КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Структурные особенности процессоров со структурой Nehalem
|
|
|
|
Структуры несимметричных МВС с фирмы Intel
При разработке процессоров Nehalem изначально был избран модульный подход — был разработан набор базовых "кирпичей", которые можно собирать, чтобы создавать разные версии структуры (рис. 3).
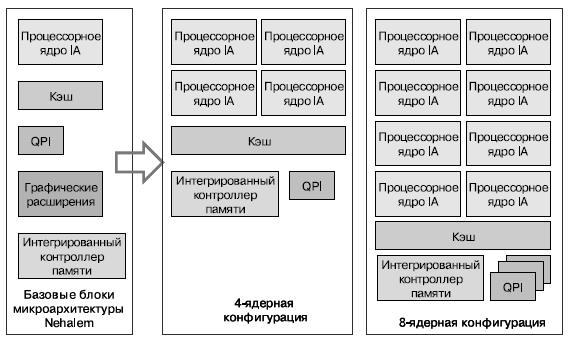
Рис. 3. Модульный подход к реализации структуры Nehalem
Базовая структура следующая: многоядерный процессор, использующий три уровня кэш-памяти, встроенный контроллер памяти, а также высокопроизводительная система интерфейсов "точка-точка" для связи с периферией и другими процессорами в многопроцессорной конфигурации.
Многопоточность реализована по технологии Hyper-Threading. Технология Hyper-Threading позволяет использовать параллелизм на уровне потоков, чтобы оптимизировать нагрузку исполнительных блоков ядра, в результате чего на уровне приложений одно физическое ядро превращается в два виртуальных.
Чтобы поддерживать параллельное выполнение потоков, некоторые ресурсы, такие как регистры, дублированы. Другие ресурсы совместно используются двумя потоками, сюда входит вся логика внеочередного выполнения (буфер изменения порядка инструкций (instruction reorder buffer), исполнительные блоки и кэш). В процессоре доступно шесть исполнительных блоков, которые способны одновременно выполнять три операции работы с памятью и три операции вычисления. Если устройство выполнения не сможет обеспечить параллелизм инструкций на должном уровне, с загрузкой всех блоков, в конвейере появляются так называемые "пузырьки" — холостые такты (рис. 8).
SMT пытается обеспечить параллелизм инструкций из двух потоков, а не из одного, с целью максимально уменьшить число холостых тактов. Этот подход оказывается очень эффективным, когда два потока связаны с заданиями разной природы. С другой стороны, если два потока выполняют, например, интенсивные вычисления, это лишь увеличит нагрузку на те же самые вычислительные блоки, которые будут бороться между собой за доступ к кэшу. SMT в данной ситуации может даже негативно повлиять на производительность.
|
|
|
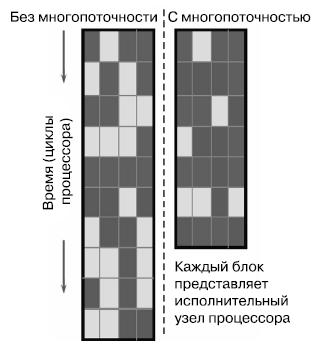
Рис. 8. Параллельное выполнение инструкций
В большинстве ситуаций влияние SMT на производительность — положительное, а себестоимость технологии по ресурсам невысокая, что и объясняет ее возвращение.
Для связи процессоров в многопроцессорной системе применяется технология под названием QuickPath Interconnect (QPI). Интерфейс QPI аналогичен интерфейсу HyperTransport, который уже на протяжении ряда лет используется в платформах фирмы AMD. На рис. 10 приведена функциональная схема QuickPath Interconnect.
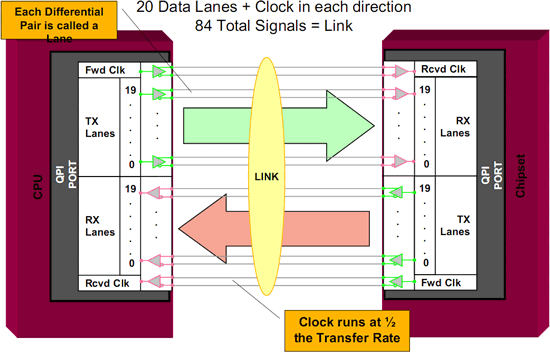
Рис. 10. Функциональная схема QuickPath Interconnect
С технической точки зрения интерфейс QPI является двунаправленным с двумя 20-битными шинами, по одной на каждое направление, из которых 16 зарезервировано под данные, а оставшиеся четыре — под функции исправления ошибок или служебную информацию протокола. Это дает максимальную скорость 6,4 GT/s (млрд передач в секунду) или полезную пропускную способность 12,8 Гбайт/с, как на чтение, так и на передачу.
Интерфейс QPI предназначается для передачи данных на периферию а также для связи между несколькими процессорами в многосокетной конфигурации.
Число доступных интерфейсов QPI меняется в зависимости от ориентации на тот или иной сегмент рынка — от одного интерфейса для связи с чипсетом в односокетных конфигурациях до четырех для четырех-, восьмисокетных серверов. Это позволяет создавать полносвязные четырех-, восьмисокетные системы В четырехсокетной системе каждый процессор может получать доступ к любой области памяти через один «прыжок» (hop) QPI, поскольку каждый процессор напрямую подключен к трем остальным (рис. 10).
|
|
|
Наиболее производительная конфигурация процессора имеет встроенный трехканальный контроллер оперативной памяти DDR3. Встроенный контроллер памяти существенно снижает задержки доступа к памяти.
В предыдущих моделях процессоров фирмы Intel контроллер оперативной памяти находился в «северном» мосту и при добавлении в систему нового процессора доступная пропускная способность системы оставалась прежней.
При наличии встроенного в процессор многоканального контроллера оперативной памяти каждый новый дополнительный процессор увеличивает как емкость, так и пропускную способность оперативной памяти.
Доступ к локальной памяти производиться с самыми низкими задержками и самой высокой пропускной способностью. Доступ к удаленной памяти происходит через промежуточный интерфейс QPI, снижающий производительность (рис. 11).
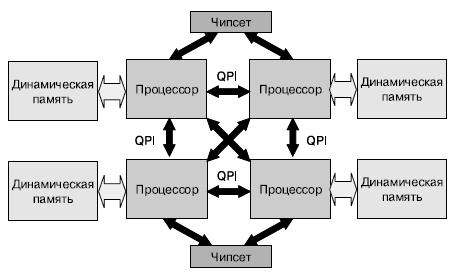
Рис. 11. Пример построения системы на нескольких процессорах
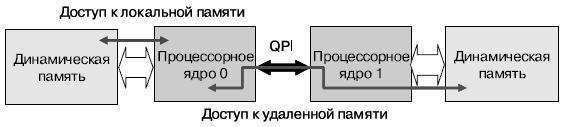
Рис. 12. Варианты доступа к памяти
Влияние на производительность предсказать сложно, поскольку все зависит от приложения и операционной системы. Фирма Intel утверждает, что падение производительности при удаленном доступе по задержкам составляет около 70%, а пропускная способность снижается в два раза по сравнению с локальным доступом. Даже при удаленном доступе через интерфейс QPI задержки будут ниже, чем на предыдущих поколениях процессоров, где контроллер находился на северном мосту.
В процессорах имеется кэш-память трех уровней. Структура кэш-памяти в процессорах со структурой Nehalem приведена на рис. 13.

Рис. 13. Структура кэш-памяти в процессорах со структурой Nehalem
Кэш-память третьего уровня является инклюзивной: она содержит все записи из кэшей L1 и L2, таким образом, снижая трафик запросов.
Примечание. Инклюзивный кэш означает, что содержимое каждого кэша более низкого уровня является подмножеством содержимого кэша более высокого уровня.
Если ядро попытается получить доступ к данным и они отсутствуют в кэше L3, то нет необходимости искать данные в собственных кэшах других ядер — там их нет. Напротив, если данные присутствуют, четыре бита, связанные с каждой строчкой кэш-памяти (один бит на ядро), показывают, могут ли данные потенциально присутствовать (потенциально, но без гарантии) в нижнем кэше другого ядра, и если да, то в каком.
|
|
|
Эта техника весьма эффективна для обеспечения когерентности персональных кэшей каждого ядра, поскольку она уменьшает потребность в обмене информацией между ядрами.
Для МВС выпускаются четырех- и восьмиядерные процессоры со структурой Nehalem. Наиболее производительными процессорами (по состоянию на начало 2011 г.) являются процессоры линии Xeon Е7.
Основные их особенности:
содержат 8 вычислительных ядер:
обеспечивают обработку до 16 потоков одновременно за счет технологии Hyper-threading;
4 контроллера Quick Path Interconnect;
обеспечивают возможность создания 2-х, 4-х и 8-ми сокетных систем;
24 Мбайта общего кэша третьего уровня;
интегрированный четырехканальный контроллер оперативной памяти стандарта DDR3;
реализована технология автоматического разгона Intel Turbo Boost;
расширяемые буфер памяти и каналы оперативной памяти;
пропускная способность в 9 раз выше по сравнению с решениями предыдущего поколения;
поддерживают до 16 слотов оперативной памяти на один сокет. Общий объем адресуемой оперативной памяти – до 2 Тбайт;
в составе свыше 2 млрд. транзисторов;
производятся по 32 нм технологическому процессу.
Процессоры Xeon Е7 примерно на 40% быстрее процессоров Xeon 7500, которые имеют аналогичную структуру, но производятся по 45 нм технологическому процессу.
|
|
|
|
|
Дата добавления: 2014-01-04; Просмотров: 423; Нарушение авторских прав?; Мы поможем в написании вашей работы!