КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Висновок
MISD.
SISD.
MIMD.
SIMD.
Процесори;
Вступ
У міру того, як комп’ютери стають усе більш швидкими, може виникнути думка, що комп’ютери, у кінцевому рахунку, стануть досить швидкими, і що потреба збільшення обчислювальної потужності буде поступово зменшуватися. Однак історія розвитку комп’ютерів показує, що в міру того як нова технологія задовольняє уже відомі прикладні задачі, з’являються нові, інтерес до яких був викликаний цією технологією і які тепер вимагають розробки ще більш нової технології і так далі. Так, наприклад, перші дослідження ринку збуту фірмою Cray Research пророкували ринок у десяток суперкомп’ютерів, однак з тих пір було продано тисячі суперкомп’ютерів.
Традиційно, збільшення обчислювальної потужності мотивувалося числовими моделюваннями складних систем, таким як автомобілебудування, нафто і газовидобування, фармакологія, прогноз погоди і моделювання зміни клімату, сейсмологічна розвідка, проектування електронних та механічних пристроїв, синтез нових матеріалів, виробничі процеси, фізичні і хімічні процеси. Однак, на сьогоднішній день найбільш істотними силами, що вимагають розробки більш швидких комп’ютерів, стають комерційні додатки, для яких необхідно, щоб комп’ютер був здатний обробити величезні об’єми даних, причому використовуючи різноманіття складних методів. Ці додатки, включають бази даних (особливо, якщо вони використовуються при прийнятті рішень), відео конференції, спільні робітничі середовища, автоматизацію діагностування в медицині, розвинуту графіку і віртуальну реальність (особливо для промисловості розваг).
Хоча комерційні додатки можуть у достатній мірі визначити архітектуру більшості майбутніх паралельних комп’ютерів, традиційні наукові додатки будуть залишатися важливими споживачами паралельних обчислювальних технологій. Дійсно, оскільки нелінійні ефекти ускладнюють розуміння теоретичних досліджень, експерименти стають усе більш і більш дорогими, непрактичними чи неможливими з політичних чи яких-небудь інших причин (наприклад, США проводить ядерні іспити, використовуючи лише суперкомп’ютери), то обчислювальні дослідження складних систем стають усе більш і більш важливими. Обчислювальні витрати, звичайно, збільшуються як четвертий ступінь і навіть більше від точності обчислень. Наукові дослідження часто характеризуються великими вимогами до обсягу пам’яті, підвищеними вимогами до організації введення-введення.
1. Функціональний розподіл системи
В ЕОМ перших трьох поколінь всі обчислювальні функції реалізовувались одним процесором і інтерпретувалися ним, як арифметичні та логічні операції. Висока продуктивність системи утворилась на основі багатопроцесорних комплексів.
Використання в таких комплексах однотипних процесорів є економічно невигідним, оскільки в кожному процесорі використовується лише та частина ресурсів, яка необхідна для виконання певної операції в певний момент часу. Найбільш економічний спосіб побудови багатопроцесорних систем - це використання спеціалізованих процесорів, орієнтованих на реалізацію певних функцій: обробка скалярних величин, текстів, матрична обробка, ввід-вивід даних.
Система складається із сукупності процесорів, що мають індивідуальну та основну пам’ять.
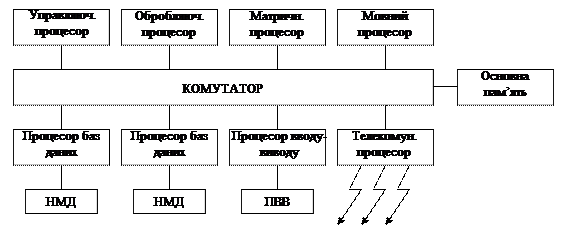
Рис.1.
Ядро системи забезпечує інформаційне спряження усіх пристроїв. Воно може бути реалізоване у вигляді системної шини комутаційного поля або комутатора основної пам’яті. Управляючий процесор виконує супервізорні функції, обробляючий - обробку числових і символьних даних, матричний - матричну і векторну обробку.
Склад процесора конкретної системи залежить від складу конкретної задачі. Обробка кожної задачі розподіляється між процесорами. Різні кроки завдань, програми і гілки програм виконуються обробляючим, матричним і мовним процесорами. Розподіл задач здійснюється управляючим процесором.
2. Паралельні обчислювальні системи
Визначень суперкомп’ютерам намагалися давати багато, іноді серйозних, іноді іронічних. Паралельний комп’ютер - це набір процесорів, здатних спільно працювати при вирішенні обчислювальних задач. Таке визначення достатньо широке, що включає як паралельні суперкомп’ютери, що мають сотні чи тисячі процесорів, так і мережі робочих станцій. Коли ця тема піднімалася в конференції comp.parallel, Кен Батчер (Ken Batcher) запропонував такий варіант: суперкомп’ютер – це пристрій, що зводить проблему обчислень до проблеми введення/виведення. Тобто те, що раніше довго обчислювалося, іноді скидаючи щось на диск, на суперкомп’ютері може виконатися миттєво, переводячи вказівники неефективності на відносно повільні пристрої введення/виведення.
Ефективність найшвидших комп’ютерів зросла майже по експоненті. Перші комп’ютери виконували кілька десятків операцій з плаваючою комою за секунду, а продуктивність паралельних комп’ютерів середини дев’яностих досягає десятків і навіть сотень мільярдів операцій у секунду, і, швидше за все цей ріст буде продовжуватися. Однак архітектура обчислювальних систем, що визначають цей ріст, змінилася радикально - від послідовної до паралельної. Ера одно процесорних комп’ютерів продовжувалася до появи сімейства CRAY X-MP / Y-MP - слабко паралельних векторних комп’ютерів з 4 - 16 процесорами, яких у свою чергу перемінили комп’ютери з масовим паралелізмом, тобто комп’ютери з чи сотнями тисячами процесорів.
Ефективність комп’ютера залежить безпосередньо від часу, необхідного для виконання базової операції і кількості базових операцій, що можуть бути виконані одночасно. Час виконання базової операції обмежений часом виконання внутрішньої елементарної операції процесора (тактом процесора). Зменшення такту обмежене фізичними межами, такими як швидкість світла. Щоб обійти ці обмеження, виробники процесорів намагаються реалізувати паралельну роботу всередині чіпа - при виконанні елементарних і базових операцій. Однак теоретично було показано, що стратегія Надвисокого Рівня Інтеграції (Very Large Scale Integration - VLSI) є дорогою, що час виконання обчислень сильно залежить від розміру мікросхеми. Поряд з VLSI для підвищення продуктивності комп’ютера використовуються й інші способи: конвеєрна обробка (різні стадії окремих команд виконується одночасно), багатофункціональні модулі (окремі множники, суматори, і т.д., управляються одним потоком команд).
Все більше і більше в ЕОМ включається більше обчислювальних блоків і відповідна логіка їхнього з’єднання. Кожен такий "обчислювальний блок" має свої власні процесор, пам’ять. Успіхи VLSI технології в зменшенні числа компонент комп’ютера, полегшують створення таких ЕОМ. Крім того, оскільки, хоча і дуже приблизно, вартість ЕОМ пропорційна числу наявних у ній компонент, то збільшення інтеграції компонент дозволяє збільшити число процесорів в ЕОМ при не дуже значному підвищенні вартості.
Інша важлива тенденція розвитку обчислень – це величезне збільшення продуктивності мереж ЕОМ. Ще недавно мережі мали швидкодію в 1.5 Mбіт/с, сьогодні вже існують мережі зі швидкодією в декілька гігабіт за секунду. Поряд із збільшенням швидкодії мереж збільшується надійність передачі даних. Це дозволяє розробляти додатки, що використовують фізично розподілені ресурси, начебто вони є частинами одного багатопроцесорного комп’ютера. Наприклад, колективне використання вилучених баз даних, обробка графічних даних на одному чи декількох графічних комп’ютерах, а вивід і управління в реальному масштабі часу на робочих станціях.
Розглянуті тенденції розвитку архітектури і використання комп’ютерів, мереж дозволяють припустити, що у майбутньому паралельність не буде участю лише суперкомп’ютерів, вона проникне і на ринок робочих станцій, персональних комп’ютерів і мереж ЕОМ. Програми будуть використовувати не тільки безліч процесорів комп’ютера, але і процесори, доступні по мережі. Оскільки більшість існуючих алгоритмів припускають використання одного процесора, то будуть потрібні нові алгоритми і програми здатні виконувати багато операцій одночасно. Наявність і використання паралелізму буде ставати основною вимогою при розробці алгоритмів і програм.
Число процесорів у комп’ютерах буде збільшуватися, отже, можна припустити, що протягом терміну служби програмного забезпечення воно буде експлуатуватися на кількості процесорів, яка постійно збільшується чи зменшується, залежно від потреб задачі. У цьому випадку можна припустити, що для захисту капіталовкладень у програмне забезпечення, масштабованість (scalability) програмного забезпечення (гнучкість стосовно зміни кількості використовуваних процесорів) буде настільки ж важлива як переносимість. Програма, здатна використовувати тільки фіксоване число процесорів, буде така ж недосконала, як і програма, здатна працювати тільки на одному типі комп’ютерів.
Помітною ознакою багатьох паралельних архітектур є те, що доступ до локальної пам’яті процесора дешевший, ніж доступ до віддаленої пам’яті (пам’яті інших процесорів мережі). Отже, бажано, щоб доступ до локальних даних був більш частим, ніж доступ до віддалених даних. Така властивість програмного забезпечення називають локальністю (locality). Поряд з паралелізмом і масштабованістю, він є основною вимогою до паралельного програмного забезпечення. Важливість цієї властивості визначається відношенням вартості віддаленого і локального звертань до пам’яті. Це відношення може варіюватися від 10:1 до 1000:1 чи більше, що залежить від відносної ефективності процесора, пам’яті, мережі і механізмів, використовуваних для розміщення даних у мережі і їх добування.
3. Моделі паралельних комп’ютерів
Із самого початку комп’ютерної ери існувала необхідність у все більш і більш продуктивних системах. В основному це досягалося в результаті еволюції технологій виробництва комп’ютерів. Поряд з цим мали місце спроби використовувати кілька процесорів в одній обчислювальній системі з розрахунку на те, що буде досягнуте відповідне збільшення продуктивності. Зараз є маса паралельних комп’ютерів і проектів їх реалізації.
Архітектури паралельних комп’ютерів можуть значно відрізнятися один від одного. Розглянемо деякі істотні поняття і компоненти паралельних комп’ютерів. Паралельні комп’ютери складаються з трьох основних компонентів:
2. модулі пам’яті;
3. комутаційна мережа.
Можна розглядати і більш детальнішу розбиття паралельних комп’ютерів на компоненти, однак, дані три компоненти найкраще відрізняють один паралельний комп’ютер від іншого.
Комутаційна мережа з’єднує процесори один з одним і іноді також з модулями пам’яті. Процесори, що використовуються в паралельних комп’ютерах, звичайно такі ж, як і процесори одно процесорних систем, хоча сучасна технологія дозволяє розмістити на мікросхемі не тільки один процесор. На мікросхемі разом із процесором можуть бути розташовані ті їх складові, які дають найбільший ефект при паралельних обчисленнях. Наприклад, мікросхема трансп’ютера поряд з 32-розрядним мікропроцесором і 64-розрядним співпроцесором арифметики з плаваючою комою, містить всередині кристальний ОЗП ємністю 4 Кбайт, 32-розрядну шину пам’яті, що дозволяє адресувати до 4 Гбайт зовнішньої, стосовно кристала пам’яті, чотири послідовних двонаправлених ліній зв’язку, що забезпечують взаємодію трансп’ютера з зовнішнім світом і працюючих паралельно з ЦПП, інтерфейс зовнішніх подій.
Однією із властивостей, що розрізняють паралельні комп’ютери, є кількість можливих потоків команд. Розрізняють наступні архітектури:
1. SIMD (Single Instruction Multiple);
2. MIMD (Multiple Instruction Multiple);
3. SISD (Single Instruction. Single Data);
4. MISD (Myltiple instruction Single date).
SIMD (Single Instruction Multiple). SIMD комп’ютер має N ідентичних синхронно працюючих процесорів, N потоків даних і один потік команд. Кожен процесор володіє власною локальною пам’яттю. Мережа, що з’єднує процесори, звичайно має регулярну топологію.
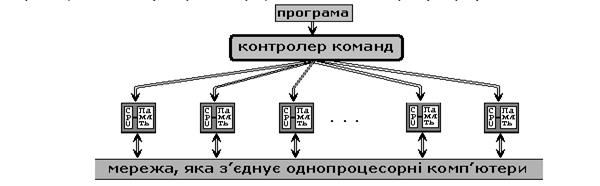
Рис.2.
Процесори інтерпретують адреси даних або як локальні адреси власної пам’яті, або як глобальні адреси, можливо, модифіковані додаванням локальної базової адреси. Процесори одержують команди від одного центрального контролера команд і працюють синхронно, тобто на кожному кроці всі процесори виконують ту саму команду над даними з власної локальної пам’яті.
Така архітектура з розподіленою пам’яттю часто згадується як архітектура з паралелізмом даних (data-parallel), тому що паралельність досягається при наявності одиночного потоку команд, що діє одночасно на декілька частин даних.
SIMD підхід може зменшити складність як апаратного, так і програмного забезпечення, але він підходить тільки для спеціалізованих проблем, що характеризуються високим ступенем регулярності, наприклад, обробка зображення і деякі числові моделювання.
· MIMD (Multiple Instruction Multiple). MIMD комп’ютер має N процесорів, N потоків команд і N потоків даних. Кожен процесор функціонує під управлінням власного потоку команд, тобто MIMD комп’ютер може паралельно виконувати зовсім різні програми.
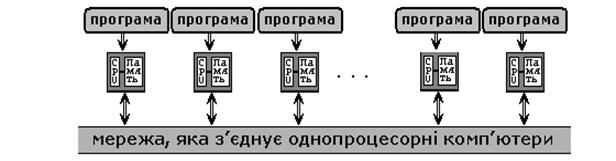
Рис.3.
MIMD архітектури далі класифікуються в залежності від фізичної організації пам’яті, способу доступу до модулів пам’яті, тобто чи має процесор свою власну локальну пам’ять і звертається до інших блоків пам’яті, використовуючи комутаційну мережа, чи комутаційна мережа об’єднує всі процесори з загальнодоступною пам’яттю. Виходячи з доступу до пам’яті, її організації, розрізняють наступні типи паралельних (MIMD) архітектур:
1. Комп"ютери з розподіленою пам"яттю (distributed memory). Кожен процесор має доступ лише до локальної, власної пам’яті. Процесори об’єднані в мережу. Доступ до віддаленої пам’яті можливий тільки за допомогою системи обміну повідомленнями. Процесор може звертатися до локальної пам’яті, може посилати й одержувати повідомлення, передані через мережу, що з’єднує процесори. Повідомлення використовуються для здійснення зв’язку між процесорами або, що є еквівалентним, для читання і запису віддалених блоків пам’яті. В ідеалізованій мережі вартість посилки повідомлення між двома вузлами мережі не залежить як від розташування обох вузлів, так і від трафіку мережі, але залежить від довжини повідомлення.
2. Комп"ютери з загальною пам"яттю (True shared memory). Всі процесори спільно звертаються до загальної пам’яті, як правило, через шину чи ієрархію шин. В ідеалізованої PRAM (Parallel Random Access Machine - паралельна машина з довільним доступом) моделі, яка часто використовується в теоретичних дослідженнях паралельних алгоритмів, будь-який процесор може звертатися до будь-якої комірки пам’яті за той самий час. У таких комп’ютерах не можна істотно збільшити число процесорів, оскільки при цьому відбувається різке збільшення числа конфліктів доступу до шини. На практиці масштабованість цієї архітектури звичайно приводить до деякої форми ієрархії пам’яті. Частота звертань до загальної пам’яті може бути зменшена за рахунок збереження копій часто використовуваних даних у кеш-пам’яті, зв’язаній з кожним процесором. Доступ до цієї кеш-пам’яті набагато швидший, ніж безпосередній доступ до загальної пам’яті.
3. Комп’ютери з віртуально спільною пам’яттю (Virtual shared memory). У таких системах загальна пам’ять, як така, відсутня. Кожен процесор має власну локальну пам’ять. Він може звертатися до локальної пам’яті інших процесорів, використовуючи “глобальну адресу”. Якщо “глобальна адреса” вказує не на локальну пам’ять, то доступ до пам’яті реалізується за допомогою повідомлень з малою затримкою, що пересилаються по мережі, яка з’єднує процесори.
Одиночний потік команд – одиночний потік даних
ПК – пристрій керування
ПЕ – процесорний елемент
ПД – пам’ять даних
Так як машина дає потік команд. Тільки 1-н потік команд і тільки один потік даних. Всі команди обробляють послідовно одна за одною. Кожна команда ініціює тільки одну скалярну операцію. До машин цього класу відносяться звичайні послідовні машини РDР 11, VAX 17, IBM – перші сумісні комп’ютери.
Це визначення обумовлює наявність в архітектурі комп’ютера багатьох процесорів, які здійснюють операції обчислення над одним і тим самим потоком даних. Хоча теоретично такий клас машин існує, на практиці практично не було створено жодної машини з такою архітектурою. Окремі дослідники відносять векторно-конвеєрні машини до цього класу. Однак це не підтримується більшістю науковців виробників в даній предметній області.
Ця класифікація є одною з широко вживаних і використовується при початковій характеристиці того чи іншого комп’ютера. Однак в неї є певні недоліки:
1) деякі класи машин важко підвести під одну із цих чотирьох груп, зокрема векторно конвеєрні комп’ютери.
2) практично всі машини відносяться до класу MIMD. Тому існують декілька інших класифікацій, які:
а) додатково класифікується клас МІМD (класифікація Р. Хокні)
б) класифікація по критеріях кількості біт в машинному слові комп’ютера і кількості слів, які паралельна машина здатна обробити за одиницю часу (класифікація Т. Фена)
в) класифікують і описують в якому вигляді можливості паралельної і конвеєрної обробки даних (класифікація В. Хендлера)
г) розділяють етапи вибірки і виконання в потоках команди даних (класифікація Л. Шнайдера)
д) розглядають архітектуру любого комп’ютера, як абстрактну структуру, що складається з чотирьох компонентів:
- процесор команд
- процесор даних
- ієрархія пам’яті
- перемикач для зв’язку між процесорами і пам’яттю(класифікація Скілікорна)
Флінт виділяє чотири типи архітектури обчислювальних систем:
1. SISD. Single Instruction. Single Data Одиночний потік команд – одиночний потік даних ПК – пристрій керування ПЕ – процесорний елемент ПД. – пам’ять даних Так як машина дає потік команд. Тільки 1-н потік команд і тільки один потік даних. Всі команди обробляють послідовно одна за одною. Кожна команда ініціює тільки одну скалярну операцію. До машин цього класу відносяться звичайні послідовні машини РDР 11, VAX 17, IBM – перші сумісні комп’ютери.
2. SIMD. Single instruction Multiple Data – множинний одиночний потік команд – множинний потік даних В цій архітектурі зберігається один потік команд, який має на відміну від попереднього класу векторні команди. Це дозволяє виконати один ариф, операцій відразу над багатьма даними, наприклад над елементами вектора. До цих машин відносяться машини ILLIAC -4, KRAY -1 3. MISD. Myltiple instruction Single date – множинний потік інструкцій, одиночний потік даних Це визначення обумовлює наявність в архітектурі комп’ютера багатьох процесорів, які здійснюють операції обчислення над одним і тим самим потоком даних. Хоча теоретично такий клас машин існує, на практиці практично не було створено жодної машини з такою архітектурою. Окремі дослідники відносять векторно-конвеєрні машини до цього класу. Однак це не підтримується більшістю науковців виробників в даній предметній області. 4.MIMD. Myltiple instraktion Multiple Date – множинний потік команд – множинний потік даних Це клас обчислювальних машин має декілька пристроїв обробки даних (декілька процесорів), які з’єднані в один комплекс, і які працюють кожен в свій потік команд з своїм потоком даних. Як видно під визначення цього класу попадає більшість паралель них машин, що створені і створюються зараз в світі.
Ця класифікація є одною з широко вживаних і використовується при початковій характеристиці того чи іншого комп’ютера. Однак в неї є певні недоліки:
1. Деякі класи машин важко підвести під одну із цих чотирьох груп, зокрема векторно конвеєрні комп’ютери.
2. Практично всі машини відносяться до класу MIMD. Тому існують декілька інших класифікацій, які: а) додатково класифікується клас МІМD (класифікація Р. Хокні) б) класифікація по критеріях кількості біт в машинному слові комп’ютера і кількості слів, які паралельна машина здатна обробити за одиницю часу (класифікація Т. Фена) в) класифікують і описують в якому вигляді можливості паралельної і конвеєрної обробки даних (класифікація В. Хендлера) г) розділяють етапи вибірки і виконання в потоках команди даних (класифікація Л. Шнайдера) д) розглядають архітектуру любого комп’ютера, як абстрактну структуру, що складається з чотирьох компонентів: - процесор команд - процесор даних - ієрархія пам’яті - перемикач для зв’язку між процесорами і пам’яттю(класифікація Скілікорна).
4. Продуктивність паралельних комп’ютерів
Необхідність оцінювання продуктивності комп’ютерів виникла з початку їх виникнення. Основна задача оцінювання - знайти оптимальний критерій для визначення ефективності роботи, що буде універсальним для вибору комп’ютера.
Однією з одиниць оцінки продуктивності є пікова продуктивність, тобто кількість операцій, що виконує комп’ютер у найбільш сприятливих умовах (конвеєри заповнені, дані в регістрах, немає конфліктів з пам’яттю). Проте пікова продуктивність - це лише теоретичний показник. На одних задачах продуктивність може досягати до пікової продуктивності, а на інших задачах буде досягати лише 2% пікової продуктивності.
Користувача цікавить, наскільки продуктивно комп’ютер буде працювати на його програмах, тому показник пікової продуктивності не є універсальним при виборі комп’ютера.
Ще один спосіб оцінки продуктивності - це обрахунок кількості операцій за секунду. Вимірюється в МІРS-ах. Для визначення цього показника достатньо порахувати кількість операцій процесора за одиницю часу. Цей показник також не є універсальним, так як кожний процесор має свій власний набір інструкцій і програма користувача може на різних процесорах утворювати різну кількість операцій. Наприклад, операція а+b на процесорах Intel буде потребувати 3 мікрооперації, 2 з яких - зчитування значень з пам’яті, а третя - безпосередньо додавання. На інших процесорах ця операція може мати іншу кількість мікрооперацій.
Інший приклад - комп’ютер ILLIAC IV. Продуктивність комп’ютера - 10 мільярдів операцій/с. проте продуктивність досягалась тільки при роботі з даними розмірності "байт". На більших розмінностях продуктивність різко падала. Ще один недолік використання даного показника - це неможливість точного вимірювання продуктивності з використанням співпроцесора. Якщо співпроцесор існує, то всі операції з плаваючою комою покладаються на нього, тобто головний процесор виконує меншу кількість операцій. Якщо ж співпроцесора немає, то головний процесор регулює його роботу, тобто починає виконувати велику кількість операцій для виконання дій з плаваючою комою, тобто фактично кількість збільшується. Виникає протиріччя: з використанням співпроцесора кількість інструкцій зменшується, а отже, продуктивність зменшується, проте операції з плаваючою комою виконуються швидко; а коли співпроцесора немає, кількість інструкцій за секунду велика, а отже, продуктивність велика, проте реально операції над числами з плаваючою комою виконуються повільніше.
Отже, при оцінці продуктивності комп’ютерних систем не варто користуватися лише апаратними показниками, потрібно також враховувати програмно-апаратне середовище. На основі деяких критеріїв формуються еталонні тестові програми, які при запуску на кожній комп’ютерній системі показують продуктивність даної системи. Ці програми називають benchmark.
Однією з найпопулярніших тестових програм є тест LINPACK, який для тестового завдання розв’язує систему рівнянь із щільною матрицею. Спочатку в цьому тесті розв’язується система із ста рівнянь. Проте продуктивність сучасних систем є настільки великою, що дана система рівнянь вирішується надзвичайно швидко і оцінити продуктивність стає неможливо. Тому дана програма поставляється з відкритим кодом і кожен користувач може змінювати розмірність матриці.
Також існує ще ряд тестових програм, наприклад STREAM для тестування векторних операцій, LFK, PERFECT та багато інших. Проте жоден з цих тестів не покаже реальну продуктивність системи. Тому потрібно проводити комплексне тестування системи, також потрібно чітко розуміти призначення комп’ютерної системи та які задачі вона буде вирішувати.
Системи із спільною пам’яттю
Паралельні ПК із спільною пам’яттю
Комп’ютери даного класу відповідно мають переваги та недоліки.
Переваги:
простота програмування;
спільний адресний простір;
простота роботи;
Недоліки:
невелика кількість процесорів;
дуже велика вартість;
Щоб збільшити кількість процесорів, але при цьому залишити єдиний адресний простір, пропонується декілька архітектур. Найпопулярніша з них - СС VNUMA.
В даній архітектурі фізична пам’ять є фізично розподіленою, але на логічному рівні - це її єдиний адресний простір. Також дана архітектура вирішує проблему когерентності кешів і забезпечує повну сумісність з комп’ютерами SMP.
Приклад архітектури СС VNUMA будемо розглядати на комп’ютері ИP Saperdome. Він випущений в 2000 році. Максимальна конфігурація може включати до 64 процесорів, максимальна кількість оперативної пам’яті - 256Гб, розширення - до 1Тб.
Основу архітектури складають обчислювальні коди, зв’язані між собою ієрархічною системою перемикачів. Кожна комірка - це мультипроцесор, на якому розміщені всі необхідні компоненти. Кожна комірка може містити до 4 процесорів, оперативна пам’ять - до 16Мб.
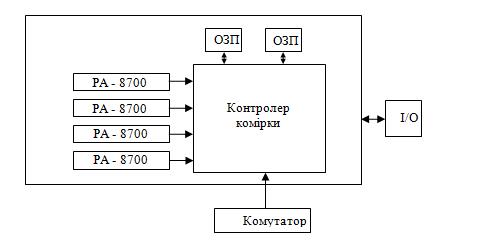
Рис.4.
Центральне місце в комірці займає контролер комірки. Це дуже складний пристрій, який складається з 24 млн транзисторів. Контролер зв’язаний з кожним процесором через окремий порт. Швидкість обміну даних - 2Гбіт/с. Також контролер слідкує за когерентністю кеш - пам’яті процесора. Пам’ять комірки може мати ємність від 2Гб і конструкцію поділено на 2 банки, що зв’язані з контролером комірки через окремі порти з швидкістю передачі інформації - 2Гбіт/с. Система введення/виведення включає в себе PCI - слоти. Окремий порт комірки зв’язаний з комутатором, через який відбувається зв’язок з іншими комірками.
При повній конфігурації ПК HP Superdome складається з двох стійок:
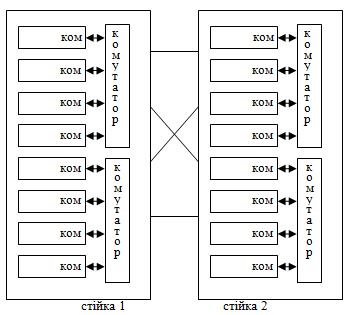
Рис.5.
Самі комутатори зв’язані між собою, а також мають по одному порту для розширення системи. Швидкість обміну даними - 8Гб/с.
Одним з центральних питань використання архітектури СС VNUMA є різниця в часі звернення. В комп’ютерах HP Superdome є 3 види затримки:
процесор і пам’ять знаходяться в одній комірці - затримка мінімальна;
процесор і пам’ять знаходяться в різних комірках, під’єднані до одного комутатора - затримка середня;
процесор і пам’ять розміщені в різних комірках, комірки під’єднані до різних комутаторів - затримка максимальна.
Тому при написанні програми для даного комп’ютера потрібно уникати можливості розпорідного звернення до пам’яті. Також даний комп’ютер має ряд особливостей:
він може працювати як єдиний класичний ПК, а можна його скорегувати так, щоб розбити на декілька частин, кожна з яких називається n Portition, вона може працювати під окремою операційною системою;
"гаряча" заміна усіх компонентів системи;
ефективна робота з великою кількістю периферійних пристроїв;
резервування;
моніторинг всіх параметрів системи.
Розглянемо процесор РА-8700. його тактова частота - 750МГц., володіє суперскалярною архітектурою і витрачає 4 такти на виконання однієї операції. Іншими словами, пікова продуктивність даного процесора - 3 ГФлопс, а всієї 64-процесорної системи - 192 ГФл. Процесор РІ 8700 на кожному такті виконує стільки операцій, скільки йому дозволяє інформаційна структура коду, а також кількість вільних функціональних пристроїв. Всього пристроїв в процесорі є 10.4 з них - для виконання арифметичних операцій над цілими числами; 4 - над дробовими і 2 функціональні пристрої - для проведення запису/читання. Починаючи з процесорів РІ 8500, кеш І рівня розміщується на кристалі процесора і досягає об’єму 2,25 Мб. При складанні програм для комп’ютерів даного класу можуть виникнути проблеми, що характерні для усіх типів паралельних комп’ютерів. А саме, неможливість розпаралелення фрагментів коду, тобто, якщо 25% коду - це послідовні операції, то збільшення швидкодії більш ніж у 5 разів досягнути нереально. Також потрібно звертати увагу на неоднорідність звернень до пам’яті.
5. Моделі паралельних обчислень
Паралельне програмування представляє додаткові джерела складності - необхідно явно управляти роботою тисяч процесорів, координувати мільйони міжпроцесорних взаємодій. Для того, щоб вирішити задачу на паралельному комп’ютері, необхідно розподілити обчислення між процесорами системи так, щоб кожен процесор був зайнятий вирішенням частини задачі. Крім того, бажано, щоб як можна менший обсяг даних пересилався між процесорами, оскільки комунікації значно повільніші операції, ніж обчислення. Часто виникають конфлікти між ступенем розпаралелювання й обсягом комунікацій, тобто чим між більшою кількістю процесорів розподілена задача, тим більший обсяг даних необхідно пересилати між ними. Середовище паралельного програмування повинне забезпечувати адекватне управління розподілом і комунікаціями даних.
Через складність паралельних комп’ютерів і їх істотної відмінності від традиційних однопроцесорних комп’ютерів, не можна просто скористатися традиційними мовами програмування й очікувати отримання високої продуктивності. Основні моделі паралельного програмування:
· процес/канал (Process/Channel);
· обмін повідомленнями (Message Passing);
· паралелізм даних (Data Parallel);
· загальної пам’яті (Shared Memory).
6. Поняття і термінологія паралельного програмного забезпечення
Код, що виконується на одиночному процесорі паралельного комп’ютера, знаходиться в деякому ж програмному середовищі, що і середовище однопроцесорного комп’ютера з мультипрограмною операційною системою, тому й у контексті паралельного комп’ютера так само говорять про процеси чи задачі, посилаючись на код, що виконується всередині захищеного регіону пам’яті операційної системи. Багато дій паралельної програми включають звертання до віддалених процесорів чи комірок загальної пам’яті. Для виконання цих дій може бути необхідна суттєва затрата часу, особливо, стосовно часу виконання звичайних команд процесора. Тому більшість процесорів виконує більше одного процесу одночасно, і, отже, у програмному середовищі окремо узятого процесора паралельного комп’ютера використовуються звичайні методи мультипрограмування:
· процеси блокуються, коли їм необхідно звернутися до віддалених ресурсів;
· процеси готові продовжити роботу, якщо отримана відповідна відповідь.
Виконання процесів паралельної програми переривається значно частіше, ніж процесів, що працюють у послідовному середовищі, тому що процеси паралельної програми виконують ще дії, пов’язані з обміном даними між процесорами. Маніпулювання повноваговими процесами у мультипрограмному середовищі є надто дорогим заняттям, оскільки воно тісно пов’язане з управлінням і захистом пам’яті. Внаслідок цього більшість паралельних комп’ютерів використовує легковагові процеси, що називаються нитками (threads) або потоками (streams) управління, а не повновагові процеси. Легковагові процеси не мають власних захищених областей пам’яті (хоча можуть володіти власними локальними даними), що в результаті дуже сильно спрощує маніпулювання ними. Більш того, їхнє використання більш безпечне.
Щоб уникнути плутанини, використовують наступні терміни, що позначають різні варіанти процесів виконання програм:
· легковагові процеси іменують нитками, потоками управління, співпроцесами;
· задачі будуть вказувати на повновагові процеси, тобто процеси операційної системи, що володіють власними захищеними регіонами пам’яті.
Процес використовується там, де поділ на легковагові і повновагові процеси несуттєвий і можна використовувати як ті, так і інші.
Відповідно до можливостей паралельного комп’ютера, процеси взаємодіють між собою одним з наступних способів:
· Обмін повідомленнями (message passing). Процес, що посилає, формує повідомлення з заголовком, у якому вказує, який процесор повинний прийняти повідомлення, і передає повідомлення в мережу, що з’єднує процесори. Якщо після передачі повідомлення у мережу процес, що посилає, продовжує роботу, то такий вид відправлення повідомлення називається неблокуючим (non-blocking send). Якщо ж процес, що посилає чекає, поки приймаючий процес не прийме повідомлення, то такий вид відправлення повідомлення називається блокуючим (blocking send). Приймаючий процес повинен знати, що йому необхідні дані і повинен вказати, що він готовий одержати повідомлення, виконавши відповідну команду прийому повідомлення. Якщо очікуване повідомлення ще не надійшло, то приймаючий процес припиняється доти, поки повідомлення не надійде.
· Обмін через загальну пам’ять (Transfers through shared memory). В архітектурах із загальнодоступною пам’яттю процеси зв’язуються між собою через загальну пам’ять - процес, що посилає, поміщає дані у відомі комірки пам’яті, з яких приймаючий процес може зчитувати їх. При такому обміні складність представляє процес виявлення того, коли безпечно поміщати дані, а коли видаляти їх. Найчастіше для цього використовуються стандартні методи операційної системи, такі семафори (semaphore) або блокування процесів. Однак це дорого і сильно ускладнює програмування. Деякі архітектури надають біти зайнято/вільно, зв’язані з кожним словом загальної пам’яті, що забезпечує легкий та високоефективний спосіб синхронізації відправників і приймачів.
· Прямий доступ до вилученої пам’яті (Direct remote-memory access). У перших архітектурах з розподіленою пам’яттю робота процесорів переривалася щораз, коли надходив який-небудь запит від мережі, що з’єднує процесори. У результаті процесор погано використовувався. Потім у таких архітектурах у кожному процесорному елементі стали використовувати пари процесорів - один процесор (обчислювальний), виконує програму, а іншої (процесор обробки повідомлень) обслуговує повідомлення, що надходять з мережі чи у мережу. Така організація обміну повідомленнями дозволяє розглядати обмін повідомленнями як прямий доступ до віддаленої пам’яті, до пам’яті інших процесорів. Така гібридна форма зв’язку, що застосовується в архітектурах з розподіленою пам’яттю, має багато властивостей архітектур із загальною пам’яттю.
Розглянуті механізми зв’язку необов’язково використовуються тільки безпосередньо на відповідних архітектурах. Так легко промоделювати обмін повідомленнями, використовуючи загальну пам’ять, з іншої сторони можна змоделювати загальну пам’ять, використовуючи обмін повідомленнями. Останній підхід відомий як віртуальна загальна пам’ять.
Найбільш бажаними (навіть скоріше обов’язковими) ознаками паралельних алгоритмів і програм є:
· паралелізм – вказує на здатність виконання безлічі дій одночасно, що істотно для програм, які виконуються на декількох процесорах;
· маштабованість – інша найважливіша ознака паралельної програми, що вимагає гнучкості програми стосовно зміни числа процесорів, оскільки найбільше ймовірно, що їх кількість буде постійно збільшуватися у більшості паралельних середовищ і систем;
· локальність – характеризує необхідність того, щоб доступ до локальних даних був більш частим, чим доступ до віддалених даних. Важливість цієї властивості визначається відношенням вартості віддаленого і локального звертань до пам’яті. Воно є ключовим до підвищення ефективності програм на архітектурах з розподіленою пам’яттю;
· модульність – відбиває ступінь розкладання складних об’єктів на більш прості компоненти. У паралельних обчисленнях це настільки ж важливий аспект розробки програм, як і в послідовних обчисленнях.
Існують декілька класифікацій архітектури комп’ютерів, але традиційно використовують схему, представлену Michal J. Flynn, відповідно до якої паралельні обчислювальні системи поділяються на два великих класи:
· SIMD (single instruction – multiple data);
· MIMD (multiple instruction – multiple data).
Розвиток паралельних обчислень пройшов етапи конвейєрно-векторних суперобчислень, паралельних обчислень на множині процесорів, зв’язаних комунікаційним середовищем передачі повідомлень і в даний час освоюються суперобчислення на системах з мікропроцесорів з кеш-пам’ятями і розділюваної (логічно – загальної) фізично розподіленою основною пам’яттю.
Існуючі паралельні обчислювальні засоби класу MIMD утворять три підкласи:
1. симетричні мультипроцесори (SMP);
2. кластери;
3. масово паралельні системи (MPP).
В основі цієї класифікації лежить структурно-функціональний підхід. Симетричні мультипроцесори складаються із сукупності процесорів, що мають однакові можливості доступу до пам’яті і зовнішніх пристроїв і функціонують під управлінням однієї операційної системи. Частинним випадком SMP є однопроцесорні комп’ютери. Усі процесори SMP мають розділювану загальну пам’ять з єдиним адресним простором.
Використання SMP забезпечує наступні можливості:
· маштабування додатків при низьких початкових витратах;
· створення додатків у звичних програмних середовищах;
· програмування на базі розділюваної пам’яті;
· однаковий час доступу до всієї пам’яті;
· можливість пересилання повідомлень з великою пропускною здатністю;
· підтримку когерентності сукупності кешів і блоків основної пам’яті, неподільні операції синхронізації і блокування.
Однак ступінь маштабованості SMP систем обмежений через неможливість технічної реалізації однакового для великої кількості процесорів доступу до пам’яті зі швидкістю, характерною для однопроцесорних комп’ютерів. Як правило, кількість процесорів у SMP не перевищує 32.
Для побудови систем з великим числом процесорів застосовуються кластерний чи МРР підходи. Обидва ці напрямки використовують SMP як системоутворюючий обчислювальний модуль.
Список літератури
1. Руденко В.Д.,Макарчук О.М.,Патланжоглу М.О.Практичний курс інфор-матики.-К.:Фенікс,2005.-304 с.
2. Кулаков Ю.А.,Луцкий Г.М. Компъютерные сети / Учебное пособие.-К.: Юниор,2005.-384с.
3. Клименко О.Ф. та інші “Інформатика та комп’ютерна техніка”.Навчальнийпосібник – К: КНЕУ. 2006.
4. Коуров Л.В. Информационные технологии. Минск, "Амалфея", 2005, с.116-143.
5. www.wikipedia.org.ua
|
|
Дата добавления: 2015-08-31; Просмотров: 1825; Нарушение авторских прав?; Мы поможем в написании вашей работы!