интерфейса между свитчем и процессорным модулем
MIC ответственен за перемещение данных между NBA и чипом интерфейса связи с свитчем и осуществляет доступ к памяти, предназначенной для промежуточного хранения больших блоков данных, передаваемых между системной памятью узла SMP и другими узлами системы.
Микропроцессор осуществляет связь программного обеспечения процессорного узла SMP с микрокодом адаптера,кодирует и формирует заголовки пакетов и их маршрутизацию
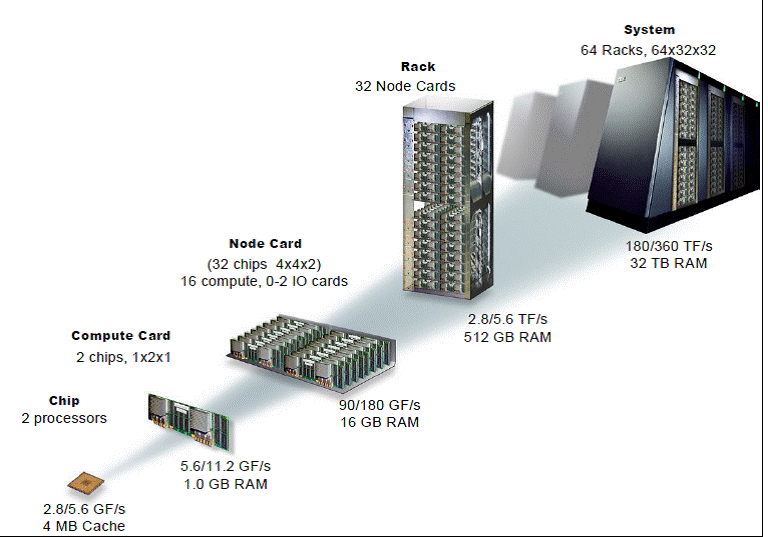
Blue Gene/L компьютер является представителем класса MPP и относится к категории современных суперкомпьютеров. Он был сконструирован с возможностью расширения до 65536 двухпроцессорных модулей с пиковой производительностью до 360 терафлопс.
В основе любого суперкомпьютера класса MPP, определяющего его производительность лежит процессорный узел, их количество в системе, топология их соединения и характеристики этого соединения,определяющие его пропускную способность.
Вычислительный узел в BG/L представляет из себя 2х процессорную SMP с процессорным ядром POWER440. Процессорное ядро представляет из себя классическую архитектуру суперскалярного процессора с номинальной частотой синхронизации 700МГЦ.
Каждый процессор имеет свое устройство с плавающей точкой,которое дает возможность выполнения операций SIMD в нем.
Процессорный модуль может функционировать в двух режимах. В режиме сопроцессора задача занимает весь объем памяти,которую используют оба процессора в 2х поточном режиме распределив потоки между собой.
В виртуальном режиме два независимых процесса, иcпользуя половину памяти выполняются каждый на своем процессоре. Этот режим позволяет одному из процессоров заниматься обработкой передачи и приема сообщений,а на другом производить обработку приложений.
|
|
|
Как видно из приведенной ниже схемы процессорный модуль имеет в своем составе аппаратное оборудование для соединения узла с другими узлами системы.Пять интерфейсов предназначены для этой цели.
Одно из таких соединений предназначено для организации ввода вывода, обеспечивающего доступ узла к параллельной файловой системе, представляющего из себя сеть FAST EHERNET с пропускной способностью 100mb/сек.
3 оставшихся интерфейса предназначены для организации высокоскоростных внутренних сетей.
Сеть TORUS
Известно, что одной из важнейших характеристик системы MPP является внутренняя сеть, соединяющая процессорные модули между собой. Топология такой сети в BG/L 3х размерную тороидальную сеть. Процессорные модули объединены в 3х мерную кубическую решетку, в которой каждый узел подсоединен к 6 ближайшим узлам высокоскоростными линиями связи. Данная сеть гарантирует свободную от блокировки передачу пакетов. Пакеты передаются независимо друг от друга,используя одну из двух стратегий. Алгоритм детерминированной маршрутизации,в котором все пакеты следуют,используя один и тот же порядок следования X>Y>Z и минимальный порядок, который разрешает каждому пакету принимать решение о порядке следования. Размер пакетов может быть от 32 до 256 байтов,.где первые 16 байтов содержат адрес назначения, маршрут и информацию программного заголовка. 14 дополнительных байта, следующие за пакетом содержат контрольную сумму пакета.
Логика внутренней сети на каждом узле содержит 3 основных блока по каждому направлению: процессорный интерфейс, приемник и передатчик.
Процессорный интерфейс, состоящий из двух групп FIFO,предназначен для приема и передачи пакетов из сети и в сеть из процессорного модуля,точнее из устройств с плавающей точкой. Каждое направление а, таких 6 в модуле, имеет свои группы FIFO.В состав каждой группы входит для приемных блоков по 8 FIFO, а передающих по 7, шесть из которых предназначены по одному для каждого направления. Оставшиеся FIFO соответственно 2 и 1 используются для приема высокоприоритетных пакетов.
|
|
|
Тракт данных в каждом приемном блоке представляет 8 стадийный конвейер для виртуальных и транзитного каналов.
Коллективная сеть предназначена для использования в двух целях.Она предназначена,во первых, для подержания протокола MPI, а во вторых является основным механизмом в системе связи между узлами и системой ввода вывода. Коллективная сеть поддерживает соединения точка-точка,с передачей сообщений размером в 256 байт, которые содержат полезную информацию, 10 дополнительных байта предназначены для передачи кодов операций над данными в аппаратной логике приемного узла (ALU)l совместно с данными в самом узле и передачи результата по сети. Этот механизм используется протоколом MPI.
Сеть обработки прерываний.
Эта сеть содержит 4 независимых канала, каждый из которых соединяется с аналогичными выходами других узлов по схеме монтажного ИЛИ, таким образом формируется дерево, ветви которого объединяют 4 группы процессорных узлов. В случае запроса на прерывание на одной из ветвей формируется низкий уровень сигнала. Головной узел выставляя 1 на ветвь и используя в каждом узле ветви логику И и инверсное значение сигнала прерывания,выставленного на ветвь узлом определяет узел,выставивший этот запрос.
Сеть контроля состояния системы.
64К узлов содержит BG/L и около 250000 контрольных точек с которых снимается информация о состоянии системы. Контроль осуществляет внешний компьютер,носящий название сервисный процессор. Компьютер получает и передает информацию через сеть. На аппаратном уровне для этой цели используют специальные чипы, которые преобразуют пакеты сетевого протокола в управляющие сигналы различного рода интерфейсов, например, ITAG или i2c.
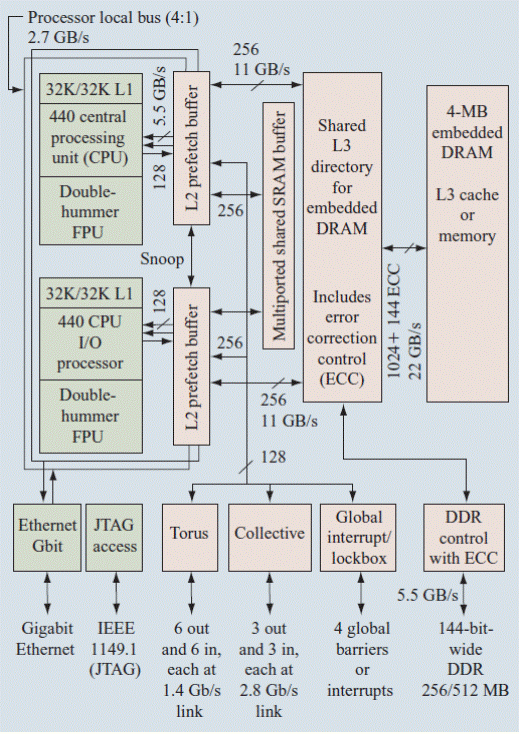
Схема двух процессорного модуля BG/L
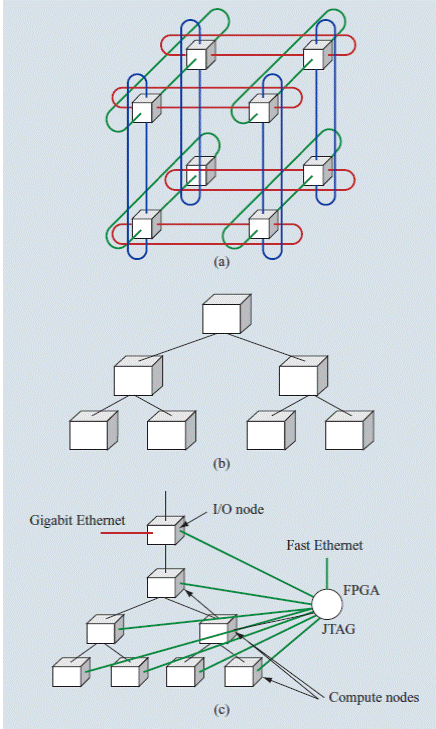
А) сеть TORUS С) сети ITAGи Gigabit ethernetи
B)глобальная коллективная сеть
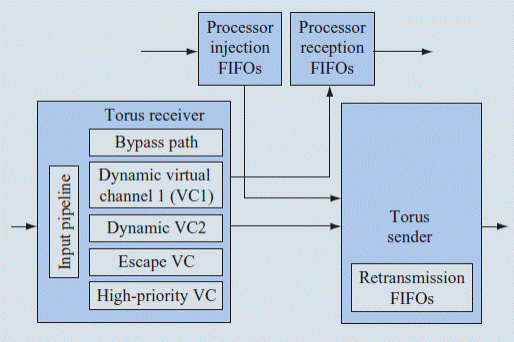
Схема пары приемник- передатчик для одного направления.
Два виртуальных канала escape и high prioritiy предназначены один для устранения блокировки в сети, а другой для высокоприоритетных пакетов.
ЛекцияN15
1.Кластерные структуры. Понятие кластера, архитектура.
Одно из самых современных направлений в области создания вычислительных систем — это кластеризация. По производительности и коэффициенту готовности кластеризация представляет собой альтернативу симметричным мультипроцессорным системам.
Кластер – группа взаимно соединенных вычислительных систем (узлов), работающих совместно, составляющих единый вычислительный ресурс и создавая у пользователя иллюзию наличия единственной ВМ.
В качестве узла кластера может выступать как однопроцессорная ВМ, так и ВС типа SMP или МРР. Важно лишь то, что каждый узел в состоянии функционировать самостоятельно и отдельно от кластера. В плане архитектуры суть кластерных вычислений сводится к объединению нескольких узлов высокоскоростной сетью. Для описания такого подхода, помимо термина «кластерные вычисления», достаточно часто применяют такие названия, как: кластер рабочих станций (workstation cluster),гипервычисления (hypercomputing),параллельные вычисления на базе сети (network-based concurrent computing),ультравычисления (ultracomputing).
Изначально перед кластерами ставились две задачи: достичь большой вычислительной мощности и обеспечить повышенную надежность ВС. Пионером в области кластерных архитектур считается корпорация DEC, создавшая первый коммерческий кластер в начале 80-х годов прошлого века.
В качестве узлов кластеров могут использоваться как одинаковые ВС (гомогенные кластеры), так и разные (гетерогенные кластеры). По своей архитектуре кластерная ВС является слабо связанной системой.
Преимущества кластеризации
Абсолютная масштабируемость. Возможно создание больших кластеров, превосходящих по вычислительной мощности даже самые производительные одиночные ВМ. Кластер в состоянии содержать десятки узлов, каждый из которых представляет собой мультипроцессор.
Наращиваемая масштабируемость. Кластер строится так, что его можно наращивать, добавляя новые узлы небольшими порциями. Таким образом, пользователь может начать с умеренной системы, расширяя ее по мере необходимости.
Высокий коэффициент готовности. Поскольку каждый узел кластера — самостоятельная ВМ или ВС, отказ одного из узлов не приводит к потере работоспособности кластера. Во многих системах отказоустойчивость автоматически поддерживается программным обеспечением.
Превосходное соотношение цена/производительность. Кластер любой производительности можно создать, соединяя стандартные «строительные блоки», при этом его стоимость будет ниже, чем у одиночной ВМ с эквивалентной вычислительной мощностью.
На уровне аппаратного обеспечения кластер — это просто совокупность независимых вычислительных систем, объединенных сетью. При соединении машин в кластер почти всегда поддерживаются прямые межмашинные связи. Решения могут быть простыми, основывающимися на аппаратуре Ethernet, или сложными с высокоскоростными сетями с пропускной способностью в сотни мегабайтов в секунду. К последней категории относятся RS/6000 SP компании IBM, системы фирмы Digital на основе Memory Channel, ServerNet корпорации Compaq.
Неотъемлемая часть кластера — специализированное программное обеспечение (ПО), на которое возлагается задача обеспечения бесперебойной работы при отказе одного или нескольких узлов. Такое ПО производит перераспределение вычислительной нагрузки при отказе одного или нескольких узлов кластера, а также восстановление вычислений при сбое в узле. Кроме того, при наличии в кластере совместно используемых дисков кластерное ПО поддерживает единую файловую систему.
Обычно различают следующие основные виды кластеров:
отказоустойчивые кластеры (High-availability clusters, HA)
кластеры с балансировкой нагрузки (Load balancing clusters)
высокопроизводительные кластеры (High-performance
Кластер Beowulf
Первым в мире кластером, по-видимому, является кластер, созданный под руководством Томаса Стерлинга и Дона Бекера в научно-космическом центре NASA – Goddard Space Flight Center – летом 1994 года. Названный в честь героя скандинавской саги, обладавшего, по преданию, силой тридцати человек, кластер состоял из 16 компьютеров на базе процессоров 486DX4 с тактовой частотой 100 MHz. Каждый узел имел 16 Mb оперативной памяти. Связь узлов обеспечивалась тремя параллельно работавшими 10 Mbit/s сетевыми адаптерами. Кластер функционировал под управлением операционной системы Linux, использовал GNU-компилятор и поддерживал параллельные программы на основе MPI. Процессоры узлов кластера были слишком быстрыми по сравнению с пропускной способностью обычной сети Ethernet, поэтому для балансировки системы Дон Бекер переписал драйверы Ethernet под Linux для создания дублированных каналов и распределения сетевого трафика.
В настоящее время под кластером типа Beowulf понимается система, которая состоит из одного серверного узла и одного или более клиентских узлов, соединенных при помощи Ethernet или некоторой другой сети. Это система, построенная из готовых серийно выпускающихся промышленных компонентов, на которых может работать ОС Linux, стандартных адаптеров Ethernet и коммутаторов. Она не содержит специфических аппаратных компонентов и легко воспроизводима. Серверный узел управляет всем кластером и является файл-сервером для клиентских узлов. Он также является консолью кластера и шлюзом во внешнюю сеть. Большие системы Beowulf могут иметь более одного серверного узла, а также, возможно, специализированные узлы, например консоли или станции мониторинга. В большинстве случаев клиентские узлы в Beowulf пассивны. Они конфигурируются и управляются серверными узлами и выполняют только то, что предписано серверным узлом.
Кластер AC3 Velocity Cluster
Кластер AC3 Velocity Cluster, установленный в Корнельском университете (США) стал результатом совместной деятельности университета и консорциума AC3 (Advanced Cluster Computing Consortium), образованного компаниями Dell, Intel, Microsoft, Giganet и еще 15 производителями ПО с целью интеграции различных технологий для создания кластерных архитектур для учебных и государственных учреждений.
Состав кластера:
64 четырехпроцессорных сервера Dell PowerEdge 6350 на базе Intel Pentium III Xeon 500 MHz, 4 GB RAM, 54 GB HDD, 100 Mbit Ethernet card;
1 восьмипроцессорный сервер Dell PowerEdge 6350 на базе Intel Pentium III Xeon 550 MHz, 8 GB RAM, 36 GB HDD, 100 Mbit Ethernet card.
Четырехпроцессорные серверы смонтированы по восемь штук на стойку и работают под управлением ОС Microsoft Windows NT 4.0 Server Enterprise Edition. Между серверами установлено соединение на скорости 100 Мбайт/c через Cluster Switch компании Giganet.
Задания в кластере управляются с помощью Cluster ConNTroller, созданного в Корнельском университете. Пиковая производительность AC3 Velocity составляет 122 GFlops при стоимости в 4 – 5 раз меньше, чем у суперкомпьютеров с аналогичными показателями.
На момент ввода в строй (лето 2000 года) кластер с показателем производительности на тесте LINPACK в 47 GFlops занимал 381-ю строку списка Top 500.
Кластер NCSA NT Supercluster
В 2000 году в Национальном центре суперкомпьютерных технологий (NCSA – National Center for Supercomputing Applications) на основе рабочих станций Hewlett-Packard Kayak XU PC workstation был собран еще один кластер, для которого в качестве операционной системы была выбрана ОС Microsoft Windows. Недолго думая, разработчики окрестили его NT Supercluster.
На момент ввода в строй кластер с показателем производительности на тесте LINPACK в 62 GFlops и пиковой производительностью в 140 GFlops занимал 207-ю строку списка Top 500.
Кластер построен из 38 двупроцессорных серверов на базе Intel Pentium III Xeon 550 MHz, 1 Gb RAM, 7.5 Gb HDD, 100 Mbit Ethernet card.
Связь между узлами основана на сети Myrinet.
Программное обеспечение кластера:
операционная система – Microsoft Windows NT 4.0;
компиляторы – Fortran77, C/C++;
уровень передачи сообщений основан на HPVM.
Кластер Thunder
Аппаратная конфигурация кластера Thunder:
1024 сервера, по 4 процессора Intel Itanium 1.4 GHz в каждом;
8 Gb оперативной памяти на узел;
общая емкость дисковой системы 150 Tb.
Программное обеспечение:
операционная система CHAOS 2.0;
среда параллельного программирования MPICH2;
отладчик параллельных программ TotalView;
Intel и GNU Fortran, C/C++ компиляторы.
На момент установки – лето 2004 года – кластер Thunder занимал 2-ю строку с пиковой производительностью 22938 GFlops и максимально показанной на тесте LINPACK 19940 Gflops.
Кластерная структура как информационная вычислительная система, предназначенная для параллельных вычислений и относящаяся к категории MIMD - много инструкций много данных была заложена еще во времена машин второго поколения и представляла многомашинный комплекс со слабыми связями. Такой многомашинный комплекс имел общее поле внешней памяти в виде дискового пространства благодаря наличию многоканального переключателя, входящего в состав каждого устройства управления дисковыми накопителями.
Для расширения функциональных возможностей многомашинного комплекса многоканальные переключатели позже стали использовать и в других контроллерах внешних устройств как,например, в ленточных и катриджных подсистемах. Возможности таких многомашинных комплексов были ограничены. Причина была в том, чтобы избежать конфликтов при одновременном доступе к общему полю дискового пространства, находящемуся в пределах одного дискового накопителя операционные системы компьютеров использовали специальные системные команды ‘резервирование’ и ‘освобождение’ прежде чем произвести обращение к общим данным в виде каталогов и таблиц. Эти команды хорошо работали при использовании лимитированных отрезков времени для связи с общим полем памяти в программных приложениях, так как в течение этих отрезков времени доступ других ЭВМ в адресное пространство этой области памяти был заблокирован.
Следующим этапом в архитектуре кластерной системы стал этап введения интерфейса канал-канал. Так, например, двух машинный комплекс имел два соединения канал-канал, через которые каждая из ЭВМ могла передавать и получать информацию от другой.
Для увеличения числа узлов в кластере пришлось использовать кольцевую топологию соединения узлов в системе. Это было сделано для того чтобы не использовать соединения каждого узла со всеми остальными, потому что пришлось бы для каждого узла в кластере с N узлами иметь N-1интерфейсов канал-канал на передачу и столько же на прием информации в системе.
В результате применения кольцевого соединения узлов в кластере расширился диапазон видов информации транслируемой по кольцу, и стала включать в себя:
сообщения об используемой и блокируемой информации на дисках. Это позволило в системе автоматически предотвращать нежелательный двойной доступ к данным
информацию об очередности работ, так что все узлы в системе могли получить работы из одной входной очереди в кластере
информацию, связанную с управлением защитой узлов в кластере
управление структурами данных на дисках, так что использование системных канальных команд резервирование и освобождение отпало само собой.
Вместо команд ‘резервирование ’и ‘освобождение’ стали использоваться ‘замки’ для разрешения или блокировки обращения к памяти.
Различают два типа замка. Так для группы областей разделяемой памяти используется, так называемый,”spin lock” и в случае его занятости рутина или процессор ждет, пока его не освободит конкурирующий узел в кластере.
Другой тип “замка” suspend lock устанавливается для отдельной области и в этом случае запрашивающий узел не ждет окончания блокировки и другая задача диспетчеризируется на выполнение.
Следует отметить введение интерфейса канал-канал и кольцевой топологии соединения узлов в кластере определило следующий уровень кластерной архитектуры и дало ему название ctcring, который в дальнейшем был модифицирован в basis sysplex.
Эта конфигурация помимо информации,передаваемой по кольцу о видах которой мы уже говорили, имела наборы управляющих данных, предназначенных для восстановления системы во время перезагрузки, находящихся в дисковой памяти и представляющих последовательность действий системы по восстановлению данных в системе во время рестарта.
И так с логической точки зрения SYSPLEX с учетом технологии виртуализации можно рассматривать как набор операционных систем, которые составляют кооперацию для аппаратной платформы, представляемой временно для функционирования отдельной операционной системе. С организацией аппаратной платформы в форме многопроцессорной системы появилась возможность организовать независимое функционирование на одной аппаратной платформе нескольких операционных систем с использованием технологии организации логических партиций, разработанной фирмой IBM для манфреймов.
Такая форма кластерной архитектуры, используемая на этих манфреймах в настоящее время, является архитектура PARALLEL SYSPLEX, но прежде чем рассматривать подробнее такую организацию кластера необходимо рассмотреть исходные принципы организации как физической, так и логической структуры кластера.
И так в простейшей форме кластер представляет собой два или более компьютеров, которые выполняют одну общую задачу. В основе идеи организации кластерных структур положена концепция объединения отельных компьютеров с целью обеспечения масштабируемости то есть увеличения компьютерной мощности и обеспечения надежности работы системы.
Кластер компьютеров является единой информационной системой то есть работа,выполняемая на одном из компьютеров должна быть скоординирована с другими задачами, выполняемыми в это время на других узлах кластера. Это обеспечивается за счет межкомпьютерных соединений в кластере (интерфейсов) как программных, так и аппаратных и дополнительно за счет использования разделяемы данных между узлами кластера через общую файловую систему.
Типы кластеров.
Как было указано ранее, кластеры могут существовать в различных формах в зависимости от целей и задач для которых проектируется кластер. Наиболее распространенные типы кластеров:
- кластеры, предназначенные для обеспечения надежности работы системы
- кластеры для высокопроизводительных вычислений
- кластеры для обеспечения возможности горизонтального масштабирования
Следует отметить, что в кластерных структурах нет четкого разделения по типам, поэтому, обычно, кластер по своим функциональным возможностям реализует признаки нескольких типов.
Высоконадежные системы.
Этот тип кластеров предназначен для обеспечения работоспособности системы в с чае выхода из строя как программных так и аппаратных средств путем увеличения функциональных узлов в системе. В простейшем варианте кластер состоит из двух компьютеров, имеющих доступ к одним и тем же программным и аппаратным средствам в системе.
Во время работы функционирует один компьютер, другой находиться в “горячем” резерве и в случае выхода из строя резервный компьютер берет на себя управление процессом вычислений.
Примером такой системы в отечественной вычислительной технике в свое время был ВК-46 –вычислительный комплекс, состоящий из двух ЭВМ ЕС-1046,объедененных в кластер связь между которыми осуществлялась через интерфейс прямого управления и через адаптеры канал-канал. Кроме того доступ к общему дисковому пространству осуществлялся благодаря наличию двухканальных переключателей в контроллерах дисковых накопителях.
Кластеры высокопроизводительных вычислений.
Высокопроизводительные кластеры используют технологии параллельных вычислений,суть которых можно определить как способность многих независимых потоков управления выполнять одновременно работу, ведущую к завершению решения задачи.
Высокопроизводительные кластеры представляют объединение большого числа компьютеров. Проектирование высокопроизводительных кластеров представляет собой задачу, включающую в себя пять основных этапов
- анализ требований, предъявляемых к кластеру
-проектирование
- внедрение
- конфигурация
- управление системой
при этом в кластере должны быть реализованы
- как организация межпроцессорных связей между узлами, так и координация параллельной загрузки задач
-конфигурирование параллельного и приоритетность высокопроизводительного доступа к файловым системам
-инсталляция
-обслуживание
-управление большим количеством компьютеров
Конечной целью проектирования высокопроизводительного кластера является представление отдельной виртуальной системы для любого процесса и задачи, при этом процесс или задача не должны иметь понятия на какие части будет она разделена для параллельной обработки, и в каких узлах кластера эти части задачи будут выполняться.
Кластеры с горизонтальным масштабированием.
Тип таких кластеров используется для обеспечения доступа к ресурсам, которые могут быть арбитражно расти как в размере так и во времени. Наиболее типичным примером такого кластера может служить архитектура вэб сервера, в котором по единственному интерфейсу приходящие запросы могут быть распределены на большое количество серверов, обеспечивающих высокую производительность обслуживания пользователей, используя такую функцию как управление загрузкой. Конечно, такой тип кластеров имеет значительную избыточность, что позволяет из множества неисправных серверов передавать запросы на функционирующий сервер, то есть эта модель имеет признаки высоконадежного кластера, а способность распределять работу среди множества узлов и признаки высокопроизводительного.
Логическая структура кластера.
Как было указано выше, кластер представляет большое число компьютеров, сконфигурированных таким образом, чтобы они могли выполнять различные функции в кластере.
Следует помнить, что ниже перечисленные функции являются логическими и некоторых случаях могут быть сконфигурированными на одном и том же компьютере, а в других случаях могут быть распределены между компьютерами в кластере.
Перечень логических функций, которые узел (компьютер) реализовать мы сейчас и рассмотрим
Функция вычислений.
Реальная вычислительная мощность кластера распределена между компьютерами, выполняющих функции вычислений. Каждому компьютеру в группе функция представляется как одно или более заданий,являющихся частью общей задачи.
Эти компьютеры логически группируются в зависимости от решаемой задачи. Наивысшими в иерархии кластера являются компьютеры, выполняющие вычислительные функции.
Функция контроля.
Компьютеры, выполняющие функции контроля обеспечивают обслуживание, которое помогает другим компьютерам в кластере функционировать совместно с целью получения конечного результата. Например
-протокол динамической конфигурации системы
- система DNS- доменные системные имена
Эти функции дают возможность новым компьютерам быть добавленными в кластер, для обеспечения связи с другими узлами кластера
-диспетчеризация заданий, которые должны быть выполнены компьютерами вычислений в кластере. Например, если компьютер вычислений закончил работу, то контролирующий может назначить ему дополнительное задание затребованной работы.
Функция памяти.
Для большинства приложений, выполняющихся в кластере, компьютеры должны иметь быстрый повторяемый и одновременный доступ к внешней памяти системы. Это может быть реализовано различными путями в зависимости от специфичности запросов, поступающих от приложений. В некоторых случаях память может быть напрямую подсоединена к компьютерам, в других случаях может быть доступна через одну или более сетей, разделяющих между собой устройства. В этом случае компьютеры, выполняющие функции управления памятью управляют только доступом к подсистемам памяти.
Функция инсталляции.
Для большинства кластеров, компьютеры вычислений могут быть реконфигурированы в связи с модернизацией или с установкой новых операционных систем. Эти компьютеры ответственные за инсталляцию во всех других узлах кластера. Они обеспечивают установку операционных систем, библиотек и всех программных приложений и механизм для удобного и быстрого процесса инсталляции или переустановки программных продуктов в кластере.
Функция управления.
Кластеры являются сложной комплексной вычислительной средой и управление ее индивидуальными компонентами очень важная задача. Компьютеры, на которые возложены функции управления обеспечивают мониторинг состоянием узлов кластера, управление событиями и аварийными ситуациями в кластере,используя для этого системные команды управления, передаваемые в узлы кластера для коррекции проблем и простые команды для осуществления таких операций как включения или выключения питания в компьютере.
Если при проектировании кластера функция управления конфигурируется только на одном компьютере, то рекомендуется использовать функцию дублирования в аппаратной части, введения политики копирования во избежании потери работоспособности кластера в случае возникновения ошибок в компьютере, реализующего функцию управления.
Функция пользовательского интерфейса.
Компьютер с функцией пользовательского интерфейса предназначен для связи кластера с внешней информационной средой и является “воротами” для доступа к кластеру. Индивидуальные узлы кластера, соединенные в первичные сети не могут быть доступны напрямую из внешней или корпоративной сети. Компьютер, выполняющий функцию пользовательского интерфейса, сконфигурирован с той целью, чтобы пользователи из внешней сети могли получить защищенный доступ в кластер для активизации запроса на выполнение задания или получения результатов вычислений выполняемой работы.
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 376; Нарушение авторских прав?; Мы поможем в написании вашей работы!