КАТЕГОРИИ:
Архитектура-(3434)Астрономия-(809)Биология-(7483)Биотехнологии-(1457)Военное дело-(14632)Высокие технологии-(1363)География-(913)Геология-(1438)Государство-(451)Демография-(1065)Дом-(47672)Журналистика и СМИ-(912)Изобретательство-(14524)Иностранные языки-(4268)Информатика-(17799)Искусство-(1338)История-(13644)Компьютеры-(11121)Косметика-(55)Кулинария-(373)Культура-(8427)Лингвистика-(374)Литература-(1642)Маркетинг-(23702)Математика-(16968)Машиностроение-(1700)Медицина-(12668)Менеджмент-(24684)Механика-(15423)Науковедение-(506)Образование-(11852)Охрана труда-(3308)Педагогика-(5571)Полиграфия-(1312)Политика-(7869)Право-(5454)Приборостроение-(1369)Программирование-(2801)Производство-(97182)Промышленность-(8706)Психология-(18388)Религия-(3217)Связь-(10668)Сельское хозяйство-(299)Социология-(6455)Спорт-(42831)Строительство-(4793)Торговля-(5050)Транспорт-(2929)Туризм-(1568)Физика-(3942)Философия-(17015)Финансы-(26596)Химия-(22929)Экология-(12095)Экономика-(9961)Электроника-(8441)Электротехника-(4623)Энергетика-(12629)Юриспруденция-(1492)Ядерная техника-(1748)
Алгоритм в широком смысле – это такая последовательность действий, предназначенная для некого исполнителя этих действий, при котором каждое действие понятно исполнителю
Алгоритмы служат для того, чтобы решать определенные задачи.
Например, рецепт приготовления пиццы – это алгоритм для повара. Цель в этом случае – приготовление пиццы. Вид алгоритма зависит от того, для кого он формулируется.
Возьмем последовательность действий, состоящую ровно из одного действия: приготовить пиццу. Является ли это алгоритмом?
Каждое действие этого алгоритма (а оно одно!) понятно опытному повару, который знает, как приготовить пиццу, следовательно, для него эта последовательность действия, состоящая лишь из одного действия, является алгоритмом. Но, например, для меня это не является алгоритмом. Я не знаю как выполнить действие «приготовить пиццу». Для того, чтобы достигнуть цели создать пиццу мне нужен более подробный алгоритм ее приготовления. Например, действия что то взять с чем то перемешать, что то держать под огнем столько то минут, я знаю как и могу выполнить. Следовательно, для меня рецепт приготовления пиццы станет алгоритмом только тогда, когда я буду понимать как делать каждый его пункт.
В математике точное понятия алгоритма вводится через понятие универсальной машины Тьюринга. Которая является моделью практически всех современных ЭВМ. Алгоритм с точки зрения математики – это программа для этой машины. Подробно с математическим понятием алгоритма вы ознакомитесь в курсе «теория алгоритмов». Вообще говоря, это очень серьезная, фундаментальная наука, имеющая огромный практический смысл. Вы, наверное, уже знаете, что классическая физика запрещает создание вечных двигателей. И мы теперь знаем, что вечный двигатель на практике не создать. Теория алгоритмов, например, доказывает существование некоторых алгоритмически неразрешимых задач. Например, там доказано, что нельзя создать программу, которая бы определяла алгоритмическую эквивалентность двух других программ. То есть невозможно в принципе написать, например, на языке Паскаль (или Си или Джава) такую программу, которая бы считывала исходные тексты двух других программ, анализировала их и выдывала, эквивалентны они или нет, то есть дают ли они одинаковые выходные данные над одинаковыми входными. Это не проще, чем создать вечный двигатель. Хотя попытки написать такую программу были. То есть теория алгоритмов нужна, как минимум, затем, чтобы не тратить время на попытки решения принципиально нерешаемых задач. Но все эти вопросы вы будете рассматривать в курсе теории алгоритмов.
Сейчас же вам достаточно такого определения – алгоритм - это последовательность действий компьютера, при котором каждое такое действие он может выполнить.
Какие же действия может выполнять компьютер?
Вообще говоря, компьютер может выполнять лишь некоторые достаточно элементарные операции над числами (так называемые машинные команды или инструкции). И больше ничего он не может. Но оказывается, набора этих примитивных операций более чем достаточно для решения дифференциальных уравнений, обработки графики и многих других задач, которые может выполнять компьютер. Но все они в конечном счете сводятся к некоторым достаточно элементарным действиям над числами. Вообще говоря, у многих людей после знакомства с устройством компьютера возникает удивление, что такие, казалось бы, сложные вещи, которые выполняет компьютер – это, в конечном счете, есть лишь ничто иное как примитивные манипуляции с ноликами и единичками.
Иногда даже складывается впечатление, что компьютер может смоделировать практически все. Но это не так. Компьютер может смоделировать только то, что может быть сведено к последовательности достаточно элементарных действий над числами, то есть только то, что может быть алгоритмизировано. Например, вопрос о том, можно ли сформулировать разум, и тем самым, создать полноценный ИИ до сих пор открыт. Рекомендую на эту тему прочитать монографии Роджера Пенроуза «Новый ум короля» или «Тени разума», где с научной строгостью, но довольно простым языком рассматривается этот вопрос.
Итак, как бы не выглядело в конечном счете то, что делает компьютер – это всего лишь некоторые довольно простые манипуляции с нулями и единичками. Рассмотрению этих простых манипуляций (машинных инструкций) будет посвящена важная часть нашего курса.
На заре компьютерной техники программист, чтобы добиться от компьютера своей цели, формулировал последовательность действий (алгоритм) как раз в терминах этих элементарных операций. Это довольно трудоемко. Поэтому разрабатывались специальные программы (алгоритмы), упрощающие этот процесс. В настоящее время уже мало кто общается с компьютером на его «родном» языке – языке элементарных его операций. 90% пользователей компьютера сейчас вообще даже не догадываются об устройстве и принципах работы компьютера.
Написание программы действий компьютера (программы) на языке его элементарных операций (машинных инструкций) называется низкоуровневым программированием, программированием в машинных кодах или программированием на языке Ассемблер. Вы уже, наверное, имели дело с так называемым высокоуровневым программированием – составление программ (последовательности действий) для компьютера на языках высокого уровня (Паскале, Си, Джава и т.п.). В этом случае Вы пишете программу на этом языке, а переводом Вашей программы на низкоуровневый язык занимается специальная программа – компилятор.
Таким образом, окончательное представление обработки информации есть последовательность команд, каждая из которых задает операцию (действие) и указывает на данные, над которыми это действие нужно провести. То есть аппаратно в любом компьютере должно быть место, где хранится программа и где хранятся данные, с которыми нужно производить действия.
Для работы ЭВМ необходимо хотя бы какое-нибудь минимальное наличие так называемых системных команд, обеспечивающих управление процессами и ресурсами и выполнения функций сервиса с пользователем (хотя бы, дать ему возможность внесения необходимой программы). Таким образом,
ЭВМ – это аппаратурно-программный комплекс, предназначенный для автоматического выполнения действий по преобразованию информации по заданным программам: для ввода (сбора), обработки, хранения и вывода информации.
Большинство современных ЭВМ основаны на принципах, выдвинутых Джоном фон-Нейманом в 1945 г.
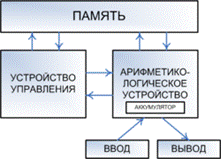
За основную долю работ по обработке информации – вычислительный процесс отвечает центральный процессор, который состоит из УУ и АЛУ.
В основу работы ЭВМ положены следующие принципы:
I. Программное управление работой.
Программы состоят из отдельных шагов – команд (инструкций). То есть программа это последовательность шагов, необходимая для реализации алгоритма.
Этапы цикла выполнения инструкций:
1. Процессор выставляет число, хранящееся в регистре счётчика команд, на шину адреса, и отдаёт памяти команду чтения;
2. Выставленное число является для памяти адресом; память, получив адрес и команду чтения, выставляет содержимое, хранящееся по этому адресу, на шину данных, и сообщает о готовности;
3. Процессор получает число с шины данных в устройство управления (УУ), интерпретирует его как команду (машинную инструкцию) из своей системы команд и исполняет её (для этого, в зависимости от того, что это за команда, ему могут понадобятся данные из регистров или основной памяти, если это так, то процессор инициирует их получение, они помещаются в АЛУ);
4. Если последняя команда не является командой перехода, процессор увеличивает на единицу (в предположении, что длина каждой команды равна единице, если нет, то на длину команды) число, хранящееся в счётчике команд; в результате там образуется адрес следующей команды;
5. Снова выполняется п. 1.
Данный цикл выполняется неизменно, и именно он называется процессом (откуда и произошло название устройства).
Во время процесса процессор считывает последовательность команд (программу), содержащихся в памяти, и исполняет их. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода — тогда адрес следующей команды может оказаться другим. Условный переход позволил легко организовать в программе циклы, итерационные процессы и т.п. Другим примером изменения процесса может служить случай получения команды останова или переключение в режим обработки аппаратного прерывания.
Команды центрального процессора (инструкции) являются самым нижним уровнем управления компьютером, поэтому выполнение каждой команды неизбежно и безусловно. Не производится никакой проверки на допустимость выполняемых действий, в частности, не проверяется возможная потеря ценных данных. Чтобы компьютер выполнял только допустимые действия, команды должны быть соответствующим образом организованы в виде необходимой программы. Это задача программиста.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора. Частота тактовых импульсов называется тактовой частотой.
До фон-Неймана для программирования ЭВМ использовались различные рычаги и переключатели. Для того чтобы лучше понять важность этого принципа представьте, что для того, чтобы, например, поменять местами значения переменных в программе, вам нужно было бы, к примеру, нажать на «педаль» у системного блока.
II. Принцип хранимой программы. Согласно этому принципу программа хранится вместе с исходными данными в одной и той же оперативной памяти.
Это открывает возможность изменять программу прямо в процессе ее выполнения, в зависимости от промежуточных результатов, что позволяет реализовывать более «изощренные» алгоритмы. Также этот принцип обеспечивает одинаковое время выборки команд и данных из памяти (ведь они физически хранятся в одной и той же оперативной памяти, но, естественно в различных ее местах), вводить непрямые системы адресации (возможность работы с памятью произвольно большой емкости, не увеличивая длину машинного слова).
2. Использование двоичной системы счисления для представления информации.
Этот принцип существенно расширил номенклатуру физических приборов для применения в ЭВМ. В самом деле, всего две цифры, поэтому для представления информации может быть использована любая система с двумя стабильными состояниями. Например, напряжение (высокий уровень и низкий). Как вы можете убедится, всего двух состояний достаточно для кодирования практически любой информации.
3. Иерархичность запоминающих устройств (ЗУ).
С самого начала развития ЭВМ существовало несоответствие между быстродействиями АЛУ и оперативной памятью. Делать большую быстродействующую память – сложно и дорого. Делать медленную память – неэффективно. Процессор будет простаивать, пока из памяти выберется нужное число. Иерархичное ЗУ является компромиссом и позволяет использовать очень быструю, но маленькую память (только для операндов и команд участвующих в операции в данный момент и в ближайшее время) – Кеш и оперативная память. А также относительно медленную, за то довольно большую память на внешних ЗУ – жестких и магнитных, компакт-дисках и т.п.
Эти принципы, несмотря на свою простоту и очевидность определили на многие годы бурное развитие вычислительной техники.
Лекция 2.
Под архитектурой ЭВМ понимают ее внутреннюю организацию, состав различных ее устройств, логику их работы и их взаимодействие. Уровень детализации сведений об архитектуре может быть разным и зависит от категории пользователей ЭВМ. Лицам, использующим ЭВМ как игровой автомат, нужен небольшой объем сведений о своем компьютере – частота процессора, объем оперативной и дисковой памяти, марка видеоадаптера и т.п. Системному программисту, конечно, понадобятся более детальные сведения об архитектуре ЭВМ. Чем более детальные представления имеет пользователь об архитектуре ЭВМ, тем более эффективно он может использовать ее возможности. Глубокие знания архитектуры ЭВМ нужны не только инженеру-схемотехнику, проектирующему ее блоки, или системному программисту, разрабатывающему программное обеспечение для взаимодействия этих блоков, но и любому более-менее серьезному пользователю ЭВМ.
Классификация архитектур ВС на основе потоков команд и данных была предложена в 1966 г. Профессором Стэнфорда М.Д. Флинном. В соответствии с ней выделяют четыре типа архитектур:
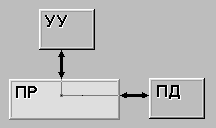
1. SISD (Single Instruction stream Single Data stream) или ОКОД
Схема функционирования проста:
Поток команд, идущих их памяти в процессор порождает поток данных, идущих в том же направлении (для их обработки) и поток данных результатов из процессора (после обработки).
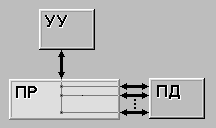
2. SIMD
Архитектура предполагает один поток команд, каждая из которых может совершать операцию одновременно над многими данными (Так называемые векторные команды). Например, многопроцессорные вычислительные системы, состоящие из многих процессорных элементов, каждый из которых имеет свою локальную память. УУ в этом случае выбирает последовательно команды, которые выполняют все процессоры над данными, которые они берут каждый из своей локальной памяти.
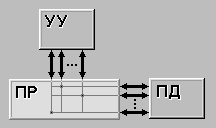
3. MIMD
Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Чаще всего под MIMD-системами подразумевают установки, предназначенные для решения одной большой задачи, разбитой на более менее независимые части. К такой архитектуре могут быть отнесены многие суперкомпьютеры, распределенные вычислительные сети.
4. MISD
Многопроцессорная архитектура, объединяющая множество процессоров с общей памятью. Многие специалисты считают, что этот класс пуст, потому, что в MIMD системах каждый процессор должен имеет доступ не только к собственной локальной памяти, но и к локальной памяти остальных процессоров системы, то есть мы можем рассматривать совокупность всех локальных ЗУ как общую память, то есть класс MIMD включает в себя и MISD. Однако так, называемая, конвейерная архитектура больше соответствует именно этому классу.
В нашем курсе важным является разделение вычислительных устройств на вычислительные машины и вычислительные системы. Под вычислительной машиной мы будем понимать техническое устройство, которое практически в чистом виде реализует архитектуру фон-Неймана, то есть модель вычислителя, осуществляющего последовательное выполнение некоторого алгоритма. Под вычислительной системой мы будем понимать комплекс ЭВМ, специальным образом организованный аппаратно и программно, что позволяет ему существенно повысить производительность. Вычислительные системы обязательно предполагают возможность непоследовательной (параллельной) организации выполнения команд. Иногда такие архитектуры называют не-фон-неймановскими, однако это не вполне правильно. Алгоритмически фон-неймановские и не-фон-неймановские архитектуры эквивалентны в том смысле, что каждую вычислительную задачу, которую можно решить на одной архитектуре, можно решить и на другой. Разница лишь в организации вычислений, быстродействии.
Если ЭВМ представляет собой довольно простую (сравнительно) техническую реализацию универсальной машины Тьюринга, то вычислительная система включает в себя комплекс технических достижений, позволяющий существенно повысить быстродействие ЭВМ.
Лекция 3.
Центральным устройством ЭВМ является микропроцессор. Он управляет работой всех остальных ее блоков, а также осуществляет арифметические и логические операции над числами.
Современные ЦП, выполняемые в виде отдельных микросхем (чипов), называют также микропроцессорами. Сейчас не микропроцессорных ЦП практически не осталось, поэтом ЦП и микропроцессор сейчас почти одно и тоже. Исключения составляют суперкомпьютеры, но о них речь пойдет позже.
В состав микропроцессора входят следующие компоненты:
Генератор тактовых импульсов – генерирует последовательность электрических импульсов, частота которых определяет тактовую частоту микропроцессора. Промежуток времени между соседними импульсами определяет время одного такта, или просто такт работы машины. Каждая операция в ЭВМ выполняется за определенное количество тактов.
Устройство управления (УУ) – формирует и подает во все блоки ЭВМ в нужные моменты времени определенные сигналы управления (управляющие импульсы): формирует адреса ячеек памяти, используемых в текущей операции, и передает эти адреса в соответствующие блоки компьютера. Опорную последовательность импульсов УУ получает от генератора тактовых импульсов.
Арифметико-логическое устройство (АЛУ) – выполняет все арифметические и логические операции над данными.
Микропроцессорная память (МПП) – предназначена для кратковременного хранения, записи и выдачи информации, непосредственно используемой в ближайшие такты работы ЭВМ. ММП строится на регистрах. Регистры – быстродействующие ячейки памяти различной длины.
Интерфейсная система МП предназначена для сопряжения и связи с другими устройствами ЭВМ. Включает в себя внутренний интерфейс МП, схемы управления портами ввода-вывода и системной шиной.
Интерфейс – совокупность средств связи устройств компьютера, обеспечивающая их эффективное взаимодействие.
Порты ввода-вывода – это элементы интерфейса ЭВМ, через которые ММП обменивается информацией с другими устройствами.
Под архитектурой МП мы будем понимать его программную модель, то есть программно-видимые свойства.
Под микроархитектурой МП понимается внутренняя реализация этой программной модели. Для одной и той же архитектуры применяются различные микроархитектурные реализации.
Сейчас существует множество архитектур процессоров, которые можно разделить на две категории RISC и CISC:
RISC (Reduced Instruction Set Computer) – МП с сокращенной системой команд. Имеется набор однородных регистров универсального назначения. Система команд отличается простотой, коды инструкций имеют четкую структуру. В результате чего аппаратная реализация такой архитектуры позволяет с небольшими затратами декодировать и исполнять эти инструкции за минимальное (в пределе 1) число тактов. При необходимости выполнения более сложных программ в МП производится их сборка из более простых.
Такую архитектуру имеют, например, процессоры PowerPC (которые используются, в частности в ЭВМ типа Macintosh).
CISC (Complete Instruction Set Computer) – МП с полным набором инструкций. Состав и назначение регистров существенно неоднородны, широкий набор команд, что усложняет декодирование инструкций, на что расходуется аппаратные ресурсы. Возрастает число тактов, необходимых для выполнения инструкций.
К этой архитектуре относятся популярные среди ПЭВМ процессоры x86, которые являются основой семейства компьютеров IBM PC.
Эти процессоры имеют самую сложную в мире систему команд. Насколько это хорошо или плохо – вопрос спорный. Так получилось, что первые процессоры этого семейства (8086 и 8088) имели именно CISC архитектуру и для совместимости с уже написанным для IBM PC ПО, следующие процессоры также ее поддерживали. Однако в процессорах этого семейства, начиная с 486, применяется комбинированная архитектура: CISC-процессор имеет RISC-ядро. То есть на уровне программной модели эти процессоры представляют собой CISC архитектуру, а микроархитектура этих процессоров близка к RISC. Такая организация, с одной стороны, позволяет сохранить совместимость с нижними моделями семейства, а с другой, позволяет использовать преимущества быстродействия RISC архитектуры. Физически это выглядит так: сложные CISC-инструкции, задаваемые программистом, разбиваются сначала на последовательности более простых RISC-микроинструкции, которые и исполняются микропроцессором.
Архитектура IA-32.
Эту архитектуру поддерживают 32-разрядные процессоры семейства x86, начиная с Intel386. Она полностью совместима с предшествующей 16-разрядной архитектурой процессоров 8086\88 и 80286.
Процессор имеет возможность работы в одном из двух режимов, различающихся, в основном, способом взаимодействия с оперативной памятью:
1. Real Address mode (Режим реальной адресации или реальном режим), полностью совместимом с 8086. В этом режиме возможна адресация до 1 Мбайта физической памяти (шина адреса в 16-битных процессорах этой архитектуры была 20-битной).
2. Protected Virtual Address Mode (защищенный режим виртуальной адресации или просто защищенный режим). В этом режиме МП позволяет адресовать до 4Гбайт физической памяти. Помимо этого предусмотрены аппаратные средства (блок управления памятью), которые позволяют отображать на эти 4ГБайта до 64Тбайт виртуальной памяти.
Одним из вариантов работы защищенного режима является Virtual 8086 Mode – режим виртуального процессора 8086. В этом режиме псевдопараллельно может выполняться несколько программ, как будто у нас имеется несколько процессоров, каждый из которых работает со своей оперативной памятью и решает свою задачу. Попытки выполнения «чужих» команд, выход за рамки «своей» памяти контролируется системой защиты.
Другим вариантом работы защищенного режима является так называемый неофициальный режим Big Real Mode, который позволяет адресоваться ко всему 4Гб пространству памяти одной программе. То есть получается как будто реальный режим, но с возможностью доступа ко всему пространству памяти.
Начиная с процессоров 486 процессор поддерживает особый системный режим работы System Management Mode (SMM), при котором процессор использует иное, изолированное от всех других режимов, пространство памяти. Этот режим используется в служебных и отладочных целях.
Особенности представления информации:
Числовая информация кодируется в двоичной или двоично-десятичной системах счисления. Для кодирования буквенной и символьной информации и при вводе-выводе информации используются специальные коды представления информации – коды ASCII.
Целочисленные блоки АЛУ 32-рарзядных процессоров х86 могут работать со следующими форматами данных:
Бит (Bit) – единица информации.
Битовое поле (Bit Field) – последовательность до 32 смежных бит
Битовая строка (Bit String) – последовательность до 4 Гбит смежных бит
Байт – 8 бит.
Биты в байте нумеруются справа налево, начиная с нулевого разряда.
Числа без знака:
Байт\слово\двойное слово\учетверенное слово (Unsigned Byte/Word/Double Word/Quad Word), соответственно 8\16\32\64 бит
Целые числа со знаком:
Байт\слово\двойное слово\учетверенное слово (Integer Byte/Word/Double Word/Quad Word), соответственно 8\16\32\64 бит
Единичное значение старшего бита является признаком отрицательного числа, которое хранится в дополнительном коде.
Двоично-десятичные числа (BCD – Binary Coded Decimal)
8 – разрядные упакованные (Packet BCD)
Кодируют два десятичных разряда в одном байте
8 – разрядные неупакованные (Unpacked BCD)
Кодируют один десятичный разряд в одном байте (биты 4-7 должны быть пустыми для операций умножения\деления)
Указатели:
Длинный указатель (48 бит) – 16 битный сегмент и 32 битное смещение;
Короткий указатель – 32 битное смещение;
Указатель (32 бит) – 16 битный сегмент и 16 битное смещение.
Блоки FPU работают со следующими данными:.
Двоичные числа с плавающей запятой:
Одинарной точности (Single Precision) – 32 бит: 23 бит мантисса, 8 бит порядок, 1 бит знак.
двойной точности (Double Precision) – 64 бит: 52 мантисса, 11 порядок, 1 знак
повышенной точности (Extended Precision) – 80 бит: 64 мантисса, 15 порядок, 1 знак.
BCD-числа переменной длинны:
Упакованный:
Каждый десятичный разряд числа занимает 4 бита (полубайт), знак числа кодируется в крайнем правом полубайте (1100 – «+», 1101 – «-») (или оба полубайта используются для кодирования цифр десятичного разряда)
Неупакованный:
Для каждого десятичного разряда отводится по целому байту, при этом старшая его часть заполняется кодом 0011. Старший полубайт самого правого байта используется для кодирования знака числа.
Различные блоки расширения, такие как MMX, SSE и т.п. имеют некоторые свои форматы данных.
Лекция 4.
Регистры процессора.
Регистры процессора — сверхбыстрая память внутри процессора, предназначенная прежде всего для хранения промежуточных результатов вычисления (регистр общего назначения/регистр данных) или содержащая данные, необходимые для работы процессора — смещения базовых таблиц, уровни доступа и т. д. (специальные регистры).
Доступ к значениям, хранящимся в регистрах как правило в несколько раз быстрее чем доступ к ячейкам оперативной памяти (даже если кеш-память содержит нужные данные), но объем оперативной памяти намного превосходит суммарный объем регистров (объем среднего модуля оперативной памяти сегодня составляет 512 Мб - 1 Гб[1], суммарная «ёмкость» регистров общего назначения/данных для процессора Intel 80x86 16 битов * 4 = 64 бита (8 байтов)).
Регистры процессоров x86 подразделяются на следующие категории:
1. Регистры общего назначения.
Обозначаются буквами А, В, С, D. 16-битные регистры обозначаются как AX, BX, CX, DX, при этом младшие их байты обозначаются, соответственно AL, BL, CL, DL, а старшие как AH, BH, CH, DH. В процессорах IA-32 эти регистры расширены до 32 бит, и для обозначения 32-битных регистров используется приставка E, например, EAX, EBX, ECX, EDX. Отсутствие приставки означает обращение к младшим 16-битам этих расширенных регистров.
Каждый из этих регистров может использоваться для временного хранения любых данных. Однако принято их использовать для следующих целей:
Регистр EAX/AX/AH/AL (Accumulator register) – регистр-аккумулятор. Применяется для хранения промежуточных данных. В некоторых командах использование этого регистра обязательно.
Регистр EBX/BX/BH/BL (Base register) – применяется для хранения базового адреса некоторого объекта в памяти, например, адреса первого элемента массива.
Регистр EСX/СX/СH/СL (Base register) – регистр-счетчик. Используется как счетчик числа повторений при циклических операциях. Некоторые команды (например, LOOP) изменяют неявно значение этого регистра.
Регистр EDX/DX/DH/DL (Data register) – регистр данных. Также как и регистр EAX/AX/AH/AL хранит промежуточные данные.
2. Сегментные регистры.
Существование этих регистров обусловлено спецификой и организацией использования оперативной памяти. Подробнее с особенностями этой организации мы познакомимся позднее. Сейчас нам важно лишь то, что пространство оперативной памяти логически разбивается на сегменты. Вот для того, чтобы указать на сегменты, к которым программа имеет доступ в конкретный момент времени, и предназначены сегментные регистры. Фактически, с небольшой поправкой (которую мы сделаем позже), в этих регистрах содержатся адреса памяти, с которых начинаются соответствующие сегменты. МП поддерживает следующие типы сегментов:
Сегмент кода. В этом сегменте содержатся команды (инструкции) программы. На начальный адрес этого сегмента указывает 16-ти битный сегментный регистр кода CS (Code segment register).
Сегмент данных. Содержит обрабатываемые программой данные (операнды). На начальный адрес этого сегмента указывает 16-битный сегментный регистр данных DS (Data segment register).
Сегмент стека. Этот сегмент представляет собой специально организованную область памяти, называемую стеком. Принцип действия этой памяти – LIFO – последний пришел, первый вышел. На начальный адрес этого сегмента указывает (16-ти битный) сегментный регистр стека SS (Stack segment register).
Дополнительный сегмент данных.
По умолчанию, алгоритмы работы большинства инструкций предполагают, что операнды находятся в сегменте данных. Если программе недостаточно одного сегмента данных, она может использовать еще три дополнительных сегмента данных, но их надо уже указывать явно, с помощью специальных префиксов. Адреса дополнительных сегментов данных должны содержаться в 16-битных регистрах ES, GS, FS.
3. Регистры смещений.
Служат для хранения относительных адресов ячеек памяти внутри соответствующих сегментов (смещений относительно начала сегментов):
EIP/IP (Instruction Pointer) – смещение адреса текущей команды программы;
ESP/SP (Stack Pointer) – регистр указателя стека, указывает на смещение вершины стека (текущего адреса стека);
EPB/BP (Base Pointer) – регистр указателя базы кадра стека. Предназначен для организации произвольного доступа к данным внутри стека.
ESI/SI (Source Index register) – индекс источника. Этот регистр в цепочечных операциях содержит текущий адрес элемента в цепочке-источнике.
EDI/SI (Destination Index register) – индекс приемника. Этот регистр в цепочечных операциях содержит текущий адрес элемента в цепочке-приемнике.
4. Регистр флагов.
В битах этого регистра содержится информация о состоянии как самого МП, так и программы, команды которой в данный момент загружены в МП.
EFLAGS/FLAGS – 32/16 бит. Отдельные биты называются флагами. Младший байт этого регистра полностью аналогичен регистру FLAGS процессора i8086.
Основные флаги:
CF – флаг переноса. (номер бита в EFLAGS – 0). Содержит 1, если арифметическая операция произвела перенос старшего бита результата. Старшим является 7-й, 15-й или 31-й бит в зависимости от размерности операнда.
PF – флаг паритета. (номер бита в EFLAGS – 2). 1 – 8 младших разрядов операнда содержат четное число единиц.
AF – вспомогательный флаг переноса (номер бита в EFLAGS – 4). Только для BCD-чисел. Фиксирует факт заема из младшей тетрады в старшую.
ZF – флаг нуля. (номер бита в EFLAGS – 6). 1 – результат нулевой.
SF – флаг знака (номер бита в EFLAGS – 7). Отражает состояние старшего бита результата. 1- старший бит равен 1.
OF – флаг переполнения (номер бита в EFLAGS – 11). Для фиксирования факта потери значащего бита при арифметической операции.
IOPL – уровень привилегий ввода-вывода. (номер бита в EFLAGS – 12,13) Используется в защищенном режиме работы МП для контроля доступа к командам ввода-вывода, в зависимости от привилегированности задачи.
NT – флаг вложенности задачи. (номер бита в EFLAGS – 14). Используется в защищенном режиме работы для фиксации того факта, что одна задача вложена в другую.
TF – флаг трассировки. (номер бита в EFLAGS – 8). Предназначен для организации пошаговой работы МП.
IF – флаг прерывания.
Помимо этих регистров существуют множество системных регистров, которые мы рассматривать не будем.
Организация памяти.
Пространство памяти и ввода-вывода разделены.
Память представляется в виде линейной последовательности байт. И подразделяется на байты, слова, двойные и учетверенные слова. Слово записывается в двух, двойное слово – в четырех, учетверенное слово – в 8 смежных байтах, начиная с младшего, т.е. младший байт имеет меньший адрес, этот адрес и является адресом слова, двойного слова, учетверенного слова, он может быть как четным, так и нечетным. Все пространство памяти подразделяется на параграфы – области из 16 смежный байт. Существуют понятия выравнивания по границе слова, двойного слова, учетверенного слова, параграфа. Это когда соответственно, младший бит, два младших бита, три младших бита, четыре младших бита имеют нулевые значения. Выровненные элементы передаются по внешним интерфейсам за минимальное число тактов.
Память логически организовывается в виде одного или множества сегментов переменной (для защищенного режима) или постоянной (для реального режима) длины.
В защищенном режиме возможно разделение памяти на страницы, размерами от 4 Кб до 4 Мбайт. На них может отображаться вся доступная оперативная память. Однако это осуществляется на системном уровне, т.е. прозрачно для программиста.
Сегменты и страницы могут выгружаться и подгружаться из оперативной памяти на диск, так реализуется виртуальная память.
Таким образом, можно различать три адресных пространства памяти: логический, линейный и физический. На шину адреса отравляется физический адрес, собственно он и указывает на нужную ячейку памяти.
В реальном режиме линейный адрес и физический совпадают.
Рассмотрим модель памяти в реальном режиме.
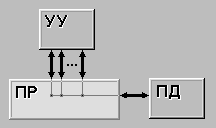
Разрядность шины адреса в реальном режиме – 20 бит. Что дает возможность адресовать 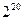 ячеек размером в байт, то есть 1 Мбайт.
ячеек размером в байт, то есть 1 Мбайт.
Вся память разделяется на сегменты, размером в 64 Кбайт.
Физический адрес памяти, поступающий на шину адреса состоит из двух 16-битных частей – адреса сегмента (Seg) и исполнительного (эффективного) адреса EA. Он формируется следующим образом:
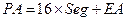
Адрес текущего сегмента хранится в одном из сегментных регистров CS, DS, SS, ES. Сдвигается на 4 бита (умножается на 16) он аппаратно, совершенно прозрачно для программиста.
Эффективный адрес может быть константой, содержимым регистра, или суммой нескольких величин. Но, так как он является 16-битным, то при одном и том же значении сегментного регистра, изменяя эффективный адрес, нельзя выйти за пределы этого сегмента.
В защищенном режиме организация памяти несколько усложняется. По причине, во-первых, более широкой (32 бита) шины адреса, во-вторых, из-за механизмов поддержки виртуальной памяти. Хотя с точки зрения программиста это отличие заключается лишь в том, что эффективный адрес имеет большую размерность (32 бит), а сегментные регистры содержат не адреса сегментов, а некоторые селекторы, преобразующиеся на аппаратном уровне в эти адреса. Сложение этих адресов дает 32-битный линейный адрес, который преобразуется в физический блоком страничной переадресации (если она включена). На шину адреса отравляется физический адрес, собственно он и указывает на нужную ячейку памяти.
Прерывания и исключения.
Как мы уже с вами говорили, компьютер представляет собой средство для реализации алгоритмов. Конкретный алгоритм реализуется с помощью программы. Заданная программа выполняется микропроцессором шаг за шагом, инструкция за инструкцией в соответствии с задающими ГТИ тактами. В некоторых случаях для решения поставленной задачи требуется приостановить в некоторый момент времени ход выполнения программы. Например, чтобы запросить у пользователя некоторые данные или, например, обработать сигнал, поступивший на сетевую карту. Для реализации этой возможности в архитектуру ЭВМ введены прерывания.
Прерывание – это приостановка выполнения программы для выполнения некоторых запланированных или незапланированных действий.
Каждое прерывание влечет за собой загрузку определенной программы – программы обработки прерывания.
В зависимости от источника прерывания можно разделить на:
1. Аппаратные. Возникают как реакция МП на физический сигнал от некоторого устройства компьютера (клавиатура, системный таймер, модем, сетевой адаптер и т.д.). Эти прерывания асинхронны, так как возникают, как правило, независимо от текущей программы, которую выполняет компьютер в данный момент.
2. Программные. Которые вызываются искусственно с помощью команды INT. Эти прерывания являются синхронными. И логически они ничего не прерывают в том смысле, что их можно рассматривать как команду внутри программы.
К программным прерываниям также относятся так называемые исключения – это реакция МП на нестандартную ситуацию, например, при делении на ноль.
Механизм работы аппаратных прерываний в реальном режиме следующий:
При генерировании устройством запроса на прерывание (например, при нажатии кнопки клавиатуры), соответствующий запрос попадает на специальную микросхему – программируемый контроллер прерываний (ПКП). Этот контроллер имеет восьмибитный регистр прерываний IRR, каждый бит которого связан с одним или несколькими внешними устройствами и обозначается как IRQ0-IRQ7. То есть ПКП может обслуживать только восемь устройств. Этого явно мало, поэтому используют, как правило, две последовательно соединенные микросхемы ПКП. Допустим, в нашем случае сигнал прерывания поступает на вход IRQ0. Младший бит регистра прерываний IRR при этом становится равным 1. Регистр IRR связан с управляемым регистром IMR, который позволяет маскировать (запрещать) прерывания. Если прерывание разрешено (незамаскировано), оно поступает к арбитру приоритетов, основная функция которого – определение, какому прерыванию пойти к процессору раньше, при одновременном обращении нескольких прерываний. Обычно, самым приоритетным является прерывание IRQ0. Если конфликта нет, то формируется сигнал на выходе INT ПКП. Этот выход связан со входом INTR МП. При появлении сигнала на своем входе INTR, МП анализирует состояние флага IF. Если его значение «0» (аппаратные прерывания запрещены), то запрос на прерывание «повисает», то есть МП не будет его обрабатывать, до тех пор, пока флаг IF не станет равным «1». Если же прерывания разрешены, МП делает следующие действия:
1. Сбрасывает флаг IF в ноль.
2. Формирует сигнал подтверждения прерывания на своем выводе INTA. Этот вывод связан с одноименным входом ПКП.
3. Сохраняет в стековой памяти текущий контекст выполнения программы (всю необходимую информацию о текущей выполняемой программе с тем, чтобы потом вернуться к ее выполнению).
При поступлении этого сигнала ПКП производит следующие действия:
1. Сбрасывает соответствующий бит в регистре IRR (в нашем случае нулевой бит IRQ0).
2. Устанавливает 1 соответствующий бит (в нашем случае нулевой) своего регистра состояния ISR. Этим фиксируется факт обработки готовности процессором обработать соответствующее (нулевое в нашем случае) прерывание.
3. Формирует номер вектора прерывания (указатель на то место в памяти, где хранится программа обработки соответствующего, в нашем примере, нулевого, прерывания), и помещает его на свои выводы, которые соединены с шиной данных МП.
Процессор, зная где лежит программа по обработке прерывания, запускает ее. Если во время этой обработки поступит еще один сигнал прерывания, то, в зависимости от состояния флага IF и от приоритета вновь поступившего прерывания, процессор либо «подвесит» его, либо прервет выполнение текущего обработчика и начнет обработку этого нового прерывания, предварительно, конечно, сохранив контекст программы текущей обработки.
Важный момент связан с тем, что с началом обработки любого прерывания, как мы уже говорил, МП сбрасывает значение флага IF. То есть, если в программе обработки аппаратного прерывания этот флаг вручную не поднять, то никакие аппаратные прерывания, идущие от ПКП не будут обслуживаться, пока не завершится текущая обработка. В частности, также будут теряться такты по уровню IRQ0, идущие от системного таймера несколько раз в секунду, и служащие для счета времени. И компьютерные часы будут отставать. Поэтому рекомендуется в обработчики любых прерываний как можно раньше вставлять команду STI, разрешающая аппаратные прерывания (устанавливающая флаг IF в единицу).
Помимо рассмотренных аппаратных прерываний в МП через ПКП, существуют также аппаратные технические прерывания, которые подаются прямо на вход МП NMI и всегда обслуживаются.
Ассемблер.
Ассемблер – это язык программирования низкого уровня. Представляет собой, символически-удобный аналог машинного языка.
Для перевода программы, написанной на ассемблере, в машинные коды существуют программы – трансляторы (компиляторы).
Достоинства:
1. Максимально оптимальное использование средств процессора, использование меньшего количества команд и обращений в память, и как следствие — большая скорость и меньший размер программы
2. Использование расширеных наборов инструкций процессора (ММХ, SSE, SSE2, SSE3)
3. Доступ к портам ввода-вывода и особым регистрам процессора (в большинстве ОС эта возможность доступна только на уровне модулей ядра и драйверов)
4. Возможность использования самомодифицирующегося (в том числе перемещаемого) кода.
Недостатки:
1. Большие объемы кода, большое число дополнительных мелких задач, меньшее количество доступных для использования библиотек, по сравнению с языками высокого уровня
2. Трудоёмкость чтения и поиска ошибок (хотя здесь многое зависит от комментариев и стиля программирования)
3. Непереносимость на другие платформы, кроме архитектурно совместимых.
4. Более сложен для совместных проектов
Области применения:
1. Разработка программ, критичных к быстродействию (например, драйверов устройств).
2. Возможность просмотра и корректировки исполняемых программ (с расширениями, EXE и COM, например), при отсутствии их исходного кода.
Структура программы на ассемблере.
Программа на ассемблере представляет собой описание соответствующих сегментов памяти.
Ассемблер позволяет тонко настроить каждый сегмент (данных, кода, стека): указать тип выравнивания, комбинирования, размер (64 Кбайт в реальном режиме, или до 4 Гб в защищенном). Для некоторых типичных ситуаций приняты так называемые модели памяти, чтобы программист не настраивал их подробно в каждой программе. Подробную настройку следует проводить лишь в тех случаях, когда стандартные модели памяти не удовлетворяют. Мы будем использовать модель памяти SMALL, в котором код программы размещается в одном сегменте кода, а данные объединены в одну группу.
В этом случае структура ассемблерной программы имеет следующий вид:
MODEL SMALL
.DATA
--здесь описывается сегмент данных
.STACK
--здесь описывается сегмент стека
.CODE
MAIN PROC
--здесь представлен исходный код процедуры PROC
MAIN ENDP
ENDMAIN
Каждый сегмент состоит из предложений языка, каждое из которых занимает отдельную строку кода программы.
Предложения бывают следующих типов:
Команды (инструкции) – символические аналоги машинных команд. В процессе трансляции они преобразуются в машинные команды.
Формат команды
[метка [:]] КОП [Операнд] [,Операнд] [;Комментарий]
КОП – мнемокод команды (состоит из 2-6 букв). В 8088 133 кода, в 80386 – 240.
Операнд – в качестве него может быть явно заданный адрес (прямой или косвенный); имя метки, имя переменной, само значение переменной и т.п.
Количество необходимых операндов в данной команде, МП узнает по КОП.
Метка – имя команды ассемблера для ссылки к этой команде. Метка находится всегда в текущем сегменте памяти.
Директивы – некоторые указания транслятору.
Формат директивы:
[Идентификатр] КПОП [Операнд] [, Оеранд] … [;Комментарий]
Идентификатор – имя директивы
КПОП – мнемокод директивы.
Операнды – различные опции директивы.
Особенности представления чисел:
Двоичные числа заканчиваются буквой B.
Десятичные числа без окончания, либо заканчивающиеся буквой D.
Шестнадцатеричные числа заканчиваются буквой H. Всегда должны начинаться с десятичной цифры, а не буквы!
Отрицательные десятичные числа записываются обычным образом
Двоичные и шестнадцатеричные числа записываются в дополнительном коде.
Строки символов представляет собой последовательность любых символов, заключенных в кавычки.
Модификаторы
В качестве операндов могут быть использованы модификаторы, которые определяют некоторые операции, которые выполняются при трансляции команды.
Арифметические: «+» «-«, «*», «/», mod и т.п. Формат: oprd mdf oprd
Логические: and, or, not, xor. Формат: oprd mdf oprd
Отношения: eq – совпадения, nq – несовпадения, it – меньше, gt- больше, le – меньше или равно, ge – больше или равно. Формат: oprd mdf oprd.
Функции: $ - счетчик адреса, возвращает смещение текущей команды относительно сегмента кода;
seg – возвращает сегмент (его адрес) операнда;
offset – возвращает смещение операнда;
length – возвращает длину операнда;
type – возвращает тип операнда (1 – если байт, 3 – dword)
size – возвращает произведение length*type операнда
Формат везде (кроме $) mdf oprnd
Присваивания атрибутов:
ptr – изменяет тип операнда. Формат: type ptr oprnd
ds: es: CS: SS: - изменяет адрес сегмента.
HIGH/LOW – возвращает старший/младший байт 16-битового операнда.
Описание сегмента данных
В этом сегменте программист определяет данные, которые будут использоваться в программе. По-сути, здесь программист определяет переменные. Это осуществляется посредством специальных директив, с помощью которых транслятор выделяет необходимое количество памяти. Эти директивы имеют следующий формат:
[имя] КС выражение
Имя – имя переменной (константы, или поля данных). Фактически, это имя будет указывать на адрес байта в памяти, где будет храниться первый байт этой переменной.
КС – ключевые слова, могут быть: DB (1), DW(2), DD(4), DQ(8), DT(10)
Выражение показывает, сколько экземпляров данных соответствующего типа содержится в этой переменной (константе или поле), а также какие данные там могут находиться.
Например:
PEREM1 DW 56 – под переменную с именем PEREM1 зарезервировать 2 байта памяти и присвоить ей начальное значение 56.
MASSIV DB 10 DUP (‘ ‘) – под переменную с именем MASSIV зарезервировать 10 байт памяти по одному байту и заполнить их символом пробела.
POLE DB 5 DUP (?) – под переменную с именем POLE зарезервировать 5 байт памяти по одному байту, и не присваивать ей никаких начальных значений.
MESSAGE DB ‘Вами неправильно набран номер $’ – определена строка со значением «Вами неправильно набран номер». Стока может содержать до 255 символов, использование в качестве КС DB и наличие счетчика адреса обязательны.
ADDR DW PEREM1 – переменной ADDR выделить 2 байта памяти и присвоить ей адрес (эффективный) ранее созданной переменной PEREM1.
Способы адресации памяти.
Рассмотрим на примере команды MOV
Непосредственная адресация.
Величина операнда непосредственно указывается в команде и может быть задана числом в различных системах счисления. Допускается использование модификаторов.
Примеры:
MOV AX, 10FH; MOV BX, 10H/2
Прямая адресация регистров.
В качестве адреса операнда указывается имя регистра
MOV AX, BX; MOV DX, BX
Адресация ячеек ОП.
Прямая
В качестве адреса ячейки указывается имя переменной (фактически оно означает ее эффективный адрес)
MOV AX, PEREM – передать в AX содержимое переменной PEREM
Косвенная базовая адресация
Эффективный адрес нужной ячейки содержится в одном из регистров.
MOV AX, [CX] – передать в AX содержимое ячейки памяти, адрес которой находится в CX
Косвенная базовая адресация со смещением
Эффективный адрес нужной ячейки вычисляется как сумма базы и смещения.
MOV AX, PEREM[BX] – передать в AX содержимое ячейки памяти, расположенной на BX байт дальше, чем PEREM
MOV AX, [CX+3] – передать в AX содержимое ячейки памяти, имеющей эффективный адрес CX+3
Косвенная индексная адресация со смещением
Аналогично предыдущей, но возможно масштабирование смещения
MOV AX, PEREM[SI*2] - передать в AX содержимое ячейки памяти, расположенной на SI*2 байт дальше (или на SI слов дальше), чем PEREM
Косвенная базовая индексная адресация
MOV AX, [SI][DX] – поместить в AX содержимое ячейки памяти, эффективный адрес которой равен SI+DX
Косвенная базовая индексная адресация со смещением
MOV PEREM[SI+5][DX] - передать в AX содержимое ячейки памяти, расположенной на SI+5+DX байт дальше, чем PEREM
Основные команды
Команды пересылки данных
MOV dist, src – переслать (скопировать) данные из src в dist
Флаги не меняет.
PUSH src – занести в вершину стека слово из src (из регистра или 2-х ячеек памяти)
POP dst – извлечь из вершины стека слово и поместить его в dst (в регистр или 2 ячейки памяти)
Арифметические команды
ADD dst, src – сложение двоичных чисел. dst = dst + src
dst = r,m
src = r,m,i но нельзя использовать сегментные регистры и одновременно m
Влияет на флаги AF, CF, OF, PF, SF, ZF
SUB dst, src – вычитание двоичных чисел
dst = dst - src
dst = r,m
src = r,m,i но нельзя использовать сегментные регистры и одновременно m
Влияет на флаги AF, CF, OF, PF, SF, ZF
CMP dst, src – сравнить dst с src. Аналогично SUB, но содержимое dst не изменяется.
Флаги CF ZF используются для сравнения чисел без знака, CF, OF, SF, ZF – со знаком.
Команды приращения
INC dst – прибавить 1 к содержимому dst = dst +1
dst = r или m
Влияет на флаги PF, AF, ZF, SF, OF
DEC dst – вычесть 1 из содержимоого dst = dst +1
dst = r или m
Влияет на флаги PF, AF, ZF, SF, OF
Команды умножения
MUL src – умножение беззнаковых чисел.
src = r или m
Если src – байт, то второй множитель будет в AL а результат в AX. Если src – слово, то второй множитель будет в AX, а произведение в DX:AX
Формирует флаги CF, OF
IMUL src – умножение знаковых чисел.
src = r или m
Если src – байт, то второй множитель будет в AL а результат в AX. Если src – слово, то второй множитель будет в AX, а произведение в DX:AX
Формирует флаги CF, OF
Команды деления
DIV src – деление беззнаковых чисел.
src = r или m
Если src – байт, то делимое (слово) будет в AX, частное в AL, а остаток в AH Если src – слово, то второй множитель (двойное слово) будет в DX:AX, частное в AX, а остаток в DL.
Формирует флаг IF
IDIV src – деление знаковых чисел.
src = r или m
Если src – байт, то делимое (слово) будет в AX, частное в AL, а остаток в AH Если src – слово, то второй множитель (двойное слово) будет в DX:AX, частное в AX, а остаток в DL.
Формирует флаг IF
Команды безусловного перехода
JMP opr – перейти на opr
opr может быть: меткой, регистром, содержимым ячейки памяти.
Если метка в том же сегменте памяти, то переход считается внутренним, если в другом сегменте – внешним.
В зависимости от дальности команд с которой и на которую надо перейти, команда JMP имеет различный размер. Команда внутреннего перехода занимает три байта (один байт – код команды и два байта – под смещение относительно сегмента кода той команды, куда нужно перейти). Однако команду JMP можно сократить до двух байт – отведя лишь один байт для информации о том, куда можно прейти. Осуществляется это с помощью префикса SHORT
В адресном байте команды в этом случае хранится число от -128 до +127 – оно указывает на относительное смещение той команды, куда нужно осуществить переход относительно текущей команды. То есть с помощью этой конструкции можно «прыгнуть» всего на 35-40 команд вперед-назад. Но зато и размер команды на один байт меньше.
То есть
JMP SHORT метка
Однако, если осуществляется переход назад и длина перехода укладывается в 128 байт, то транслятор автоматически уменьшает размер команды JMP, даже без префикса SHORT.
Команда внешнего, межсегментного перехода занимает 5 байтов (два байта под сегмент и два под смещение относительно этого сегмента).
Процедуры
Процедуры обрамляются следующими операторами:
Имя процедуры PROC [расстояние]
; тело процедуры
RET [число байтов]
Имя процедуры ENDP
Расстояние: NEAR – процедура находится в том же сегменте кода, FAR – в другом сегменте кода. Если расстояние опущено, то предполагается near.
RET – возврат управления вызвавшей процедуру программе. Она считывает адрес возврата из стека и загружает его в регистры CS и IP (если процедура NEAR, то только IP). Число байт указывает, сколько байтов нужно освободить в стеке после возврата.
Как обратиться к процедуре? В принципе, можно любой командой перехода, включая и JMP. Однако в случае использования процедур важно запомнить то место в основном программе, откуда была вызвана процедура, с тем, чтобы потом к нему вернутся после завершения процедуры (команды RET в процедуре). Для этих целей используется команда
CALL [модификатор] oprnd
oprnd может быть:
именем процедуры
именем регистра, в котором содержится смещение адреса процедуры
переменной, в которой содержится адрес процедуры.
Процедура может размещаться в любом месте программы, но так, чтобы на нее случайным образом не попало управление. Если процедуру просто вставить в общий поток сегмента кода, то процессор будет выполнять команды процедуры непосредственно при выполнении основной программы. Чтобы этого не произошло можно размещать процедуру следующим образом:
- в начале программы (до первой исполняемой команды);
- в конце программы (после команды, возвращающей управление операционной системе);
- внутри основной программы, предусмотрев обход процедуры с помощью команды безусловного перехода JMP.
Команды условной передачи управления
Условная передача управления может быть только внутрисегментной (NEAR) и короткой (SHORT), то есть в пределах ±128 байт от текущей команды условного перехода.
Алгоритм действия такой:
Сначала выполняется команда, которая соответствующим образом меняет регистр флагов, например команда CMP
Затем выполняется одна из команд условного перехода вида
J* имя метка
Которая при определенной комбинации флагов переводит управление на метку, имя которой указано в ней, либо передает управление на следующую за командой условного перехода команду.
Есть 31 команда, но разных всего 17 (так как некоторые попарно совпадают, например «если больше» все равно, что «если не меньше и не равно»).
Следует различать для знаковых и беззнаковых чисел
Для беззнаковых:
JA/JNBE – переход если выше – если флаги ZF = CF = 0
JAE/JNB – переход если выше или равно CF=0
JB/JNAE – переход если ниже CF=1
JBE/JNA – переход если ниже или равно – если флаги ZF = CF = 1
Для знаковых:
JG/JNLE – переход если больше – если флаги ZF = 0 SF = OF
JGE/JNL – переход если выше или равно SF=OF
JL/JNGE – переход если ниже SF<>OF
JLE/JNG – переход если ниже или равно – если флаги ZF = 1 или SF<>OF
Для прочих проверок:
JE/JZ – переход если равно (или если нуль) ZF=1
JNE/JNZ – переход если не равно (или не нуль) ZF=0
JS – переход, если есть знак (отрицательно) SF=1
JNS – переход, если нет знака (положительно) SF=0
JC – переход, если есть перенос (CF=1)
JNC – переход, если нет переноса (CF=0)
JO – переход, если есть переполнение (OF=1)
JNO – переход, если нет переполнения (OF=0)
JP/JPE – переход, если есть четность PF=1
JNP/JPO – переход, если нет четности PF=0
JCXZ – переход, если содержимое регистра CX равно 0
Команды управления циклами
Количество повторений предварительно записывается в регистр CX
LOOP имя метка
Команда уменьшает содержимое регистра CX на единицу и если значение в регистре становится нулевым – передает управление следующей за ней команде, если же значение CX остается ненулевым – передает управление на метку, имя которой указано. Передачи управления только ближние и короткие.
Команды прерывания
У этих команд есть аналогия с командой CALL, однако начальный адрес обработки прерывания (вектор прерывания) берется из таблицы векторов ОЗУ, он всегда 32битовый (так как хранит и сегмент и смещение), и в стеке сохраняется не только адрес возврата, но и содержимое регистра флагов (то есть весь контекст текущей задачи.
Имеются три команды прерывания:
INT opr
opr указывает номер прерывания (число от 0 до 256), который задает вектор прерывания.
По этой команде процессор выполняет следующие действия:
1. Помещает в стек содержимое регистров: FL, CS, IP
2. Обнуляет флаги TF и IF
3. Загружает в CS и IP второе и первое слова вектора прерываний, считанного из таблицы векторов в оперативной памяти по адресу 4*opr. Таким образом, вся таблица векторов занимает 1024 байта.
Например, INT 1Ah считает из памяти вектор, находящийся по адресу 1Ah*4=68h, то есть в регистр IP будет помещено слово по адресу 68h, а в регистр CS слово, по адресу 6Ah
INTO – прервать по переполнению. Если флаг OF=1, то управление передается по адресу 10h (аналог команды INT 4).
IRET – возврат из программы обработки прерывания. Это последняя команда обработки прерывания. Из стека выталкиваются три последние слова и загружаются в регистры IP, CS и FL. SP увеличивается при этом на 6.
Запоминающие устройства.
Понятно, что чем больший объем памяти доступен процессору, тем лучше. Мы уже с вами говорили, что по техническим и экономическим соображениям, чем больше объем доступной памяти, тем, как правило, медленнее она работает. Поэтому в ВМ память организована иерархично.
Обычно выделяют четыре уровня памяти:
1. Микропроцессорная память (регистры процессора).
2. Кэш-память.
3. Основная память (оперативная и постоянная).
4. Внешняя память (на магнитных и оптических дисках).
Чем выше память находится в этой иерархии тем, как правило, скорость ее работы выше, а объем меньше.
Быстродействие памяти характеризуется скоростью считывания (записи) информации. Важнейшими показателями, влияющими на скорость считывания (записи) являются:
1. Максимальная пропускная способность. Зависит как от самой памяти, так и от ее интерфейса с процессором.
Зависит от разрядности шины, по которой осуществляется связь процессора с памятью, от частоты этой шины и способе передачи информации.
Например, для двухканального контроллер памяти стандарта DDR400:
8 байт (ширина шины) * 2 (количество каналов) * 2 (протокол DDR, обеспечивающий передачу 2 пакетов данных за 1 такт) * 200'000'000 (фактическая частота работы шины памяти равная 200 МГц, то есть 200'000'000 тактов в секунду) = 5,96 ГБ\с.
2. Время доступа (латентность).
Доступ к любому произвольно взятому адресу не может быть осуществлён мгновенно, для этого требуется определённое время. Возникает задержка: микросхема памяти получила нужный процессору адрес, но память ещё не готова предоставить к нему доступ. Эта задержка и называется латентностью.
Латентность особенно принципиальна на верхний в иерархии уровнях памяти.
Память типа DDR2 имеет в среднем гораздо большие задержки, чем DDR (при одинаковой частоте передачи данных).
Физические основы работы внутренней памяти
Различные уровни памяти имеют разную физическую организацию.
1. Энергозависимая память.
1.1. Статическая память.
Ячейки построены на триггерах – элементах, которые при наличии питающего напряжения могут находиться сколь угодно долго в одном из двух своих состояний и скачком переходить из одного в другое. Триггеры технически довольно сложно реализовать, они занимают довольно много места на кристалле.
Используется в качестве микропроцессорной и кэш-памяти. Имеет время доступа в несколько наносекунд, что позволяет ей работать на частоте системной шины процессора, совсем не требуя от него тактов ожидания (или требуя считанное число тактов ожидания)
Самая экономичная статическая память – КМОП (CMOS) (комплиментарная метал-оксидная полупроводниковая) память. Имеет время доступа более 100 нс (это довольно много для статической памяти), однако имеет низкое потребление и может питаться от батарейки. Используется для хранения даты и времени, а также некоторой информации о конфигурации компьютера.
Динамическая память.
Основной метод построения оперативной памяти (RAM –Random Access Memory).
Ячейки представляют собой аналоги конденсаторов, образованных элементами полупроводниковых микросхем. При записи логической «1» конденсатор заряжается, при записи «0» - разряжается. Если к ячейке долго не обращаться, то за счет токов утечки конденсатор разряжается и информация теряется. Поэтому необходима постоянная подзарядка каждой ячейки, отсюда и название памяти – динамическая. Энергию необходимо тратить лишь для подзарядки конденсаторов, поэтому энергопотребление ниже, чем у статической памяти. Физически размер ячейки меньше, поэтому на одном кристалле удается размещать множество ячеек. Однако платой за это все является более сложный механизм работы. Конденсаторы расположены на пересечении горизонтальных и вертикальных шин матрицы. При считывании на микросхему памяти подается адрес строки матрицы, сопровождаемый сигналом RAS (строб адреса строки), затем через некоторое время – адрес столбца, с сигналом (CAS). Стоящий на пересечении этих строк и столбцов конденсатор разряжается через схему считывания, и если заряд был не нулевым – выставляется «1», затем, чтобы информация не потерялась, конденсатор подзаряжается до прежнего уровня.
Основные типы оперативной памяти:
FPM DRAM (Fast Page Mode) – динамическая память с быстрым страничным доступом. После выбора строки матрицы (RAS), он может удерживаться некоторое время, в течение которого может многократно меняться столбец (CAS). То есть если данные находятся внутри одной строки, быстродействие увеличивается. Время доступа 60-70 нс. Используется с МП 80386 и 80486.
RAM EDO (Extended Data Out) – динамическая память расширенного удержания. Удерживается последняя выбранная ячейка, что удобно при последовательном (блочном) считывании данных.
45 нс.
SDRAM (Synchronous DRAM) – память с синхронным доступом. В отличие от рассмотренных выше асинхронных типов памяти, в которых выборка нужной ячейки осуществляется только по сигналам RAS и CAS, память этого типа использует сигнал тактовой частоты системной шины. Это позволяет осуществлять конвейерный принцип работы: одновременно осуществлять считывание (запись) в одну ячейку, с поиском другой. За счет этого удается исключить такты ожидания. Работает, как правило, на частоте системной шины (100, 133 МГц). Но возможна и асинхронная работа по тому же принципу. Время доступа – 5-10 нс
DDR SDRAM (Double Data Rate) – тоже, что и SDRAM, но данные передаются по обоим фронтам (и верхним и нижним) тактового сигнала, что увеличивает максимальную пропускную способность в два раза. Частоты тоже увеличились и составляют 166, 200 (DDR400 или PC3200) МГц.
2. Внутренняя энергонезависимая память.
Хранит записанные данные и при отсутствии питающего напряжения. Основным режимом работы такой памяти является считывание данных. Запись информации, называемая программированием или «прошивкой»,
|
Дата добавления: 2013-12-12; Просмотров: 779; Нарушение авторских прав?; Мы поможем в написании вашей работы!