КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Корреляционный анализ. Корреляционный анализ - метод, позволяющий обнаружить зависимость между несколькими случайными величинами
|
|
|
|
Корреляционный анализ - метод, позволяющий обнаружить зависимость между несколькими случайными величинами.
Допустим, проводится независимое измерение различных параметров у одного типа объектов. Из этих данных можно получить качественно новую информацию - о взаимосвязи этих параметров. Для этого вводится коэффициент корреляции. Он рассчитывается следующим образом:
Есть массив из n точек { x1,i, x2,i }
Рассчитываются средние значения для каждого параметра:
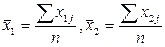
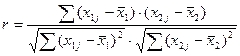 (51)
(51)
И коэффициент корреляции:
r изменяется в пределах от -1 до 1. В данном случае это линейный коэффициент корреляции, он показывает линейную взаимосвязь между x1 и x2: r равен 1 (или -1), если связь линейна.
Коэффициент r является случайной величиной, поскольку вычисляется из случайных величин. Для него можно выдвигать и проверять следующие гипотезы:
1. Коэффициент корреляции значимо отличается от нуля (т.е. есть взаимосвязь между величинами):
Тестовая статистика вычисляется по формуле:
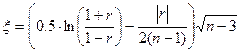
и сравнивается с табличным значением коэффициента Стьюдента t(p = 0.95, f =  ) = 1.96
) = 1.96
Если тестовая статистика больше табличного значения, то коэффициент значимо отличается от нуля. По формуле видно, что чем больше измерений n, тем лучше (больше тестовая статистика, вероятнее, что коэффициент значимо отличается от нуля)
2. Отличие между двумя коэффициентами корреляции значимо:
Тестовая статистика:
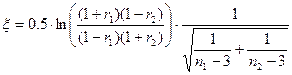
Также сравнивается с табличным значением t(p,)
Свойства коэффициента корреляции:
1. Абсолютная величина выборочного коэффициента корреляции не превосходит единицы.
2. Если выборочный коэффициент корреляции равен нулю и выборочные линии регрессии – прямые, то Х и Y не связаны линейной корреляционной зависимостью.
|
|
|
3. Если величина выборочного коэффициента корреляции равна единице, то наблюдаемые значения признаков связаны линейной корреляционной зависимостью.
4. С возрастанием абсолютной величины выборочного коэффициента корреляции линейная корреляционная зависимость становится более тесной и при ǀrǀ=1 переходит в функциональную зависимость.
В программе Excel для вычисления коэффициента корреляции применяется функции КОРРЕЛ (рис. 59), которая вычисляет коэффициент корреляции между двумя переменными измерений, когда для каждой переменной измерение наблюдается для каждого субъекта N (пропуск наблюдения для субъекта приводит к игнорированию субъекта в анализе). Корреляционный анализ иногда применяется, если для каждого субъекта N есть более двух переменных измерений. В результате выводится таблица, корреляционная матрица, показывающая значение функции КОРРЕЛ для каждой возможной пары переменных измерений.
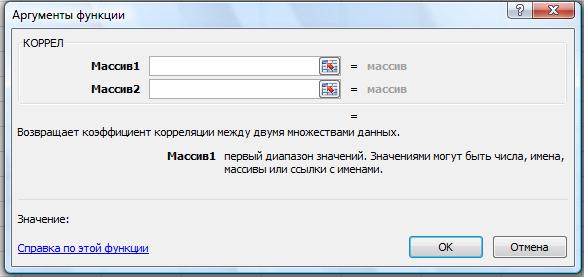
Рис. 59. Функция КОРРЕЛ
КОРРЕЛ (массив1;массив2)
Массив1 — это интервал ячеек со значениями.
Массив2 — второй интервал ячеек со значениями.
Если аргумент, который является массивом или ссылкой, содержит текст, логические значения или пустые ячейки, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
Если массив1 и массив2 имеют различное количество точек данных, то функция КОРРЕЛ возвращает значение ошибки #Н/Д.
Если какой-либо из массивов пуст или если σ (стандартное отклонение) их значений равняется нулю, функция КОРРЕЛ возвращает значение ошибки #ДЕЛ/0!.
Уравнение для коэффициента корреляции имеет следующий вид:
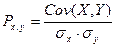
где x и y — выборочные средние значения СРЗНАЧ (массив1) и СРЗНАЧ (массив2).
Коэффициент корреляции, как и ковариационный анализ, характеризует степень, в которой два измерения «изменяются вместе». В отличие от ковариационного анализа коэффициент корреляции масштабируется таким образом, что его значение не зависит от единиц, в которых выражены переменные двух измерений (например, если вес и высота являются двумя измерениями, значение коэффициента корреляции не изменится после перевода веса из фунтов в килограммы). Любое значение коэффициента корреляции должно находиться в диапазоне от -1 до +1 включительно.
|
|
|
Корреляционный анализ дает возможность установить, ассоциированы ли наборы данных по величине, т. е. большие значения из одного набора данных связаны с большими значениями другого набора (положительная корреляция) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная корреляция), или данные двух диапазонов никак не связаны (нулевая корреляция).
В программе Excel коэффициент корреляции можно найти с помощью надстройки ПАКЕТ АНАЛИЗА (рис. 60, 61).
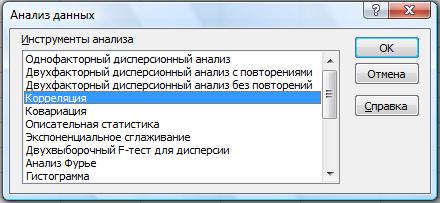
Рис. 60. Окно ПАКЕТА АНАЛИЗА
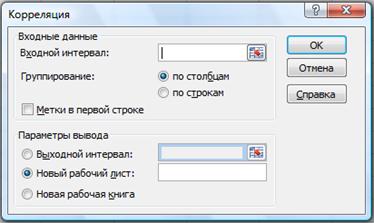
Рис. 61. Окно КОРРЕЛЯЦИЯ в ПАКЕТЕ АНАЛИЗА
Входной интервал Введите ссылку на диапазон, содержащий анализируемые данные. Ссылка должна состоять из двух или более смежных диапазонов данных, в которых данные расположены по строкам или столбцам.
Группирование В зависимости от расположения данных во входном диапазоне установите переключатель в положение по строкам или по столбцам.
Метки в первой строке/Метки в первом столбце Если первая строка входного диапазона содержит названия столбцов, установите флажок Метки в первой строке. Если названия строк находятся в первом столбце входного диапазона, установите флажок Метки в первом столбце. Если входной диапазон не содержит меток, снимите этот флажок. Необходимые заголовки в выходной таблице создаются автоматически.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Поскольку коэффициент корреляции двух наборов данных не зависит от последовательности их обработки, выходная область занимает только половину предназначенного для нее места. Ячейки выходного диапазона, имеющие совпадающие координаты строк и столбцов, содержат значение 1, т. к. каждые строка и столбец во входном диапазоне полностью коррелируют с самим собой.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
|
|
|
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
Инструменты «Корреляция» и «Ковариация» применяются для одинаковых значений, если в выборке наблюдается N различных переменных измерений. Оба вида анализа возвращают таблицу — матрицу, показывающую коэффициент корреляции или ковариационный анализ соответственно для каждой пары переменных измерений. В отличие от коэффициента корреляции, масштабируемого в диапазоне от -1 до +1 включительно, соответствующие значения ковариационного анализа не масштабируются. Оба вида анализа характеризуют степень, в которой две переменные «изменяются вместе».
Ковариационный анализ вычисляет значение функции КОВАР (рис. 62) для каждой пары переменных измерений (напрямую использовать функцию КОВАР вместо ковариационного анализа имеет смысл при наличии только двух переменных измерений, то есть при N=2). Элемент по диагонали таблицы, возвращаемой после проведения ковариационного анализа в строке i столбец i является ковариационным анализом i-ой переменной измерения с самой собой; это всего лишь дисперсия генеральной совокупности для данной переменной, вычисляемая функцией ДИСПР.
Ковариационный анализ дает возможность установить, ассоциированы ли наборы данных по величине, то есть большие значения из одного набора данных связаны с большими значениями другого набора (положительная ковариация) или наоборот, малые значения одного набора связаны с большими значениями другого (отрицательная ковариация), или данные двух диапазонов никак не связаны (ковариация близка к нулю).
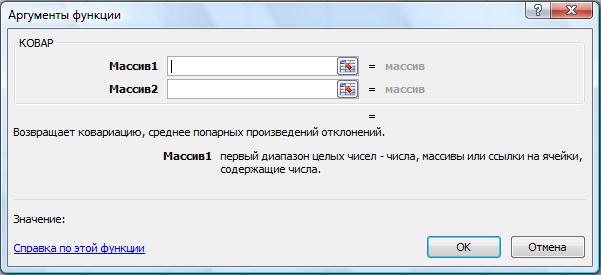
Рис. 62. Функция КОВАР
КОВАР(массив1;массив2)
Массив1 — первый массив или интервал данных.
Массив2 — второй массив или интервал данных.
|
|
|
Аргументы должны быть либо числами, либо именами, массивами или ссылками, содержащими числа.
Если аргумент, который является массивом или ссылкой, содержит тексты, логические значения или пустые ячейки, то такие значения игнорируются; однако ячейки, которые содержат нулевые значения, учитываются.
Если массив1 и массив2 имеют различное число точек данных, функция КОВАР возвращает значение ошибки #Н/Д.
Если массив1 или массив2 пуст, функция КОВАР возвращает значение ошибки #ДЕЛ/0!.
Ковариация определяется следующим образом:
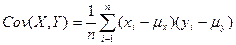
 Входной интервал Введите ссылку на диапазон, содержащий анализируемые данные. Ссылка должна состоять из двух или более смежных диапазонов данных, в которых данные расположены по строкам или столбцам.
Входной интервал Введите ссылку на диапазон, содержащий анализируемые данные. Ссылка должна состоять из двух или более смежных диапазонов данных, в которых данные расположены по строкам или столбцам.
Группирование В зависимости от расположения данных во входном диапазоне установите переключатель в положение по строкам или по столбцам.
Метки в первой строке/Метки в первом столбце Если первая строка входного диапазона содержит названия столбцов, установите флажок Метки в первой строке. Если названия строк находятся в первом столбце входного диапазона, установите флажок Метки в первом столбце. Если входной диапазон не содержит меток, снимите этот флажок. Необходимые заголовки в выходной таблице создаются автоматически.
Выходной интервал Введите ссылку на левую верхнюю ячейку выходного диапазона. Поскольку ковариация двух наборов данных не зависит от последовательности их обработки, то выходная область занимает только половину предназначенного для нее места. Диагональные ячейки выходной области содержат значения дисперсий входных диапазонов.
Новый рабочий лист Установите переключатель в это положение, чтобы открыть новый лист в книге и вставить результаты анализа, начиная с ячейки A1. При необходимости введите имя для нового листа в поле, расположенном напротив соответствующего положения переключателя.
Новая рабочая книга Установите переключатель в это положение для создания новой книги, в которой результаты будут добавлены в новый лист.
|
|
|
|
Дата добавления: 2014-01-03; Просмотров: 534; Нарушение авторских прав?; Мы поможем в написании вашей работы!